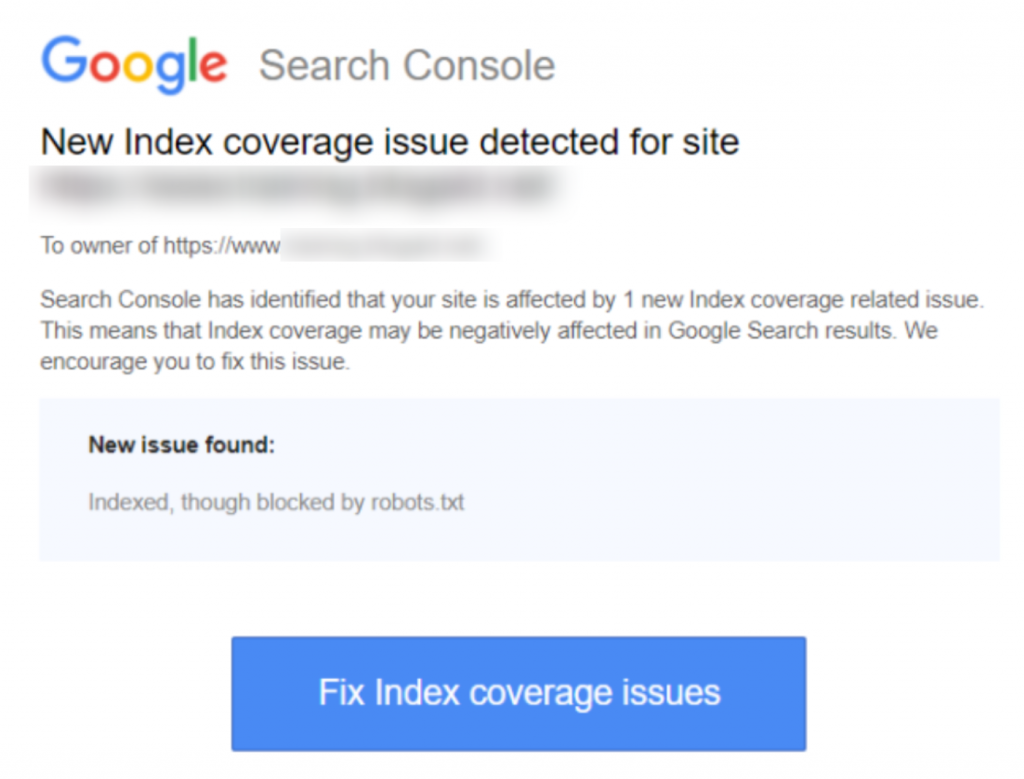
If you received the warning ‘Indexed, though blocked by robots.txt’ notification in Google Search Console, you’ll want to fix it as soon as possible, as it could be affecting the ability of your pages to rank at all in Search Engine Results Pages (SERPS).
A robots.txt file is a file that sits within your website's directory, that offers some instructions for Search Engine Crawlers, like Google's bot, as to which files they should and should not view.
‘Indexed, though blocked by robots.txt’ indicates that Google has found your page, but has also found an instruction to ignore it in your robots file (which means it won't show up in results).
Sometimes this is intentional, or something it is accidental, for a number of reasons outlined below, and can be fixed.
Feature update
New AI Visibility Checks are Here. Is Your Site Ready?
Run a free audit to see how well your site is optimized for Google AI Overviews and LLMs.
Run Free AuditHere is a screenshot of the notification:
Identify the affected page(s) or URL(s)
If you received a notification from Google Search Console (GSC), you need to identify the particular page(s) or URL(s) in question.
