Sprawienie, aby twoja aplikacja jednostronicowa (SPA) została odkryta przez wyszukiwarki, nie jest łatwym zadaniem. SEO dla aplikacji jednostronicowych pomaga twoim aplikacjom internetowym uzyskać więcej organicznych wyświetleń.
Witryny oparte na HTML są łatwiejsze do "dostępu", "przeszukiwania" i "indeksowania", ponieważ zapewniają uporządkowany znacznik dla "crawlers".
Dlatego "posiadanie" swojej treści na stronach HTML może prowadzić do "lepszych" wyników w wyszukiwarkach, a także są one łatwiejsze do "optymalizacji" niż aplikacje jednostronicowe.
SPAs w dużym stopniu polegają na JavaScript do dynamicznego przepisania treści w oparciu o działania odwiedzających na stronie (pomyśl o "rozszerzanym tekście" lub "wyskakujących okienkach").
Dlatego utrudnia to Googlebotom indeksowanie zawartości strony, ponieważ nie uruchamiają one treści "JavaScript" po stronie klienta.
W tym artykule omówię rzeczywiste wyzwania związane z korzystaniem z SPAs i podzielę się kompletnym procesem robienia SEO dla "single page apps" w celu uzyskania lepszych wyników wyszukiwania.
Kluczowe wnioski
- SEO dla aplikacji jednostronicowych jest niezbędne, ponieważ oparte na JavaScript SPAs często ukrywają kluczową "treść" przed crawlerami.
- Używaj renderowania po stronie serwera (SSR) lub pre-renderingu, aby dostarczyć crawlerom w pełni wyrenderowane wersje HTML swoich stron.
- "Dynamiczne tytuły", "meta opisy" i "tagi kanoniczne" są kluczowe dla SEO aplikacji jednostronicowych, aby zapobiec duplikowaniu treści i utrzymać "relewancję" w różnych trasach.
- Połącz wewnętrzne linki, czyste URL-e, mapy witryn XML i poprawne kody statusu HTTP, aby pomóc wyszukiwarkom odkrywać i indeksować wszystkie kluczowe trasy w Twojej SPA.
Co to jest "SEO" dla "Single Page Applications (SPA)"?
Optymalizacja pod kątem wyszukiwarek dla aplikacji jednostronicowych odnosi się do procesu, dzięki któremu SPA, zbudowane przy użyciu frameworków JavaScript, takich jak React.js, Angular.js czy Vue.js, stają się dostępne i indeksowalne przez wyszukiwarki.
SEO dla "aplikacji jednostronicowych" obejmuje:
- Renderowanie po stronie serwera lub [wstępne] renderowanie
- [Optymalizacja] tagów tytułu, meta opisów i danych strukturalnych
- [Optymalizacja] URL i tagu kanonicznego
- [Optymalizacja] linkowania wewnętrznego
- [Tworzenie] i [przesyłanie] mapy strony
- [Budowanie] linków
Google, Bing, Baidu, DuckDuckGo i inne wyszukiwarki mają trudności z przeszukiwaniem i indeksowaniem treści JavaScript, ponieważ SPAs ładują treść dynamicznie po stronie klienta.
Dlatego "SPA SEO" składa się ze strategii i najlepszych praktyk mających na celu poprawę odkrywalności i obecności w sieci aplikacji jednostronicowych w wyszukiwarkach.
Przykłady "Single Page Applications"
Oto najlepsze przykłady "SPA":
Gmail
Gmail jest podręcznikowym przykładem "SPA". Kiedy się logujesz, cały interfejs użytkownika, w tym twoja skrzynka odbiorcza, "foldery" i "czat", jest ładowany jednorazowo.
Od tego momentu przeglądanie e-maili, otwieranie wątków czy tworzenie nowych wiadomości nie wymaga pełnego przeładowania strony.
JavaScript zarządza "routingiem" i zmianami treści w tle, co sprawia, że doświadczenie jest szybkie i bezproblemowe.
Google używa asynchronicznych żądań do pobierania tylko wymaganych danych, co zmniejsza opóźnienia i poprawia doświadczenia użytkownika.
Google Maps
Google Maps oferuje bogate interaktywne funkcje, takie jak "przesuwanie", "powiększanie" i [wyszukiwanie] lokalizacji, wszystko w obrębie tej samej strony.
Nie przeładowuje się, gdy [proszisz] o nowe [kierunki] lub [przełączasz się] między widokami satelitarnymi a mapami.
Zamiast tego dane są pobierane za pomocą AJAX, a kafelki mapy lub komponenty UI aktualizują się dynamicznie. To sprawia, że Google Maps jest niezwykle responsywne i użyteczne, nawet przy wolniejszych połączeniach.
Chociaż nie w 100% SPA, duże części Facebooka używają architektury SPA.
Kiedy użytkownicy przewijają swój "news feed", otwierają "posty", reagują lub komentują, wszystkie [aktualizacje] odbywają się bez przeładowania strony.
Nawet podczas przełączania się między stronami, takimi jak "Wiadomości", "Powiadomienia" i "Marketplace", witryna używa routingu po stronie klienta z wykorzystaniem frameworków JavaScript (jak React) do dynamicznego renderowania treści, co zmniejsza liczbę wywołań serwera i poprawia szybkość ładowania.
Netflix
Interfejs internetowy Netflix to kolejny znany SPA. Gdy przeglądasz sugestie filmów lub programów telewizyjnych, "trailery" [odtwarzają się] automatycznie, a [szczegóły] zawartości pojawiają się natychmiast bez ponownego ładowania.
Kliknięcie tytułu otwiera "nakładkę modalną" lub nowy widok, zachowując nienaruszony podstawowy interfejs.
"Routing", "rekomendacje" i "zmiany profilu użytkownika" są zarządzane przez JavaScript, zapewniając spójne doświadczenie z niskimi czasami oczekiwania.
Czy "Single Page Application" jest [dobre] dla SEO?
