What is Robots.txt?
Robots.txt is a file in text form that instructs bot crawlers to index or not index certain pages. It is also known as the gatekeeper for your entire site. Bot crawlers’ first objective is to find and read the robots.txt file, before accessing your sitemap or any pages or folders.
With robots.txt, you can more specifically:
- Regulate how search engine bots crawl your site
- Provide certain access
- Help search engine spiders index the content of the page
- Show how to serve content to users
Robots.txt is a part of the Robots Exclusion Protocol (R.E.P), comprising of the site/page/URL level directives. While search engine bots can still crawl your entire site, it’s up to you to help them decide whether certain pages are worth the time and effort.
Why you need Robots.txt
Your site does not need a robots.txt file in order for it to work properly. The main reasons you need a robots.txt file is so that when bots crawl your page, they ask for permission to crawl so they can attempt to retrieve information about the page to index. Additionally, a website without a robots.txt file is basically asking bot crawlers to index the site as it sees fit. It’s important to understand that bots will still crawl your site without the robots.txt file.
The location of your robots.txt file is also important because all bots will look for www.123.com/robots.txt. If they don’t find anything there, they will assume that the site does not have a robots.txt file and index everything. The file must be an ASCII or UTF-8 text file. It is also important to note that rules are case-sensitive.
Here are some things robots.txt will and will not do:
- The file is able to control access of crawlers to certain areas of your website. You need to be very careful when setting up robots.txt as it is possible to block the entire website from being indexed.
- It prevents duplicate content from being indexed and appearing in search engine results.
- The file specifies the crawl delay in order to prevent servers from overloading when the crawlers are loading multiple pieces of content at the same time.
Here are some Googlebots that might crawl on your site from time to time:
| Web Crawler | User-Agent String |
| Googlebot News | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (featured phone) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (compatible; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (PPC landing page quality) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (fetch resources for mobile) | AdsBot-Google-Mobile-Apps |
You can find a list of additional bots here.
- The files help in the specification of the location of the sitemaps.
- It also prevents search engine bots from indexing various files on the website such as images and PDFs.
When a bot wants to visit your website (for example, www.123.com), it initially checks for www.123.com/robots.txt and finds:
User-agent: *
Disallow: /
This example instructs all (User-agents*) search engine bots to not index (Disallow: /) the website.
If you removed the forward slash from Disallow, like in the example below,
User-agent: *
Disallow:
the bots would be able to crawl and index everything on the website. This is why it is important to understand the syntax of robots.txt.
Understanding robots.txt syntax
Robots.txt syntax can be thought of as the “language” of robots.txt files. There are 5 common terms you’re likely to come across in a robots.txt file. They are:
- User-agent: The specific web crawler to which you’re giving crawl instructions (usually a search engine). A list of most user agents can be found here.
- Disallow: The command used to tell a user agent not to crawl a particular URL. Only one "Disallow:" line is allowed for each URL.
- Allow (Only applicable for Googlebot): The command tells Googlebot that it can access a page or subfolder even though its parent page or subfolder may be disallowed.
- Crawl-delay: The number of milliseconds a crawler should wait before loading and crawling page content. Note that Googlebot does not acknowledge this command, but crawl rate can be set in Google Search Console.
- Sitemap: Used to call out the location of any XML sitemap(s) associated with a URL. Note this command is only supported by Google, Ask, Bing, and Yahoo.
Robots.txt instruction outcomes
You expect three outcomes when you issue robots.txt instructions:
- Full allow
- Full disallow
- Conditional allow
Full allow
This outcome means that all content on your website may be crawled. Robots.txt files are meant to block crawling by search engine bots, so this command can be very important.
This outcome could mean that you do not have a robots.txt file on your website at all. Even if you do not have it, search engine bots will still look for it on your site. If they do not get it, then they will crawl all parts of your website.
The other option under this outcome is to create a robots.txt file but keep it empty. When the spider comes to crawl, it will identify and even read the robots.txt file. Since it will find nothing there, it’ll proceed to crawl the rest of the site.
If you have a robots.txt file and have the following two lines in it,
User-agent:*
Disallow:
the search engine spider will crawl your website, identify the robots.txt file and read it. It will get to line two and then proceed to crawl the rest of the site.
