27 Jul 2026
Major Product Update: Introducing SEOptimer’s GEO Audit
As you know by now, more people are using AI to discover businesses, products and information online...
 Blog
Blog 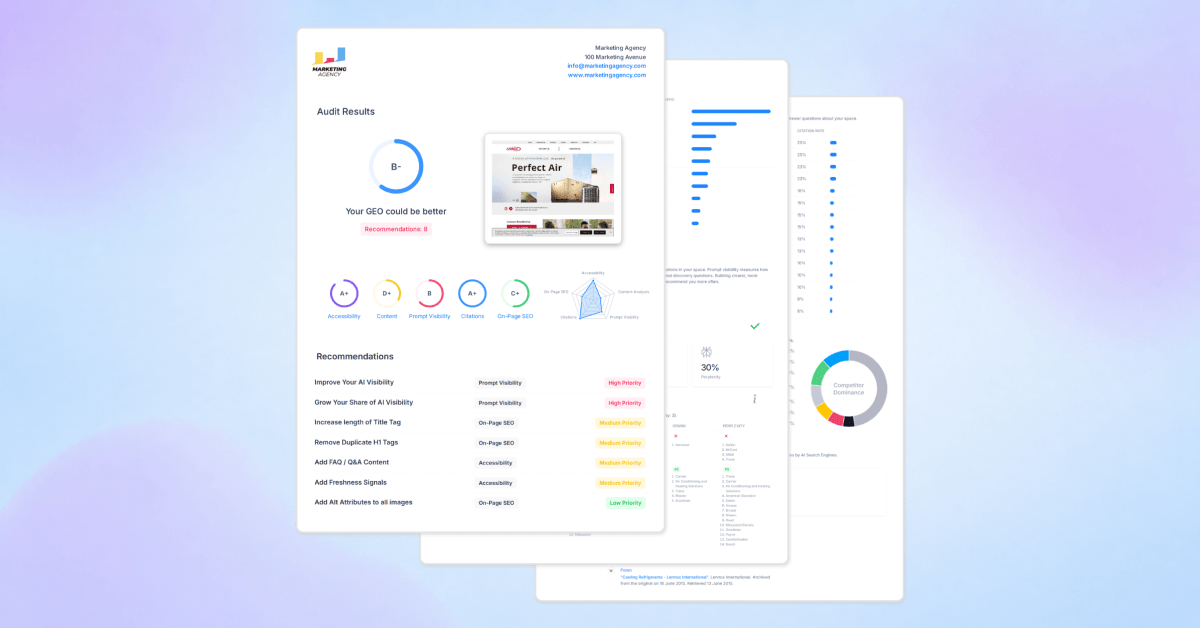
As you know by now, more people are using AI to discover businesses, products and information online...

AI prompt tracking helps you understand which questions and conversations bring up your brand in Cha...

As more people use ChatGPT, Claude, Perplexity, and Google’s AI search features, AI crawlability is...

LLM optimization can help increase the chances of your website being mentioned or cited in answers g...

The best link building services help businesses earn high-quality backlinks without having to manage...

How do you optimize your website for Google’s generative AI search results? Well, the internet has s...

The best link building tools help SEOs to manage the entire link building process. This includes fin...

Getting an SEO client is hard. So you want to ensure that you keep them as long as possible. And thi...

What are the Best Sites for Getting Backlinks? Here are the best sites for getting backlinks tha...