Tak, "aplikacja jednostronicowa" jest dobra dla SEO, jeśli znasz odpowiednie wskazówki dotyczące optymalizacji dla SPA.
Wyszukiwarki takie jak Google mogą renderować JavaScript, ale mogą opóźniać [crawling] lub pomijać "treści" wymagające interakcji użytkownika.
Aby tego uniknąć, możesz użyć renderowania po stronie serwera, generowania statycznych witryn, czystego routingu URL i dynamicznych aktualizacji metadanych.
Narzędzia takie jak Next.js, Nuxt.js, React Helmet i Vue Meta pomagają sprawić, że to wszystko [działa].
Przy odpowiedniej konfiguracji, SPA może uzyskać równie wysoką pozycję jak każda tradycyjna strona. Jednak bez właściwych dostosowań SEO, wyszukiwarki mogą przeoczyć wiele z tego, co stworzyłeś.
Powiązana lektura: Jak wykonać SEO dla dynamicznej treści
Jak zrobić "SEO" dla "Single Page Applications"
Oto najlepsze rozwiązania SEO dla aplikacji jednostronicowych:
Użyj "Renderowanie po stronie serwera" (SSR)
Jednostronicowe aplikacje polegają na JavaScript do dynamicznego ładowania treści.
Jednak wyszukiwarki oczekują kompletnego serwera HTML w odpowiedzi HTTP, aby uzyskać dostęp, [przeszukiwać] i indeksować [zawartość].
Dlatego powinieneś zaimplementować "renderowanie po stronie serwera", aby [renderować] strony na serwerze przed ich wysłaniem do przeglądarki.
W renderowaniu po stronie serwera, przeglądarka [żąda] plików HTML, a serwer [pobiera] wszystkie dane. Zapewnia to, że cała "zawartość" jest natychmiast widoczna i możliwa do zindeksowania.
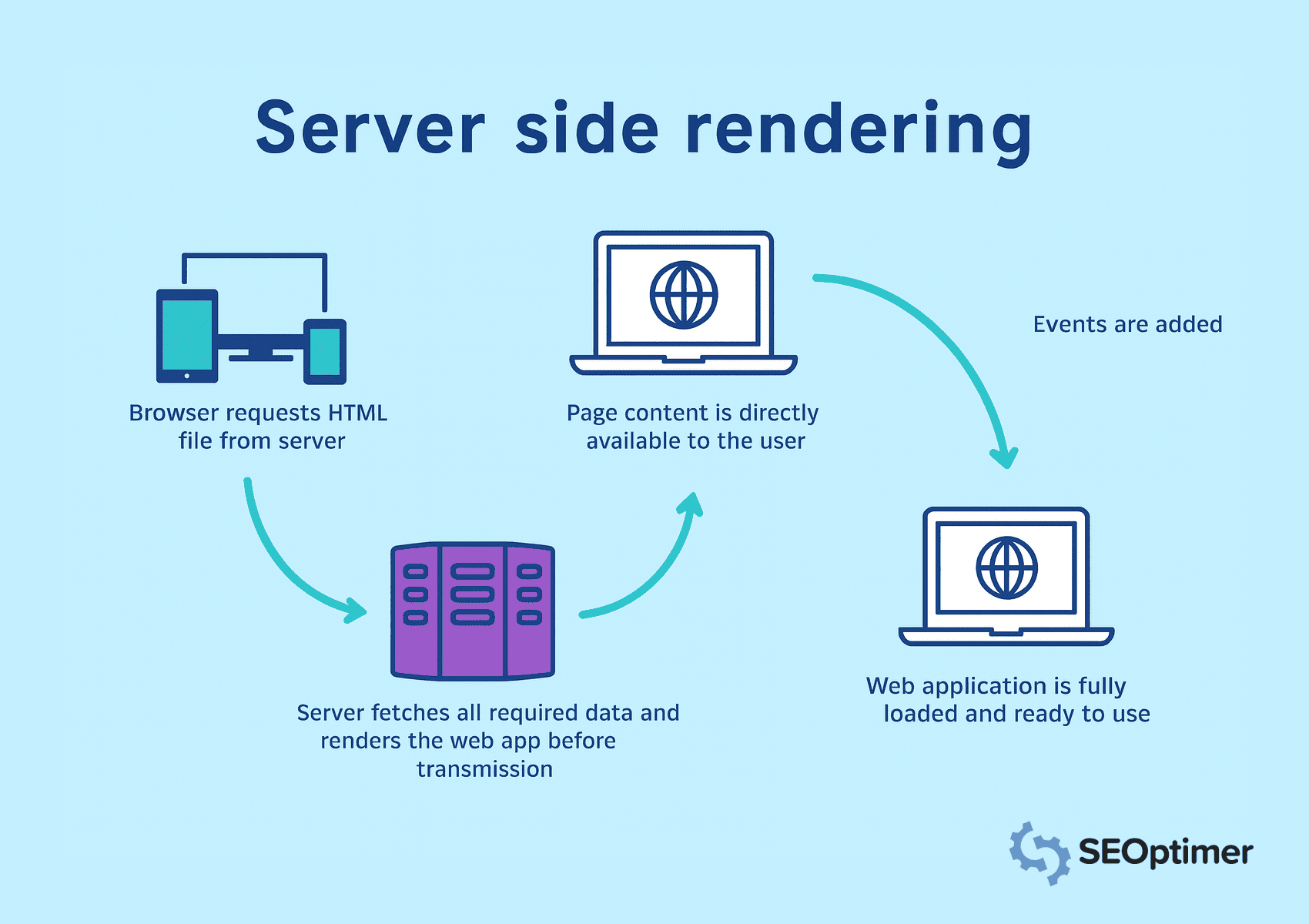
Pamiętaj o "cache'owaniu" często odwiedzanych stron, aby zmniejszyć czas ładowania i szybciej dostarczać treści. Unikaj renderowania po stronie klienta dla kluczowych elementów, ponieważ wyszukiwarki mogą nie przetworzyć widoków z dużą ilością JavaScript.