Full disallow
Here, no content will be crawled and indexed. This command is issued by this line:
User-agent:*
Disallow:/
When we talk about no content, we mean that nothing from the website (content, pages, etc.) can be crawled. This is never a good idea.
Conditional Allow
This means that only certain content on the website can be crawled.
A conditional allow has this format:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
You can find the full robots.txt syntax here.
Note that blocked pages can still be indexed even if you disallowed the URL as shown in the image below:
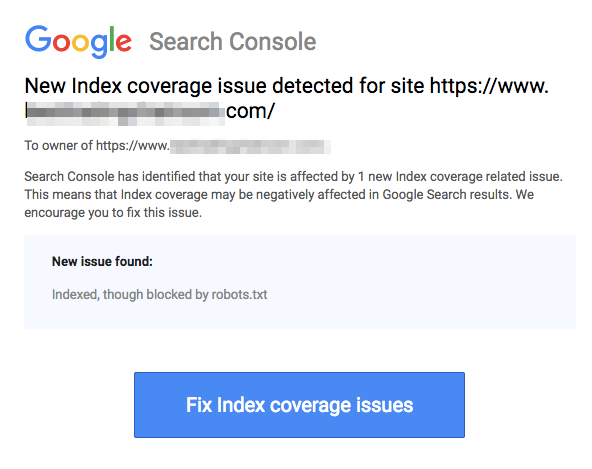
You might receive an email from search engines that your URL has been indexed like in the screenshot above. If your disallowed URL is linked from other sites, such as anchor text in links, it will get indexed. The solution to this is to 1) password-protect your files on your server, 2) use the noindex meta tag, or 3) remove the page entirely.
Can a robot still scan through and ignore my robots.txt file?
Yes. it is possible that a robot can bypass robots.txt. This is because Google uses other factors like external information and incoming links to determine whether a page should be indexed or not. If you do not want a page to be indexed at all, you should utilize the noindex robots meta tag. Another option would be to use the X-Robots-Tag HTTP header.
Can I block just bad robots?
It is possible to block bad robots in theory, but it might be difficult to do so in practice. Let’s look at some ways to do so:
- You can block a bad robot by excluding it. You, however, need to know the name the particular robot scans in the User-Agent field. You then need to add a section in your robots.txt file that excludes the bad robot.
- Server configuration. This would only work if the bad robot’s operation is from a single IP address. Server configuration or a network firewall will block the bad robot from accessing your web server.
- Using advanced firewall rule configurations. These will automatically block access to the various IP addresses where copies of the bad robot exist. A good example of bots operating in various IP addresses is in the case of hijacked PCs which could even be part of a larger Botnet (learn more about Botnet here).
If the bad robot operates from a single IP address, you can block its access to your web server through server configuration or with a network firewall.
If copies of the robot operate at a number of different IP addresses, then it becomes more difficult to block them. The best option in this case is to use advanced firewall rule configurations that automatically block access to IP addresses that make many connections; unfortunately, this may affect the access of good bots as well.
What are some of the best SEO practices when using robots.txt?
At this point, you may be wondering how to navigate these very tricky robots.txt waters. Let’s look at this in more detail:
- Ensure that you are not blocking any content or sections of your site that you want crawled.
- Use a blocking mechanism different than robots.txt if you want link equity to be passed from a page with robots.txt (which means that it is practically blocked) to the link destination.
- Don’t use robots.txt to prevent sensitive data such as private user information from appearing in search engine results. Doing so could allow other pages to link to pages which contain private user information which may cause the page to be indexed. In this case, robots.txt has been bypassed. Other options that you may explore here are password protection or the noindex meta directive.
- There is no need to specify directives for each of a search engine’s crawlers since most user agents, if belonging to the same search engine, follow the same rules. Google uses Googlebot for search engines and Googlebot Image for image searches. The only advantage of knowing how to specify each crawler is that you are able to fine-tune exactly how content on your site is crawled.
- If you have changed the robots.txt file and you want Google to update it more quickly, submit it directly to Google. For instructions on how to do that, click here. It is important to note that search engines cache robots.txt content and update the cached content at least once a day.
Basic robots.txt guidelines
Now that you have a basic understanding of SEO in relation to robots.txt, what things should you keep in mind when using robots.txt? In this section, we look at some guidelines to follow when using robots.txt, though it is important to actually read the entire syntax.