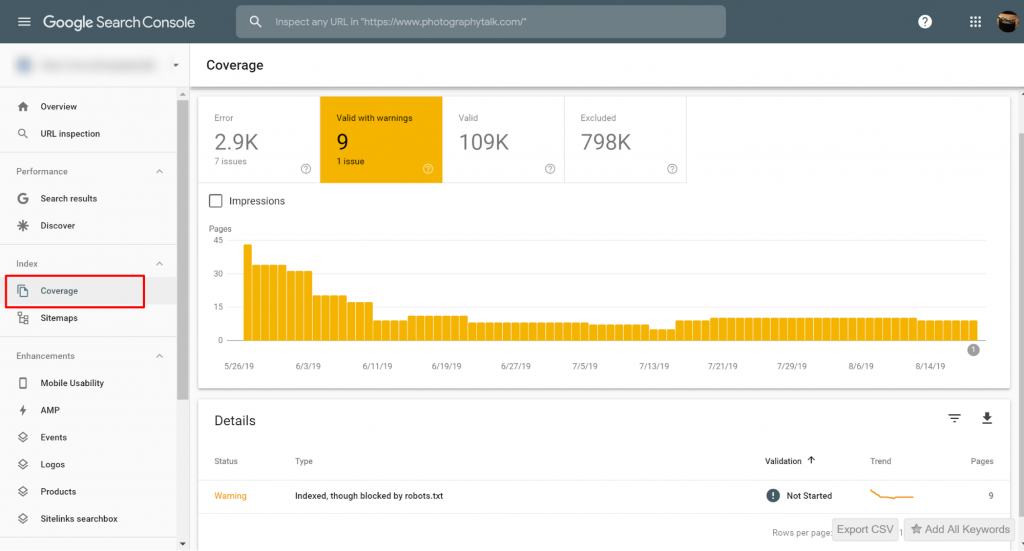
You can view pages with the Indexed, though blocked by robots.txt issues on Google Search Console>>Coverage. If you do not see the warning label, then you are free and clear.
A way to test your robots.txt is via using our robots.txt tester. You may find that you are okay with whatever is being blocked staying ‘blocked’. You, therefore, do not need to take any action.
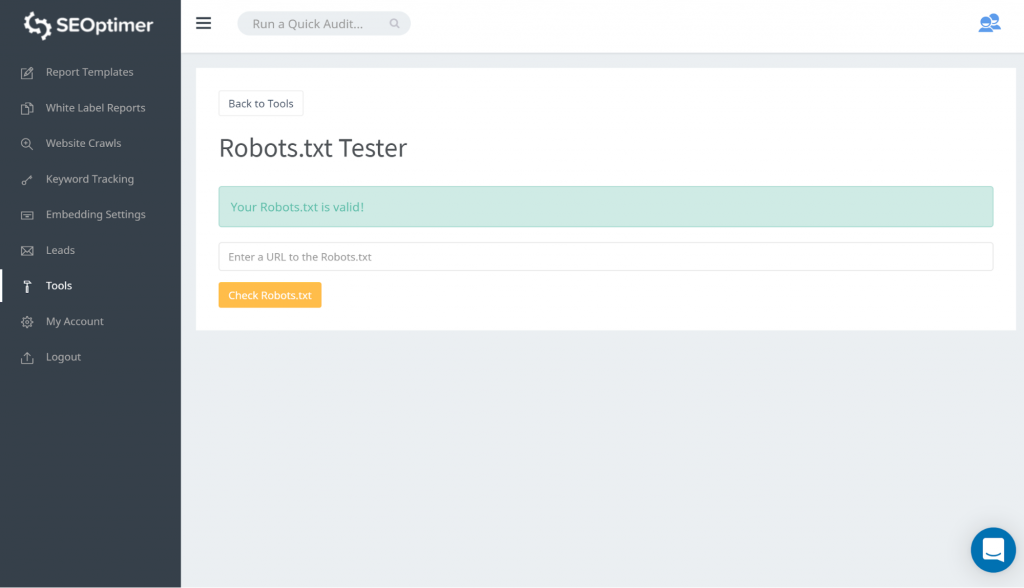
You can also follow this GSC link. You then need to:
- Open the list of the blocked resources and choose the domain.