Zaimplementuj wstępne renderowanie dla "statycznych tras"
Należy wstępnie renderować trasy, które pokazują tę samą treść każdemu odwiedzającemu. Pozwala to generować HTML podczas budowania i eliminuje potrzebę renderowania w czasie rzeczywistym.
W rezultacie, wyszukiwarki mogą natychmiast uzyskać dostęp do strony.
Narzędzia do statycznego generowania z frameworków takich jak Next.js czy Nuxt.js mogą pomóc w tworzeniu plików statycznych dla tras, takich jak "strony docelowe", "blogi" lub "przeglądy produktów".
Należy serwować te wstępnie renderowane strony za pośrednictwem Content Delivery Network lub serwera internetowego, aby poprawić [szybkość] ładowania i widoczność. Unikaj stosowania wstępnego renderowania do widoków z danymi [w czasie rzeczywistym] lub specyficznymi dla użytkownika.
Dodaj czysty i przeszukiwalny wynik HyperText Markup Language
Powinieneś wygenerować dobrze zbudowany kod "HyperText Markup Language" output, który [search engines] mogą łatwo zinterpretować.
Czysty "markup" pomaga botom zrozumieć układ strony, hierarchię i kluczowe elementy bez polegania na wykonywaniu "JavaScript".
Unikaj dynamicznego wstrzykiwania zawartości po załadowaniu strony. Zamiast tego, upewnij się, że "ważny tekst", nagłówki, i "linki" pojawiają się bezpośrednio w kodzie źródłowym.
Kiedy pracujesz nad "SEO" dla aplikacji jednostronicowej, najważniejszą rzeczą do zapamiętania jest to, że Google nie zawsze widzi twoją stronę w taki sposób, jak ludzie. Ponieważ ładują [zawartość] za pomocą "JavaScript", czasami robot indeksujący otrzymuje tylko pustą stronę. Więc upewnij się, że to, co chcesz, aby Google przeczytał, faktycznie pojawia się w html.
- Ciara Edmondson, "SEO & Content Manager" w Max Web Solutions
Użyj semantycznych znaczników takich jak <header>, <main>, <article> i <footer>, aby zapewnić [jasną] strukturę.
Powinieneś również zminimalizować style "wewnętrzne" i "bałagan" skryptów, który może zasłonić [znaczącą] treść.
Utrzymuj dokument "czytelny" i "lekki" dla "szybszego indeksowania" i lepszego "pozycjonowania".
Użyj renderowania po stronie serwera lub wstępnego renderowania, aby wygenerować statyczny HTML dla każdej trasy. Gwarantuje to, że roboty indeksujące uzyskują dostęp do pełnej zawartości strony przy początkowym żądaniu.
Udostępnij "statyczne migawki" dla "robotów indeksujących"
Należy wystawiać statyczne migawki, aby zapewnić, że roboty indeksujące mają dostęp do [kompletnej] "zawartości", zwłaszcza gdy renderowanie po stronie klienta opóźnia wyświetlanie [strony].
Statyczny snapshot to w pełni renderowana wersja strony generowana z wyprzedzeniem i dostarczana specjalnie dla botów.
Ta taktyka jest przydatna, gdy renderowanie po stronie serwera lub wstępne renderowanie nie jest wykonalne w całej aplikacji.
„Migawki” zapewniają alternatywną ścieżkę dla „crawlers”, aby uzyskać dostęp do struktury „HyperText Markup Language” bez wykonywania „JavaScript”.
Powinieneś skonfigurować serwer, aby wykrywał "agenty użytkownika" takie jak Googlebot i serwował predefiniowane "migawki" dla tych żądań.
Narzędzia takie jak Rendertron, Prerender.io lub niestandardowe renderery headless NodeJS mogą pomóc w niezawodnym generowaniu i dostarczaniu [migawkowych].

Upewnij się, że każda migawka odzwierciedla pełną zawartość i strukturę strony, w tym tytuły, metadane, linki i oznaczenia schematów.
Safira z Somar Digital, agencji z siedzibą w Nowej Zelandii, zaleca, że wszystkie SPAs powinny używać "schema markup" dla ich SEO.
[Polecam] [korzystanie] [ze] [strukturyzowanych] [danych] schema markup dla SPAs. Zintegruj odpowiednie schema markups jak "organizacja", "strona internetowa", "lista okruszków", "FAQ", itp.
Zauważyłem, że czasami znacznik schematu może nie pojawiać się w kodzie źródłowym ani nawet w Teście Wyników Rozszerzonych Google, ale jeśli przetestujesz schemat za pomocą walidatora znaczników schematu, zobaczysz dodane znaczniki schematu w wynikach. Dzieje się tak, ponieważ SPA, które wstrzykują Schemat (za pomocą JavaScript), nie mają tego dostępnego przy początkowym ładowaniu. Ale Google jest w stanie odczytać JavaScript, ponieważ jest bezgłowy.
- Safira Mumtaz, Specjalista ds. "SEO/SEM" w Somar Digital
Powinieneś również monitorować "pokrycie indeksu", aby potwierdzić, że "crawlers" przetwarzają [snapshots] zgodnie z przeznaczeniem.
Serwowanie statycznych zrzutów ekranu poprawia widoczność dla stron z "złożoną" logiką renderowania, pomagając utrzymać spójne indeksowanie i wartość SEO.
Ustaw "tagi" kanoniczne dla każdego widoku
Powinieneś ustawić tag kanoniczny dla każdej trasy w aplikacji jednostronicowej, aby uniknąć problemów z "duplikacją treści".
Większość czasu, "SPA" wygenerują wiele dostępnych "URL" dla tej samej [zawartości].
Na przykład, ta sama treść może być obecna w URL-ach z różnymi ciągami zapytań, filtrami lub parametrami śledzenia. Tag "kanoniczny" pomaga wyszukiwarkom zrozumieć preferowaną wersję.