Format and location
The text editor that you choose to use to create a robots.txt file needs to be able to create standard ASCII or UTF-8 text files. Using a word processor is not a good idea since some characters which may affect crawling may be added.
While almost any text editor can be used to create your robots.txt file, this tool is highly recommended as it allows for testing against your site.
Here are more guidelines on format and location:
- You must name the file that you create “robots.txt” because the file is case sensitive. No uppercase characters are used.
- You can only have one robots.txt file on the entire site.
- The robots.txt file is only located in one place: the root of the website host it is applicable to. Note that it cannot be placed in a subdirectory. If your website is http://www.123.com/, then the location of robots.txt is http://www.123.com/robots.txt, not http://www.123.com/pages/robots.txt. Note that the robots.txt file can apply to subdomains (http://website.123.com/robots.txt) and even non-standard ports, such as http://www.123.com: 8181/robots.txt.
As aforementioned, robots.txt is not the best way to prevent sensitive personal information from being indexed. This is a valid concern, especially now with the recently implemented GDPR. Data privacy should not be compromised. Period.
How do you then ensure that robots.txt does not show sensitive data in search results?
Using a separate sub-directory that is “unlistable” on the web will prevent the distribution of sensitive material. You can ensure that it is “unlistable” by using server configuration. Simply store all the files that you do not want robots.txt to visit and index in this sub-directory.
Doesn’t listing pages or directories in the robots.txt file result in unintended access?
As aforementioned, putting all the files that you do not want indexed in a separate sub-directory and then making it un-listable via server configurations should ensure that they do not appear in search results. The only listing that you will then do in the robots.txt file is the directory name. The only way to access these files is via a direct link to one of the files.
Here is an example:
Instead of
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Use
User-Agent:*
Disallow:/norobots/
You then need to create a “norobots” directory, which includes foo.html and bar.html. Note that your server configurations need to be clear about not generating a directory listing for the “norobots” directory.
This may not be a very secure approach because the person or bot attacking your site can still see that you have a “norobots” directory even though they may not be able to view the files inside the directory. However, someone could publish a link to those files on their website or, worse still, the link may show up in a log file that is accessible to the public (e.g. a web server log as a referrer). A server misconfiguration is also possible, resulting in a directory listing.
What does this mean? Robots.txt cannot help you with controlling access for the simple reason that it is not meant for it. A good example is a “No-entry sign.” There are people who will still violate the instruction.
If there are files that you only want to be accessed by authorized people, server configurations will help with authentication. If you use a CMS (Content Management System), you have access controls on individual pages and resource collection.
Can you optimize robots.txt for SEO?
Absolutely. The best guide on how to optimize robots.txt is site content. A quick reminder: Robots.txt should never be used to block pages from being crawled by search engine bots. Only use it to block the sections of your website not accessible to the public, for instance, login pages like wp-admin.
This is the disallow line for Neil Patel’s login page on one of his websites:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
You can use this disallow line to block your login from being indexed.
If there are some specific pages that you do not want to be indexed, use the same command as above. An example:
User-agent:*
Disallow:/page/
Specify the page that you do not want to be indexed after the slash and close with another slash. For instance:
User-agent:*
Disallow:/page/thank-you/
What are some of the pages that you may want to exclude from being indexed?
- Duplicate content that is intentional. What does this mean? Sometimes you intentionally create duplicate content to achieve a particular purpose. A good example is a printer-friendly version of a particular web page. You may use robots.txt to block the indexing of the printer-friendly version of the identical content.
- Thank you pages. The reason that you want to block this page from being indexed is simple: It is supposed to be a last step in the sales funnel. By the time your visitors arrive on this page, they should have gone through the entire sales funnel. If this page gets indexed, it means that you may miss out on leads, or that you will receive false leads.
The command to block such a page is:
Disallow:/thank-you/
Noindex and NoFollow
As we have been saying throughout this article, using robots.txt is not a 100% guarantee that your page will not get indexed. Let’s look at two ways to ensure that your blocked page is indeed not indexed.
The noindex directive
This works in conjunction with the disallow command. Use both in your directive, as in:
Disallow:/thank-you/
The nofollow directive
This works to specifically instruct Google bots not to crawl the links on a page. This is not part of the robots.txt file. To use the nofollow command to block pages from being crawled and indexed, you need to find the source code of the specific page that you don’t want indexed.