- Click each resource. You should see this popup:
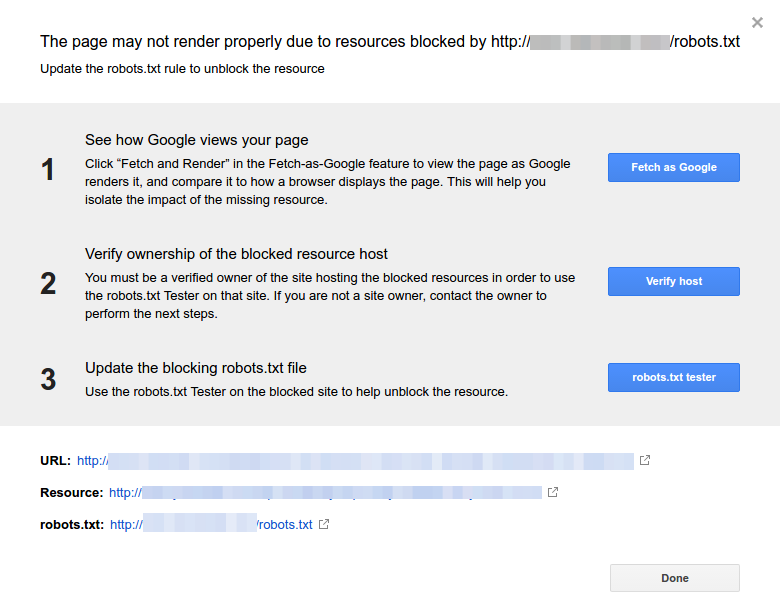
Identify the reason for the notification
The notification may result from several reasons. Here are the common ones:
But first, It's not necessarily a problem if there are pages blocked by robots.txt., It may have been designed due to reasons, such as, developer wanting to block unnecessary / category pages or duplicates. So, what are the discrepancies?
Wrong URL format
Sometimes, the issue might arise from a URL that is not really a page. For example, if the URL https://www.seoptimer.com/?s=digital+marketing, you need to know what page the URL resolves to.
If it is a page containing significant content that you really need your users to see, then you need to change the URL. This is possible on Content Management Systems (CMS) like Wordpress where you can edit a page’s slug.
If the page is not important, or with our /?s=digital+marketing example, it’s a search query from our blog then there is no need to fix the GSC error.
It does not make any difference if it is indexed or not, since it is not even a real URL, but a search query. Alternatively, you can delete the page.
Pages that should be indexed
There are several reasons why pages that should be indexed do not get indexed. Here are a few:
- Have you checked your robots directives? You may have included directives in your robots.txt file that disallow the indexing of pages that should actually be indexed, for example, tags and categories. Tags and categories are actual URLs on your site.
- Are you pointing the Googlebot to a redirect chain? Googlebot go through every link they can come across and do their best to read for indexing. However, if you set up a multiple, long, deep redirection, or if the page is just unreachable, Googlebot would stop looking.
- Implemented the canonical link correctly? A canonical tag is used in the HTML header to tell Googlebot which is the preferred and canonical page in the case of duplicated content. Every page should have a canonical tag. For example, you have a page that is translated into Spanish. You will self canonical the Spanish URL and you’d want to canonical the page back to your default English version.
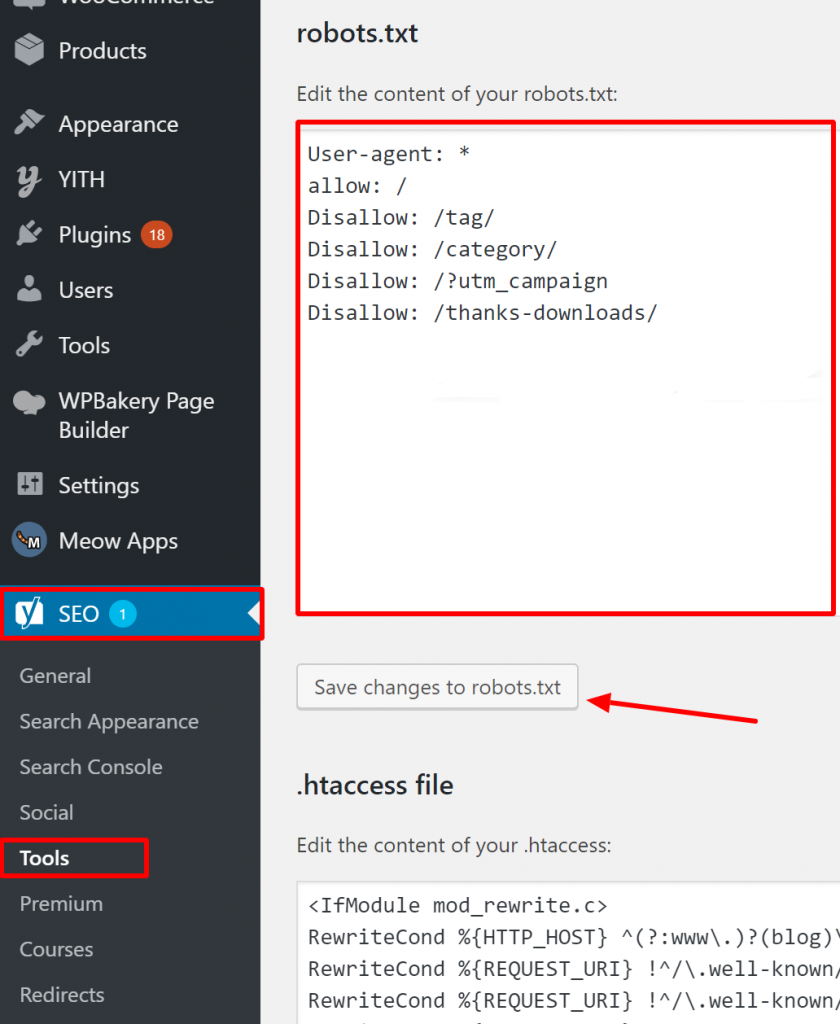
How to verify your Robots.txt is correct on WordPress?