Każda trasa powinna zawierać tag <link rel="canonical"> wskazujący na oryginalny URL dla tego widoku. To zapobiegarozcieńczenie "link equity"wśród różnych adresów URL zawierających tę samą treść.
Należy dynamicznie wstrzykiwać tagi kanoniczne, gdy zmienia się trasa, szczególnie jeśli aplikacja aktualizuje "metadane" po stronie klienta.
Użyj "routing hooks" lub funkcji "middleware", aby przypisać poprawny tag przy każdej [zmianie] strony.
Unikaj kierowania wszystkich tras do strony głównej lub używania statycznej wartości kanonicznej. Każdy "unikalny widok" powinien odzwierciedlać swój własny logiczny URL, aby zachować "trafność" i dokładność indeksu.
Implementacja właściwej "kanonikalizacji" wspiera [jaśniejsze] indeksowanie, poprawia [autorytet] strony i zapobiega niechcianemu [powielaniu] w wynikach wyszukiwania.
Obsługuj poprawnie kody statusu 404 i inne
Powinieneś skonfigurować dokładne kody statusu dla wszystkich widoków w aplikacji jednostronicowej, aby pomóc wyszukiwarkom prawidłowo interpretować strukturę Twojej strony.
Wiele SPA obsługuje domyślną powłokę HTML dla każdego żądania, co może zwrócić 200 OK nawet dla nieistniejących tras.
Prawidłowa odpowiedź 404 Not Found powinna być zwracana dla nieprawidłowych adresów URL.
Użyj logiki serwera lub "middleware" w NodeJS, aby wykryć niedopasowane trasy i wysłać poprawny kod statusu wraz z niestandardową stroną błędu.
Powinieneś również obsługiwać inne odpowiedzi, takie jak 301 lub 302 dla [przekierowania] i 500 dla [błędów serwera].
Te kody statusu informują wyszukiwarki, jak traktować każde żądanie i utrzymywać integralność Twojego indeksowania i pokrycia indeksu.
Unikaj polegania wyłącznie na obsłudze błędów po stronie klienta. Roboty indeksujące mogą nie wykonywać JavaScript, więc nieprawidłowe odpowiedzi statusu mogą uszkodzić sygnały "optymalizacji" dla wyszukiwarek i wprowadzać w błąd podczas indeksowania.
Prześlij "Dynamiczne URL" do Google Search Console
Powinieneś przesłać wszystkie ważne dynamiczne URL-e z aplikacji jednostronicowej do Google Search Console za pomocą narzędzia "URL Inspection Tool". Pomaga to botom wyszukiwarek odkrywać i indeksować [treści], które mogą nie pojawić się w tradycyjnym [crawl].
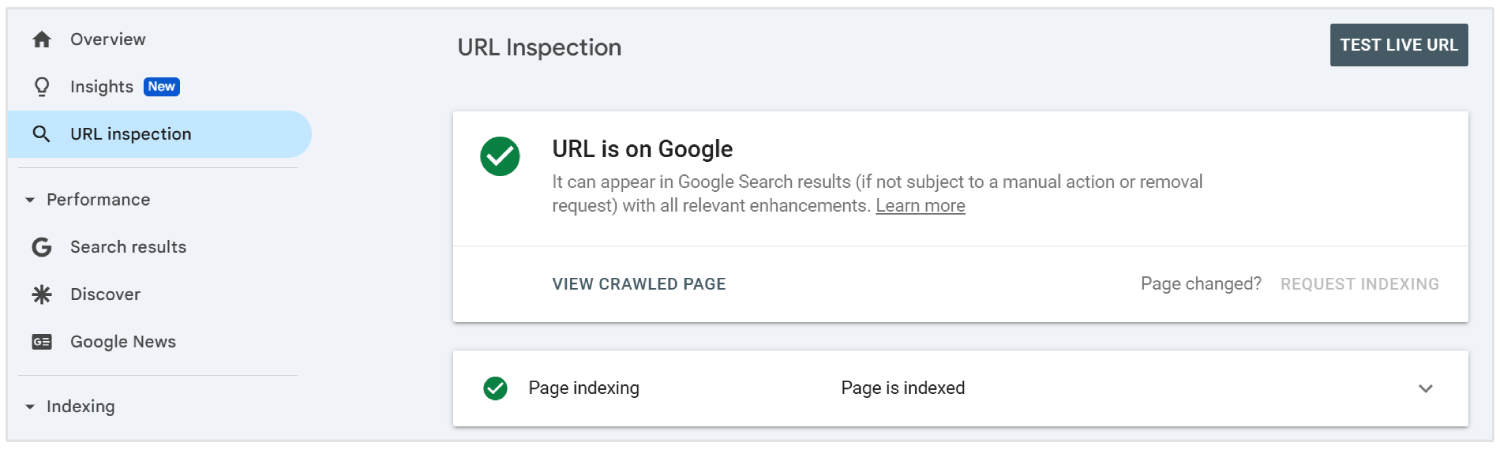
Ponieważ SPAs ładują zawartość przez routing po stronie klienta, niektóre wewnętrzne strony mogą nie być znalezione przez roboty indeksujące bez bezpośredniego linkowania.
Aby zapewnić widoczność, umieść te adresy URL w mapie witryny XML i prześlij ją za pośrednictwem interfejsu konsoli.
Powinieneś zaktualizować mapę witryny, gdy "dodawane są nowe trasy" lub [zmieniane]. Każdy wpis musi odzwierciedlać ostateczny, czysty adres URL, który widzą użytkownicy i roboty indeksujące, z wyłączeniem hashów lub niepotrzebnych parametrów.
Przesyłanie dynamicznych adresów URL daje Google jasną mapę struktury Twojej aplikacji i zwiększa szanse na [dokładne] indeksowanie i szybsze indeksowanie.