There are several types of backlinks, here’s a list of the most important link types: Dofollow...
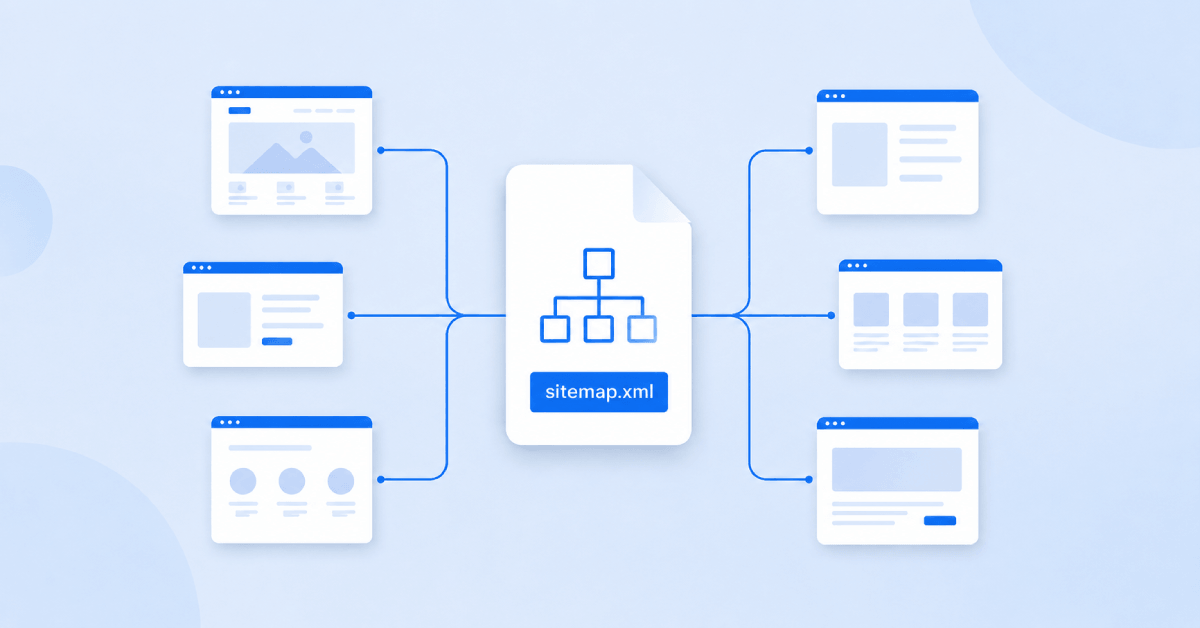
An XML sitemap helps search engines find the most important pages on your website. In this guide...
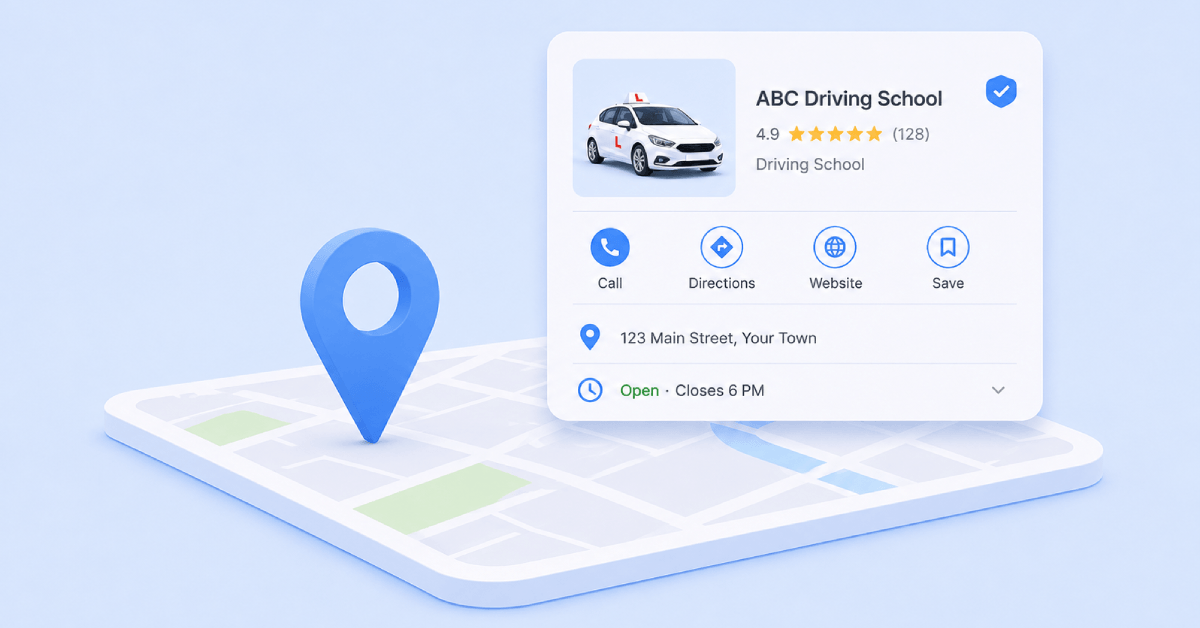
SEO for driving schools is about making sure new learners can find you at the exact moment they star...