For WordPress, if your robots.txt file is part of the site install, use the Yoast Plugin to edit it. If the robots.txt file that is causing issues is on another site that is not your own, you need to communicate with the site owners and request them to edit their robots.txt file.
Pages that should not be indexed
There are several reasons why pages that should not be indexed get indexed. Here are a few:
Robots.txt directives that ‘say’ that a page should not be indexed. Note that you need to allow the page with a ‘noindex’ directive to be crawled so that the search engine bots ‘know’ that it should not be indexed.
In your robots.txt file, make sure that:
- The ‘disallow’ line does not immediately follow the ‘user-agent’ line.
- There is no more than one ‘user-agent’ block.
- Invisible Unicode characters - you need to run your robots.txt file through a text editor which will convert encodings. This will remove any special characters.
Pages are linked to from other sites. Pages can get indexed if they are linked to from other sites, even if disallowed in robots.txt. In this case, however, only the URL and anchor text appear in search engine results. This is how these URLs are displayed on search engine results page (SERP):
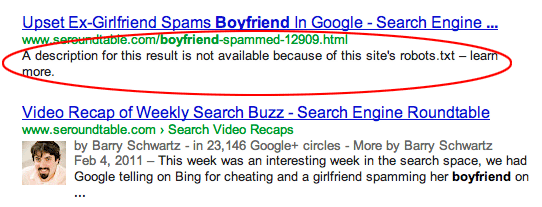
image source Webmasters StackExchange
One way to resolve the robots.txt blocking issue is by password protecting the file(s) on your server.
Alternatively, delete the pages from robots.txt or use the following meta tag to block
them:
<meta name=”robots” content=”noindex”>
Old URLs
If you have created new content or a new site and used a ‘noindex’ directive in robots.txt to make sure that it does not get indexed, or recently signed up for GSC, there are two options to fix the blocked by robots.txt issue:
- Give Google time to eventually drop the old URLs from its index
- 301 redirect the old URLs to the current ones
In the first case, Google ultimately drops URLs from its index if all they do is return 404s (meaning that the pages do not exist). It is not advisable to use plugins to redirect your 404s. The plugins could cause issues that may lead to GSC sending you the ‘blocked by robots.txt’ warning.
Virtual robots.txt files
There is a possibility of getting notification even if you do not have a robots.txt file. This is because CMS (Customer Management Systems) based sites, for example, WordPress have virtual robots.txt files. Plug-ins may also contain robots.txt files. These could be the ones causing problems on your site.
These virtual robots.txt need to be overwritten by your own robots.txt file. Make sure that your robots.txt includes a directive to allow all search engine bots to crawl your site. This is the only way that they can tell the URLs to index or not.
Here is the directive that allows all bots to crawl your site:
User-agent: *
Disallow: /
In conclusion
We have looked at the ‘Indexed, though blocked by robots.txt warning’, what it means, how to identify the affected pages or URLs, as well as the reason behind the warning. We have also looked at how to fix it. Note that the warning does not equal to an error on your site. However, failing to fix it might result in your most important pages not being indexed which is not good for user experience.