Włącz "leniwe ładowanie" z [zapasowymi rozwiązaniami]
Powinieneś włączyć leniwe ładowanie, aby poprawić wydajność w SPA, odkładając ładowanie nieistotnych elementów, takich jak obrazy, filmy lub sekcje poniżej widocznej części ekranu.
To pomaga zmniejszyć czas początkowego ładowania i poprawia wrażenia użytkownika na [komputerach stacjonarnych] i [urządzeniach mobilnych].
Wyszukiwarki mogą nie uruchamiać treści, która ładuje się przez JavaScript, co może prowadzić do [pominięcia] indeksowania.
Powinieneś zapewnić alternatywy, takie jak "zawartość zastępcza" lub <noscript> tagi, aby upewnić się, że wszystkie "kluczowe elementy" pozostają widoczne dla [crawlerów].
Używaj natywnych funkcji przeglądarki, takich jak atrybut loading="lazy" lub zarządzaj ładowaniem na podstawie przewijania za pomocą JavaScript. Zawsze należy potwierdzić widoczność za pomocą narzędzi takich jak Google Search Console.
Unikaj opóźniania ważnych treści lub linków, które przyczyniają się do widoczności w wyszukiwarce. Prawidłowe użycie "lazy loading" z niezawodnymi zabezpieczeniami wspiera szybsze ładowanie i pełne pokrycie treści.
Odroczenie niekrytycznego JavaScriptu
Należy odroczyć niekrytyczny JavaScript, aby przyspieszyć początkowe renderowanie strony i zmniejszyć blokowanie ważnych treści w aplikacjach jednostronicowych.
Skrypty, które nie są niezbędne dla "zawartości nad zgięciem", mogą opóźniać zarówno interakcję użytkownika, jak i widoczność crawlera.
Użyj atrybutów defer lub async w tagach script, aby zapobiec niepotrzebnemu wykonywaniu podczas pierwszego ładowania strony.
Umieść "skrypty" nieistotne na końcu dokumentu lub załaduj je po wyrenderowaniu [głównej] treści.
Powinieneś zidentyfikować, które skrypty wpływają na "układ", "metadane" lub logikę trasowania, i oddzielić je od analityki, widżetów czatu lub animacji.
Narzędzia takie jak Lighthouse i Chrome DevTools mogą pomóc w audycie "zachowania" [skryptu] i "sekwencji ładowania".
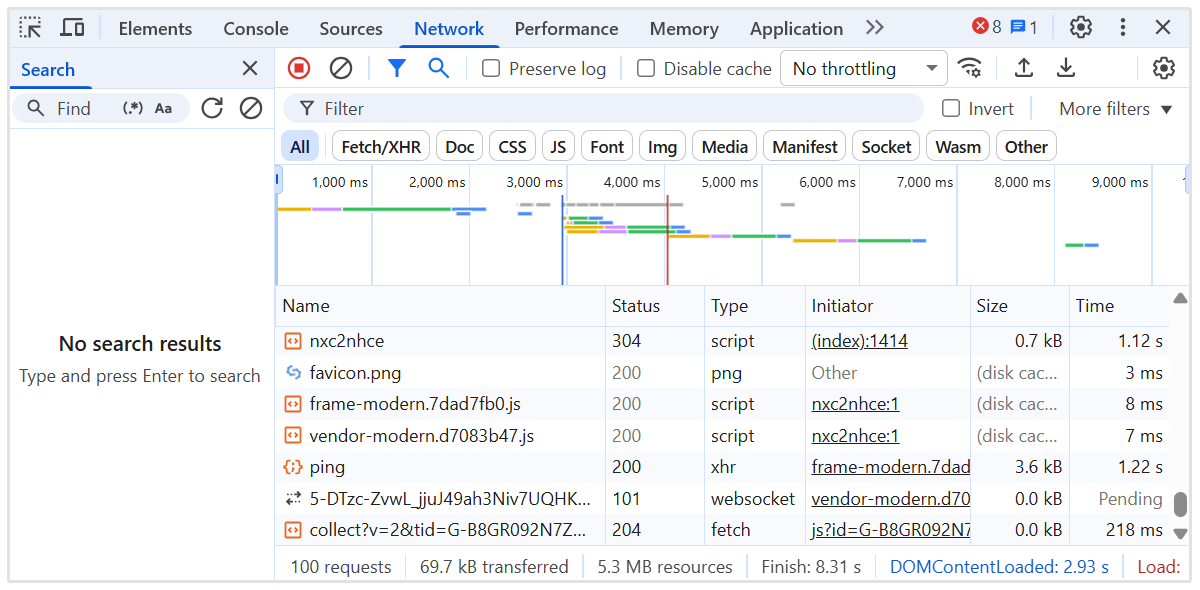
Zaimplementuj "wewnętrzne" [linkowanie] między "trasami" SPA
Powinieneś stworzyć przejrzystą strukturę wewnętrznych linków między wszystkimi trasami w aplikacji jednostronicowej, aby poprowadzić roboty indeksujące przez witrynę.
W przeciwieństwie do "tradycyjnych stron internetowych", SPAs polegają na "nawigacji po stronie klienta", co może uniemożliwić wyszukiwarkom odkrycie wszystkich wewnętrznych stron, jeśli "linki" nie są dodane poprawnie.
Używaj znaczników "anchor" z właściwymi atrybutami "href", które odzwierciedlają rzeczywistą ścieżkę, a nie tylko funkcje JavaScript lub przyciski. Unikaj używania elementów takich jak [obsługiwacze] onClick bez znaczących adresów URL, ponieważ są one ignorowane przez roboty indeksujące (najczęściej).
Powinieneś upewnić się, że każda "ważna" strona jest "połączona" z innymi częściami aplikacji, zwłaszcza ze stroną główną i stronami o wysokim autorytecie. Pomaga to przekazywać sygnały istotności i autorytetu dla efektywnego indeksowania.