Paste this in between the opening and closing head tags:
<meta name = “robots” content=”nofollow”>
You can use both “nofollow” and “noindex” simultaneously. Use this line of code:
<meta name = “robots” content=”noindex,nofollow”>
Generating robots.txt
If you find it difficult to write robots.txt using all the necessary formats and syntax that you need to understand and follow, you can use tools that simplify the process. A good example is is our free robots.txt generator.
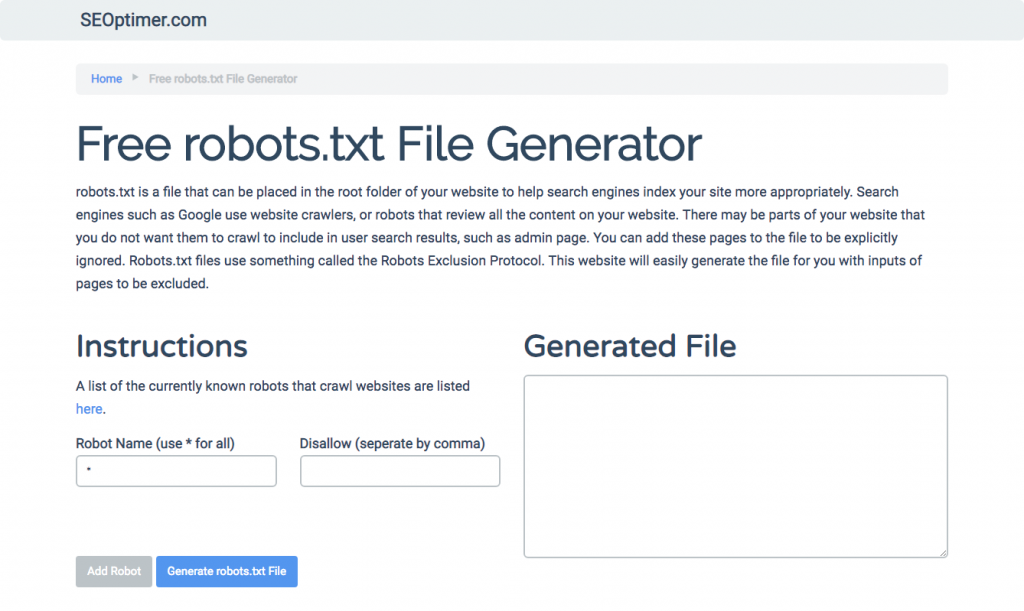
This tool allows you to choose the type of outcome that you need on your website and the file or directories that you want to add. You can even test your file and see how your competition is doing.
Testing your robots.txt file
You need to test your robots.txt file to ensure that it is working as expected.
Use Google’s robots.txt tester.
To do this, sign in to your Webmaster’s account.
- Next, select your property. In this case, it is your website.
- Click on “crawl” on the left-hand sidebar.
- Click on “robots.txt tester.”
- Replace any existing code with your new robots.txt file.
- Click “test.”
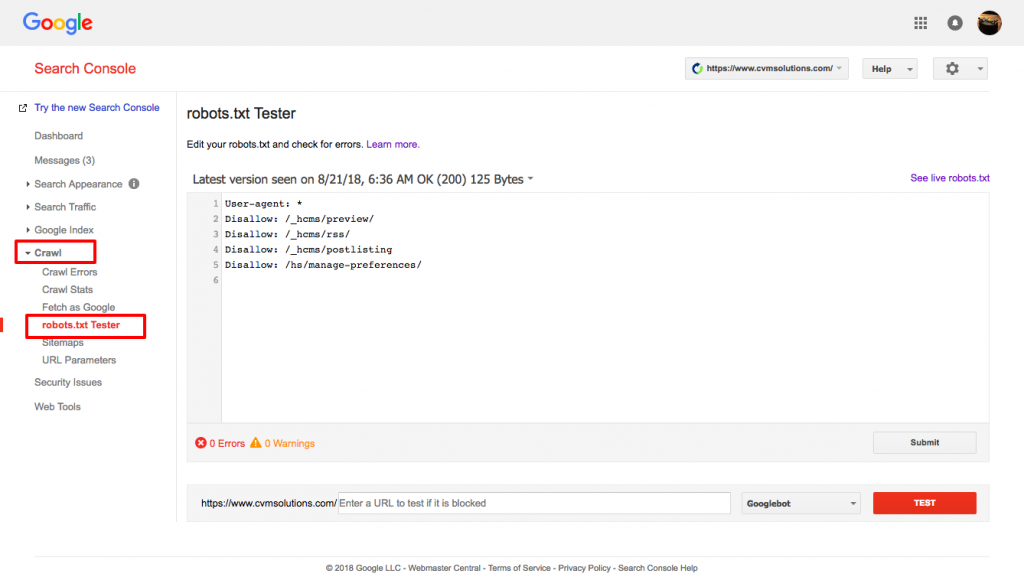
You should be able to see a text box “allowed” if the file is valid. For more information, check out this in-depth guide to Google robots.txt tester.