Utrzymuj logiczną hierarchię z menu nawigacyjnymi, "okruszkami chleba" i linkami kontekstowymi między powiązanymi widokami. Używaj opisowego tekstu kotwicy, aby wzmocnić tematy stron.
"Linkowanie wewnętrzne" poprawia głębokość indeksowania, "rozdziela autorytet", i wzmacnia ogólną wydajność [optymalizacji] pod kątem wyszukiwarek w całej aplikacji.
Użyj mapy witryny, która odzwierciedla [wszystkie] [ważne] trasy
Powinieneś wygenerować i przesłać mapę witryny, która zawiera każdą ważną trasę w aplikacji jednostronicowej.
Ponieważ SPAs używają routingu po stronie klienta, wiele [wewnętrznych] widoków może nie być możliwych do [odkrycia] za pomocą tradycyjnego indeksowania.
Utwórz mapę witryny XML, która wymienia wszystkie statyczne i dynamiczne trasy przeznaczone do indeksowania. Uwzględnij tylko czyste, kanoniczne adresy URL bez zbędnych parametrów, fragmentów lub danych sesji.
Powinieneś zaktualizować mapę witryny, gdy nowe "trasy" są dodawane, usuwane lub zmieniane. Narzędzia automatyzacji mogą regenerować mapę witryny podczas każdego wdrożenia, aby była "dokładna".
Prześlij "mapę witryny" w Google Search Console, aby pomóc wyszukiwarkom w znalezieniu i priorytetyzacji kluczowej zawartości. To wspiera [kompletne] pokrycie indeksu i wzmacnia widoczność na poziomie trasy.
Dobrz[e] utrzymana mapa strony poprawia wydajność indeksowania i zapewnia, że krytyczne widoki otrzymują potrzebną uwagę.
Monitoruj "zachowanie" "crawlowania" za pomocą "logów" serwera
Powinieneś analizować dzienniki serwera, aby zrozumieć, jak wyszukiwarki wchodzą w interakcje z Twoją "Single Page Application".
Logi ujawniają, które trasy są "crawlowane", jak często są [odwiedzane], oraz czy boty napotykają [błędy] lub opóźnienia.
Przejrzyj kody statusu HTTP, agenty użytkownika i znaczniki czasu, aby wykryć luki w indeksowaniu lub nieefektywności w indeksowaniu.
Szukaj oznak [przegapionej] zawartości, [powtarzających się] odwiedzin nieistotnych stron lub [nieudanych] odpowiedzi, które mogą zaszkodzić widoczności.
Powinieneś śledzić, jak Googlebot nawigować przez "dynamiczne trasy" i weryfikować, czy "ważne widoki" otrzymują uwagę do "crawlowania". Połącz dane logów z wglądami z narzędzi takich jak Google Search Console, aby sprawdzić pokrycie indeksowania.
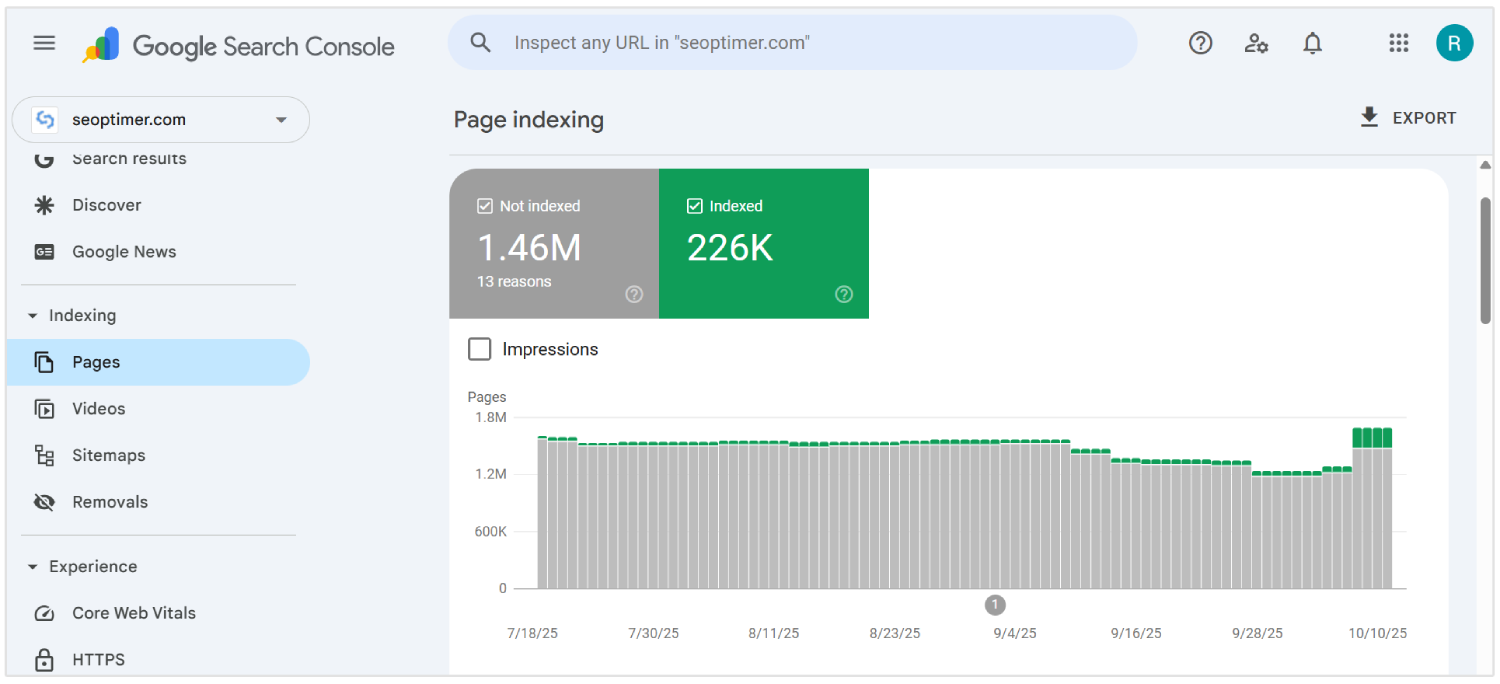
Użyj narzędzi do analizy dzienników serwera lub wyeksportuj dane z [Twojego] środowiska serwerowego NodeJS, aby uzyskać głębszą widoczność.
Monitorowanie aktywności botów w czasie rzeczywistym pomaga zidentyfikować "crawl waste", naprawić problemy z [odkrywalnością] i zoptymalizować ogólną wydajność SEO SPA.
Rozwiązywanie problemów z renderowaniem "dynamicznej zawartości"
Powinieneś rozwiązać problemy z renderowaniem w aplikacjach jednostronicowych, aby upewnić się, że dynamiczna treść jest w pełni widoczna dla wyszukiwarek.
"Treść", która zależy od "wykonania JavaScript", może nie pojawić się podczas "crawlowania", jeśli ładuje się zbyt późno lub wymaga interakcji użytkownika.
Skontroluj każdą trasę, aby potwierdzić, że "ważny tekst", "linki" i "nagłówki" są dostępne w wyrenderowanym wyniku. Używaj narzędzi takich jak Google’s URL Inspection Tool lub Lighthouse, aby wykryć "treści" brakujące w początkowym renderowaniu.
Należy stosować techniki takie jak "renderowanie po stronie serwera" lub "wstępne renderowanie", aby dostarczać w pełni zbudowane strony tam, gdzie jest to potrzebne.
W przypadku renderowania po stronie klienta, upewnij się, że dane ładują się szybko i nie polegają na opóźnionych "wyzwalaczach".
Unikaj wstrzykiwania krytycznych informacji po tym, jak crawler już przetworzył stronę. Opóźnienia w renderowaniu mogą prowadzić do częściowego indeksowania lub wykluczenia z wyników wyszukiwania.
Rozwiązanie problemów z renderowaniem zapewnia pełną widoczność "kluczowych treści", wspiera lepsze indeksowanie i wzmacnia ogólne wyniki optymalizacji pod kątem wyszukiwarek dla SPAs.
Dopasuj wykonanie JavaScript do możliwości "crawlera"
Powinieneś zorganizować wykonywanie JavaScript, aby pasowało do limitów przetwarzania nowoczesnych crawlerów, szczególnie kolejki renderowania Googlebot i ograniczeń zasobów.
Crawlers działają z ograniczeniem czasowym dla każdego URL. W związku z tym nadmierne łańcuchy zależności, asynchroniczne pobieranie danych lub logika blokująca renderowanie mogą skutkować niekompletnym indeksowaniem [kluczowych] stron.
Priorytetem jest renderowanie zawartości "ścieżki krytycznej" podczas początkowej fazy "malowania". Unikaj zagnieżdżonych warstw "nawadniania", opóźnionych mutacji "DOM" lub nadmiernego użycia komponentów przeznaczonych wyłącznie dla klienta.
Zastąp "wstrzykiwanie zawartości w czasie wykonywania" danymi pobranymi z serwera lub układami szkieletowymi, gdzie pełny HTML serwera nie jest wykonalny.
Należy przeprowadzić audyt czasu wykonywania za pomocą narzędzi takich jak Chrome DevTools Performance panel i symulować warunki działania crawlerów z użyciem Puppeteer lub bezgłowymi rendererami NodeJS.
Śledź czas do interaktywności (TTI), największe wyrenderowanie treści (LCP) i całkowity czas blokowania (TBT) w warunkach bez pamięci podręcznej.
Upewnij się, że "metadane" specyficzne dla trasy, "tagi kanoniczne" i "schemat" są montowane synchronicznie. Zmniejsz zależność od ciężkich bibliotek lub frameworków trasowania czasu wykonania, które opóźniają [znaczący] wynik renderowania.
Audytuj "SEO Performance" za pomocą specjalistycznych narzędzi
Powinieneś regularnie sprawdzać "wydajność" [optymalizacji] "wyszukiwarek", aby wykrywać problemy z [widocznością] w "aplikacjach jednostronicowych".
Standardowe kontrole przeglądarkowe pomijają problemy unikalne dla środowisk o dużym obciążeniu JavaScript.
Używanie zaawansowanych narzędzi zapewnia dogłębną widoczność tego, jak strony są renderowane, indeksowane i oceniane przez wyszukiwarki.
SEOptimer to jedno z narzędzi, które wykonuje kompleksowe audyty w warstwach "technicznej", "na stronie" i "wydajnościowej".
Skanuje każdą stronę pod kątem "jakości metadanych", "responsywności mobilnej", "struktury linków wewnętrznych" i "stosunku treści do kodu".
Dla "SPA", SEOptimer pomaga zidentyfikować brakujące elementy "HyperText Markup Language", nieprawidłowo skonfigurowane tagi kanoniczne i słabe struktury nagłówków, które wpływają na [crawlability].
Powinieneś uruchamiać audyty SEOptimer po wdrożeniu dużych aktualizacji lub uruchomieniu nowych tras. Narzędzie oznacza "opóźnienia renderowania", "uszkodzone linki" i "zależności JavaScript", które uniemożliwiają prawidłowe ładowanie zawartości.
Połącz SEOptimer z narzędziami takimi jak Google Search Console i analizatory logów, aby [zweryfikować] wyniki w rzeczywistych warunkach indeksowania.
Regularny "audyt" zapewnia, że logika routingu, dostarczanie treści i zachowania renderowania wspierają utrzymanie wydajności SEO.
Dlaczego SEO jest trudne dla "SPA"
SEO jest trudne dla aplikacji jednowarstwowych, ponieważ "metadane", "treść specyficzna dla trasy" i właściwe "kody statusu" mogą zostać pominięte lub źle zrozumiane przez "crawlery".
Oto najważniejsze wyzwania SEO dla SPAs:
1. Renderowanie po stronie klienta
Wyszukiwarki oczekują, że "znacząca treść" będzie obecna w początkowej odpowiedzi HTML. SPAs polegają na JavaScript do renderowania treści po załadowaniu strony, co opóźnia "widoczność".
Jeśli crawler uzyskuje dostęp do strony przed zakończeniem renderowania, kluczowe elementy, takie jak tekst i linki, mogą nie zostać przetworzone. To stwarza ryzyko indeksowania przez wyszukiwarki niekompletnych lub pustych stron.
W rezultacie, "content" który użytkownicy mogą zobaczyć, nigdy nie trafia do wyników wyszukiwania.
2. Ograniczenia "crawlingu"
SPAs nie "udostępniają" wszystkich stron za pomocą tradycyjnych statycznych linków, co sprawia, że "przeszukiwanie" jest bardziej złożone.
Wiele stron jest dostępnych tylko poprzez wewnętrzną nawigację po stronie klienta, której boty wyszukiwarek mogą nie śledzić.
Nawet nowoczesne crawlery, takie jak Googlebot, renderują JavaScript z opóźnieniami i ograniczonym czasem przetwarzania. Strony, które wymagają wielu cykli renderowania lub zagnieżdżonego pobierania danych, mogą przekroczyć [budżet] [crawl].
"Ważne widoki" mogą zostać całkowicie pominięte, osłabiając [widoczność] witryny w wynikach wyszukiwania.
3. Dynamiczne zarządzanie metadanymi
Każdy widok w SPA nie ma unikalnych metadanych, chyba że jest skonfigurowany ręcznie.
Bez dynamicznych aktualizacji "tytułów", "opisów" i "tagów kanonicznych", wszystkie URL-e wyglądają identycznie dla wyszukiwarek.
To prowadzi do błędów indeksowania, zmniejszonej [trafności] i niższych [współczynników kliknięć].
Metadane powiązane ze zmianami URL muszą być wstrzykiwane w "czasie rzeczywistym" przy użyciu bibliotek lub "logiki" niestandardowej. Niezarządzanie tym blokuje aplikację przed prawidłowym [rankowaniem] w różnych zapytaniach wyszukiwania.
4. "Niestandardowe" struktury URL
SPAs mogą używać URL-i, które zależą od fragmentów "hash" lub manipulacji historią przeglądarki. Te formaty mogą powodować zamieszanie dla wyszukiwarek, które preferują czyste, kanoniczne ścieżki.
Jeśli "trasa" [brakuje] "odpowiednia struktura", [może] nie być indeksowana lub może być traktowana jako duplikat.
Niespójne adresy URL również niszczą "deep linking", co jest krytyczne dla nawigacji użytkownika i głębokości przeszukiwania.
Wydajność "SEO" cierpi, gdy boty nie mogą interpretować lub uzyskać dostępu do rzeczywistych, odrębnych "URL".
5. Nieprawidłowe kody statusu HTTP
W przeciwieństwie do tradycyjnych stron, SPAs odpowiadają kodem 200 OK nawet dla [nieistniejących] tras.
To wprowadza w błąd wyszukiwarki, indeksując "strony błędów" lub [nieistotną] treść.
Bez poprawnych kodów, takich jak 404 "Nie znaleziono" lub 301 "Przekierowanie", roboty indeksujące nie mogą usuwać [przestarzałych] stron ani podążać nowymi ścieżkami.
Boty wymagają dokładnych sygnałów [statusu], aby zinterpretować strukturę [strony] i zmiany [zawartości].
SPA, które "nieprawidłowo obsługują" te odpowiedzi, "tracą kontrolę" nad tym, jak ich zawartość pojawia się w wynikach wyszukiwania.
6. Brak Przeładowań Strony Podczas Nawigacji
W SPAs, zmiany "tras" odbywają się w przeglądarce bez przeładowania strony. To zapobiega rozpoznawaniu przez wyszukiwarki zdarzeń nawigacyjnych jako nowych stron.
Boty mogą zakładać, że użytkownik nadal znajduje się na tej samej stronie, co ogranicza indeksowanie nowych widoków.
W przeciwieństwie do witryn wielostronicowych, SPAs muszą symulować te "przejścia", aby narzędzia SEO mogły je wykryć. Bez tego, treść specyficzna dla "tras" jest pomijana lub błędnie klasyfikowana.
7. "Opóźnione Renderowanie Treści"
SPAs opóźniają "widoczną treść" z powodu wielu zależności JavaScript i asynchronicznego ładowania.
Z tego powodu roboty wyszukiwarek mogą przetwarzać stronę, zanim pojawią się "istotne dane".
Długie czasy renderowania mogą skutkować [częściowym] indeksowaniem, brakującymi [nagłówkami] i niekompletnymi podsumowaniami [stron].
Jeśli "znacząca treść" nie jest gotowa podczas indeksowania, wyszukiwarki zakładają, że strona nie ma wartości lub mogą uznać stronę za ""ubogą treść.""
To ostatecznie zmniejsza "rankingi", "widoczność" i "ruch".
Wniosek
"Uzyskanie" SEO "dla aplikacji jednostronicowych nie jest proste."
Wyszukiwarki muszą zobaczyć "rzeczywistą treść" natychmiast, a nie czekać, aż skrypty ją załadują po fakcie. Dlatego powinieneś wysyłać poprawny HTML, traktując każdą trasę jak "prawdziwą stronę", i aktualizować "tytuły" i "opisy" w miarę poruszania się użytkownika przez aplikację.
Musisz również zarządzać [kodami] statusu, budować wewnętrzne [linki], dodawać [ustrukturyzowane dane] i upewnić się, że wyszukiwarki mogą przeszukiwać każdą część witryny. Kiedy wszystko jest na miejscu, twoja "aplikacja" jednostronicowa staje się łatwiejsza do zaindeksowania i łatwiejsza do wypozycjonowania.