If your file is valid, it is now time to upload it to your root directory or save it if there as another robots.txt file.
How to add robots.txt to your WordPress site
To add a robots.txt file to your WordPress file, we will cover plugin and FTP options.
For the plugin option, you can use a plug-in like All in One SEO Pack
To do this, log in to your WordPress dashboard
Scroll down until you get to “plugins”
Click “add new”
Go to “search plugins”
Type “All in One SEO Pack”
Install it and activate
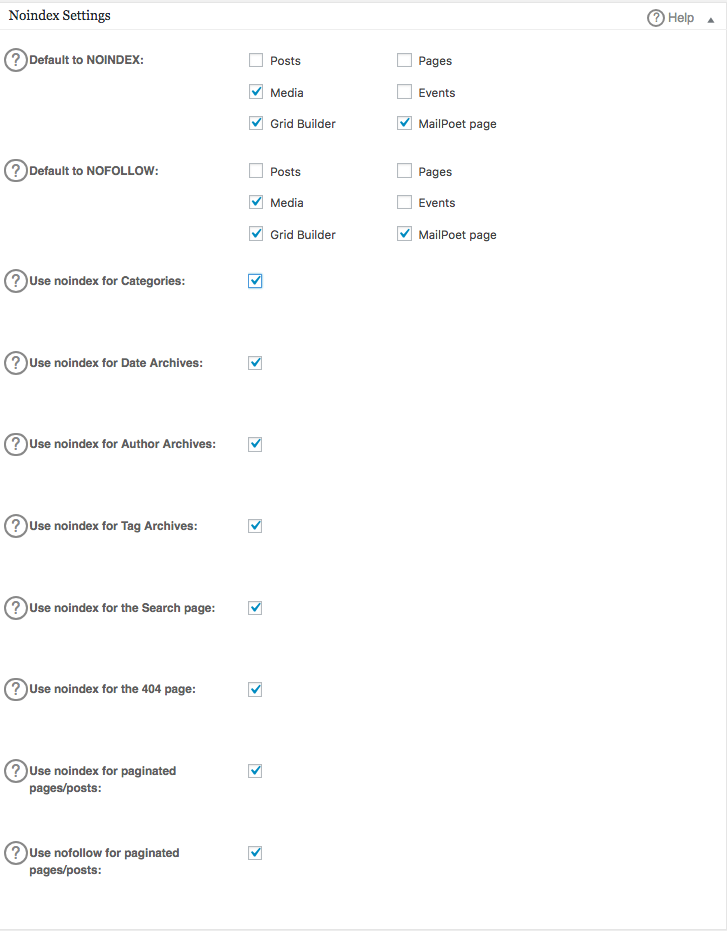
Under the General Setting section of All in One SEO plugin, you can configure the noindex and nofollow rules to be included in your robots.txt file.
You can specify what URLs should be NOINDEX, NOFOLLOW. Leaving these unchecked will default to being indexed:
To create advanced rules in your robots.txt file, click the feature manager, then the activate button just below robots.txt.
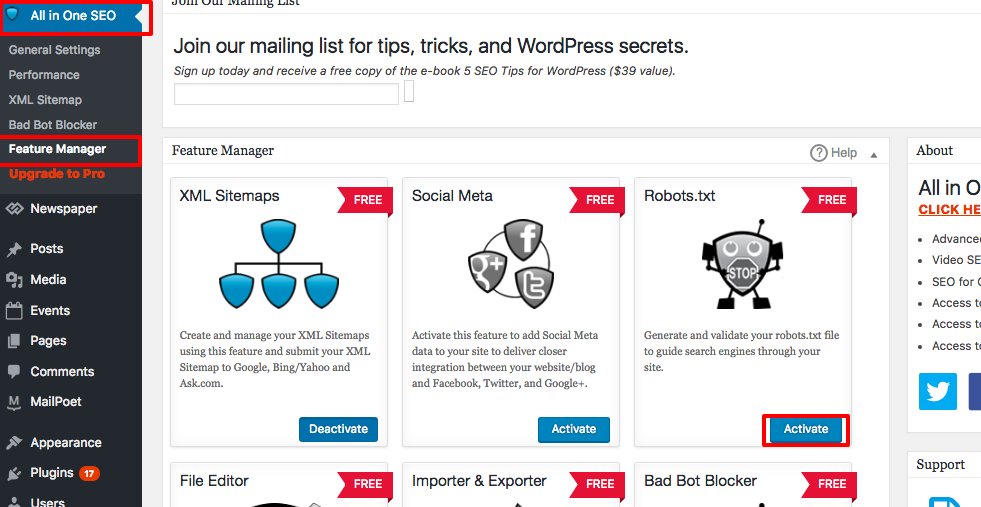
Robots.txt now appears just below feature manager. Click on it. You will see a section called “create a robots.txt file.”
There is a rule builder section which allows you to choose and fill in the rules that you want for your site, depending on what you want don’t want indexed.
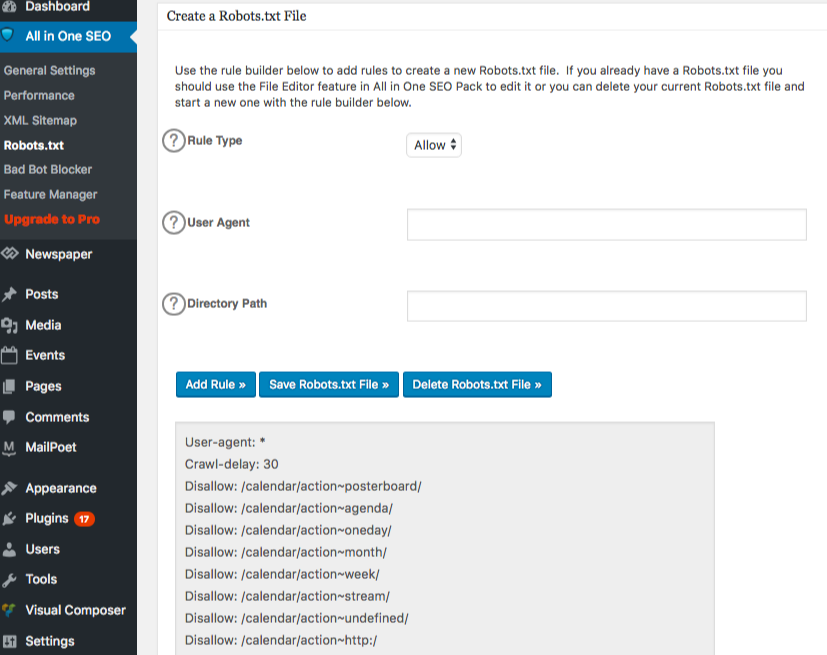
Once you are done creating the rule, click “add rule.”
The rule will then be listed under the robots.txt folder created.
You will see a message to indicate that “All in One Options” have been updated.
Another method you can use is to upload your robots.txt file directly to your FTP (File Transfer Protocol) client like FileZilla.
Once you have generated your robots.txt file, you can locate and replace it. Your robots.txt file will be located in: “/applications/[FOLDER NAME]/public_html.”
How to edit the robots.txt file on your Wix
Wix generates a robots.txt file for websites using the web-building platform. To view it, add “/robots.txt” to your domain. The files added to robots.txt have to do with the structure of Wix sites, for instance, noflashhtml links, which don’t contribute to the SEO value of your Wix-powered site.
You cannot edit your robots.txt file if your site is powered by Wix. You can only use other options like adding a “noindex tag” to the pages that you no do not want to be indexed.
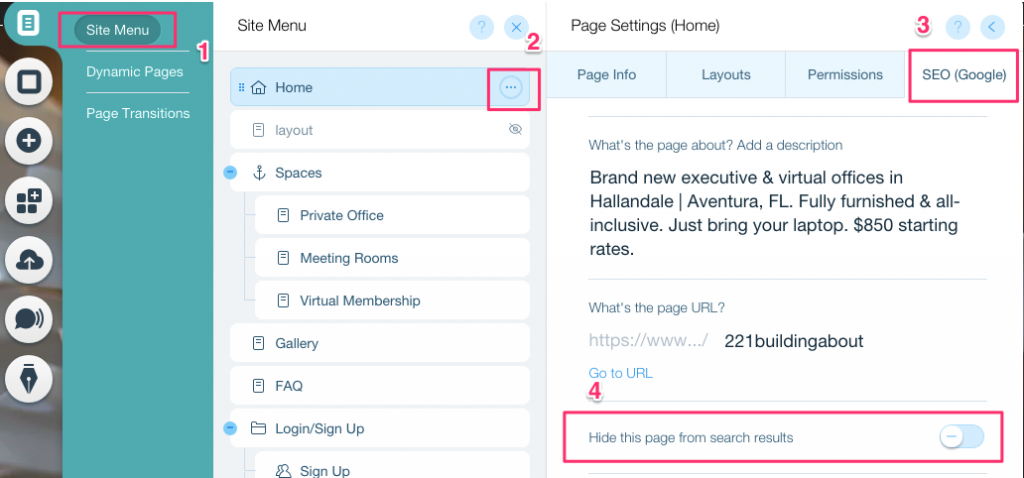
To create a noindex tag for a specific page:
- Click on Site Menu
- Click on the Setting option for that specific page
- Select SEO (Google) tag
- Turn on Hide this page from search results
How to edit the robots.txt file on your Shopify
Just like with Wix, Shopify automatically adds an uneditable robots.txt file to your site. If you do not want some pages indexed, you need to add the “noindex tag” or unpublish the page. You can also add meta tags in the header section of the pages you do not want to be indexed. This is what you should add to your header:
<meta name= “robots” content = “noindex”>
Shopify created a thorough guide on how to hide pages from search engines that you can follow.
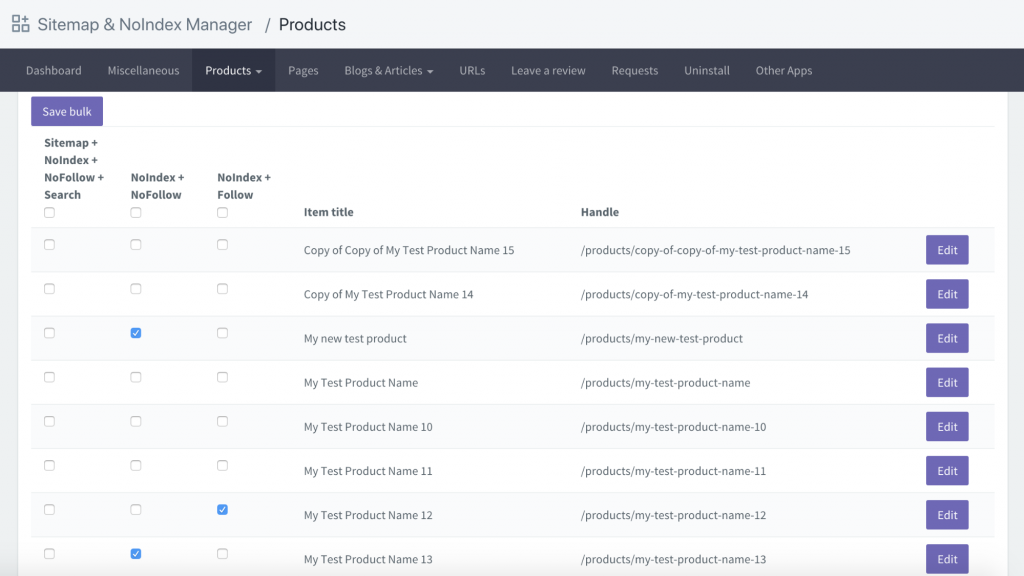
Another option is to download an app called Sitemap & NoIndex Manager by Orbis Labs. You can simply check the noindex or nofollow options for each pages on your Shopify site: