Você sabe quando você usa o Google para pesquisar por um serviço, ou encontrar informações? E assim que a página carrega, sempre há um site no topo.
Sites na posição 1 na página de resultados do mecanismo de busca do Google (SERP) recebem a maioria de todos os cliques. Portanto, nem é preciso dizer que é importante seguir as "melhores práticas" de SEO para tentar maximizar a posição do seu site no SERP.
Mas você sabe como o Google encontra seu site em primeiro lugar?
A resposta é os crawlers do Google. Os crawlers do Google são como pequenos robôs digitais que visitam sites e coletam informações sobre esses sites.
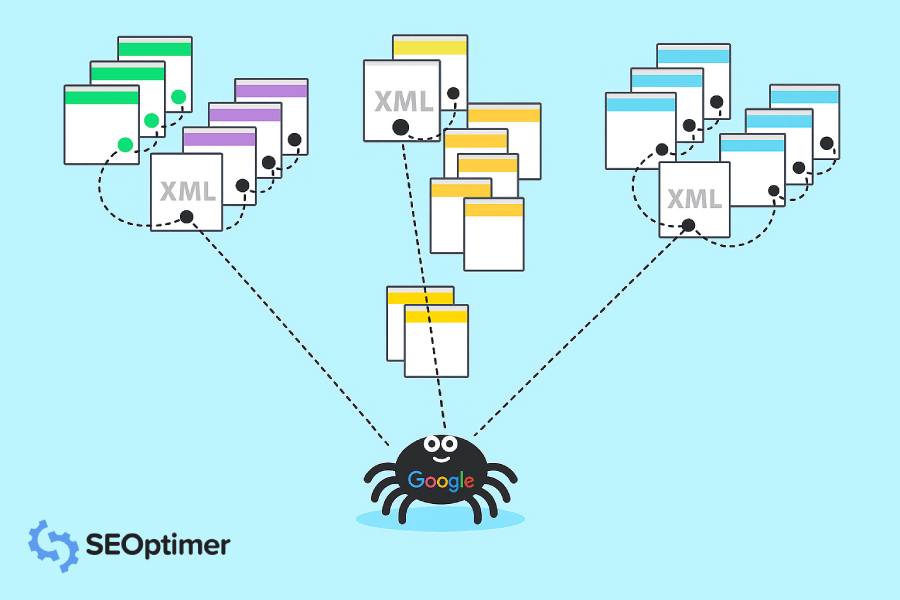
Em seguida, o Google indexa todas essas informações e as utiliza para melhorar seu algoritmo de busca. Quando alguém digita uma consulta no Google, o algoritmo de busca examina todas as informações indexadas para encontrar os melhores resultados para a consulta da pessoa.
E é assim que o Google consegue trazer para você os melhores resultados quando você busca por algo na internet!
O que é um Google Crawler?
Um Google Crawler também é conhecido como “robô” ou “aranha,” (entendeu, porque eles rastejam) e eles vão de site em site à procura de novas [informações] para armazenar em seus bancos de dados. Existem 15 tipos de crawlers que são usados pelo Google, mas o mais importante é o Googlebot.

Embora o Google seja poderoso, ele não pode "fazer" tudo; cada vez que uma nova página da web é criada, o Google não sabe sobre ela até que essa página tenha sido rastreada.
Google usa o Googlebot para constantemente obter as "últimas informações" para armazenar em seu banco de dados.
Indexação do Google vs Rastreamento do Google
A "indexação" [only] acontece [after] o site ter sido rastreado pelo GoogleBot. Quando é rastreado, ele é analisado, e as informações analisadas a partir desse site ou página são armazenadas no índice do Google.
O índice irá categorizar e classificar as páginas de acordo nos resultados da "pesquisa".
Por que os Rastreadors do Google são Importantes?
Então por que tudo isso é "importante"?
Bem, digamos que você dirige um negócio e tem um site. Você quer que seu site esteja o mais próximo possível do topo. Se o seu site não for "crawled" e "scanned", ele não carregará na página de busca.
Sem qualquer presença na internet, você não conseguirá alcançar seu público ou consumidores. "Crawling" e "indexação" tornam um pouco mais fácil para os sites obterem alguma atenção.
Como um "Crawler" do Google Funciona
Então, você sabe o que é, mas como isso funciona? Embora o Google seja poderoso, ele não pode "fazer" tudo. Cada vez que uma nova página da web é criada, o Google não sabe sobre ela até que essa página tenha sido rastreada. O Google usa o Googlebot para constantemente obter "informações" adicionais para armazenar em seu banco de dados.
Assim que essa página da web é rastreada ou escaneada. A página é renderizada e recebe um código HTML, CSS, JavaScript e de terceiros, todos os quais são necessários para o Googlebot indexar e classificar sites. O Googlebot, o maior rastreador, é capaz de ver e renderizar todas as páginas e sites com Chromium.
O Chromium está sempre se atualizando para que possa permanecer estável e desempenhar sua função com precisão. Isso está disponível para todos e também pode ser usado para testar "novas" [funcionalidades] e criar novos navegadores.
Como "fazer" seu site ser mais fácil de rastrear
Agora que sabemos com o que estamos "trabalhando", vamos trabalhar para tornar seu website fácil de ser rastreado.
Aqui estão algumas dicas e truques para fazer do seu site um ímã de rastreadores e subir ao topo na página de resultados de pesquisa.
Links Internos
Links internos podem ser seus melhores amigos para [rastreamento]. Seu site pode já ter sido rastreado pelo Google no passado, mas recentemente você pode ter adicionado mais páginas. Se o [rastreador] já conhece seu website, ele se concentrará apenas nas páginas principais.
Lembre-se, o Google não é alertado toda vez que uma nova página é criada, ele faz a "varredura" para encontrar essas páginas.
Usar "links internos" nas "páginas principais" guia o rastreador para onde ele precisa ir. O melhor lugar para esses links internos é a sua "homepage", é a página que recebe mais tráfego e onde o rastreador irá escanear primeiro.
Backlinks
Backlinks são outra ótima maneira de fazer com que seu site seja rastreado. Este método pode ser usado para “promover” seu site para o rastreador.
Vincular a um site mais popular aumentará suas chances de ser descoberto pelo "crawler".
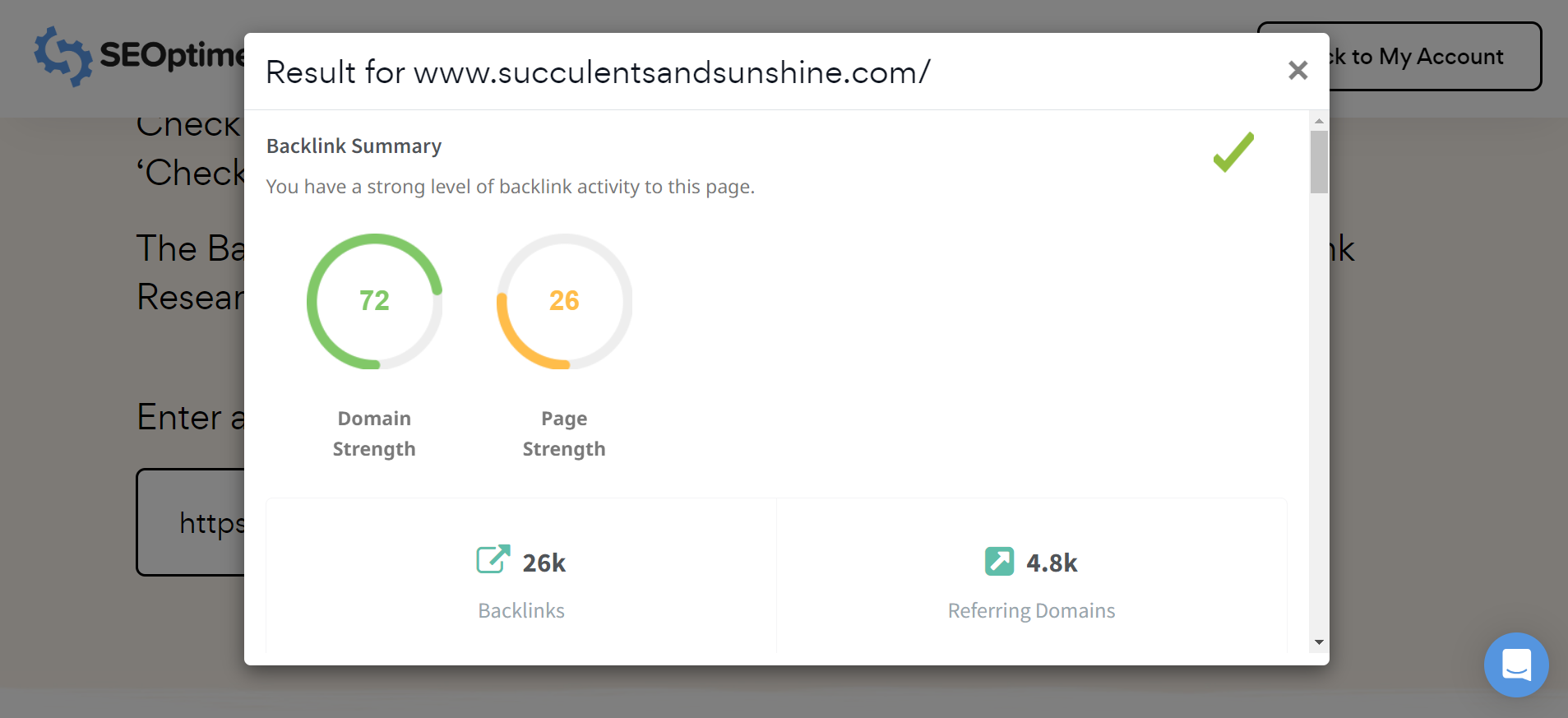
Nota: Você pode facilmente verificar o perfil de backlinks de qualquer site, incluindo seus concorrentes, usando a ferramenta gratuita de Pesquisa de Backlinks do SEOptimer.
Imagens
Imagens podem ser rastreadas, na verdade, há um rastreador específico apenas para imagens. Este rastreador é conhecido como Googlebot Image, e ele coleta imagens para o banco de dados.
Mapas do site
Há uma maneira de informar ao Google quais páginas você deseja que eles rastreiem de forma mais direta. Você pode enviar um mapa do site com uma lista detalhada das páginas que você deseja que sejam rastreadas pelo Google.
Use nosso Gerador de Sitemap XML para criar um "sitemap" de todo o seu site. Crie-o, nomeie-o. E faça o download para o seu computador para enviar ao Google Search Console.
"Profundidade de Clique"
"Profundidade de clique" (também conhecida como "profundidade de rastreamento") mostra quanto trabalho um rastreador teria que fazer para alcançar e escanear sua página. Você nunca quer que o rastreador tenha que fazer muito trabalho, você quer que sua página ou site seja o mais amigável possível para os rastreadores.
Deve levar cerca de três cliques ou menos, quanto mais demorar, mais ele desacelera o rastreador.
Uma boa estrutura deve permitir que você adicione novas páginas sem influenciar sua "profundidade de clique". O rastreador também deve ser capaz de acessar essas páginas facilmente.
[Para sua informação]: Uma boa regra prática é garantir que você possa navegar de uma página em seu site para qualquer outra página em seu site com no máximo [3 cliques]. Isso garante que o Google possa encontrar e indexar todas as suas páginas de forma eficiente. Além disso, é ótimo para a experiência do usuário.
Instruções de Indexação
Existem instruções que o Google segue ao rastrear e criar páginas de ideação. Robots.txt, tag noindex, meta tag robots e X-Robots-Tag. Não se preocupe, vamos explicar isso para você.
Robots.txt. é um arquivo de diretório raiz que retém certas páginas e conteúdo do Google. Quando o rastreador está escaneando uma página, ele estará procurando por isso para obter informações. Se o rastreador não conseguir encontrar essas informações, ele interromperá sua varredura e a página não fará parte dos resultados de pesquisa.
A tag Noindex impede que todos os tipos de rastreadores possam escanear e indexar uma página.
A "meta tag" de robôs pode ajudar a controlar a forma como uma página deve ser indexada e carregada para os internautas nos resultados de pesquisa.
X-Robots-Tag, é uma parte do cabeçalho HTTP e ajudará a controlar o comportamento do "crawler". Ele supervisiona como toda a página é indexada. Você pode bloquear imagens e vídeos em uma página usando este método. Você também pode direcionar tipos de "crawlers" individualmente, mas apenas se isso for especificado.
Se o tipo de "crawler" não for especificado, as instruções serão para todos os "crawlers" do Google.
Estrutura de URL
Você pode ter ouvido isso antes, mas certifique-se de ter um URL "amigável" para o usuário.

Uma URL que seja fácil, uma que tanto seus consumidores quanto os algoritmos irão adorar. Tente manter sua URL o mais "curta" e "doce" possível.
Se você tem uma URL longa, pode ser confuso não apenas para o olho humano, mas para o bot do Google também.
Quanto mais confuso o Googlebot, mais ele irá esgotar seus recursos de rastreamento e isso definitivamente não é o que você quer.
Problemas Comuns (e Soluções) com Rastreamento do Google
Então, você tem uma página, mas ela não está desempenhando da maneira que você deseja. Isso pode ser porque o rastreador está tendo dificuldades para tentar escanear e indexar seu site.
Aqui estão alguns problemas comuns que as pessoas têm encontrado com o Rastreamento do Google.
1. O Google não está "crawling" seu "website"
Certifique-se de verificar se sua página ou site é amigável para rastreamento. Isso significa ter um bom URL, incorporar os links internos e backlinks se necessário, ou dedicar tempo para criar um mapa do site para mostrar ao Googlebot onde rastrear.
Além disso, tenha em mente que pode levar algum tempo para o Google rastrear e indexar seu site porque ele precisa "vir encontrar você"!
2. Você foi removido do índice do Google
O Google removerá um site se achar necessário, seja por lei, relevância ou por não seguir as diretrizes estabelecidas. Use nosso Rastreador de SEO para verificar qualquer coisa que possa estar bloqueando o rastreador da sua página.
Depois de fazer isso, você pode enviar seu site ao Google para "reconsideração" reconsideration.
3. Você tem "Conteúdo Duplicado"
Conteúdo duplicado é uma página que tem conteúdo semelhante a outra página ou múltiplos URLs vinculando a uma página.

No caso de ter páginas com conteúdo semelhante, o que também pode significar que você tem uma versão desktop e móvel de uma página. No entanto, o exemplo mais comum de "conteúdo duplicado" em várias páginas.
Estes podem ser evitados e corrigidos com uma URL canônica, ou URL que serve como representante para estas páginas duplicadas.
O Google só exibirá a página que eles acreditam ter o conteúdo mais útil e a rotulará como canônica. Esta é a página que será rastreada em vez dos duplicados.
Para evitar isso, considere reescrever o texto nestas páginas para que não sejam confundidas como [duplicatas].
4. Existem "Problemas" de "Renderização"
Se você estiver tendo problemas de "renderização", certifique-se de que sua codificação não seja muito grande. Sua codificação precisa ser o mais limpa possível para que o "crawler" possa renderizar tudo corretamente.
Se o "crawler" não puder renderizar a página, ela será considerada vazia.
Perguntas Frequentes do Google Crawler
Quanto tempo leva para o Google rastrear um site?
Normalmente, o Google leva de dias a semanas para rastrear. Você pode monitorar o rastreamento usando o "Relatório de Status do Índice" ou a ferramenta de inspeção de URL. Lembre-se, o Google não é notificado sempre que um novo site ou página é criado, ele precisa rastrear e encontrar.
[Para] sua informação: Sites [mais] populares são rastreados [mais] rapidamente. Sites [novos] geralmente [demoram] semanas para serem rastreados, enquanto sites respeitáveis como NY Times, Wall Street Journal e Wikipedia são rastreados várias vezes por dia.
O que é o algoritmo do "Google Crawler"?
O algoritmo do Google Crawler é baseado em quão amigável para rastreadores é o seu site. Isso inclui "palavras-chave", URLs, "conteúdo e informação", "codificação" e muito mais. Cabe a você fornecer ao Google o melhor "conteúdo e orientação" para que ele possa encontrar sua página e começar a rastrear.
Todas as páginas estão disponíveis para "crawling"?
Esta é uma "boa" pergunta. A resposta curta é [não]. Algumas páginas não podem ser rastreadas e indexadas porque estão protegidas por senha, foram especificamente excluídas das instruções de índice ou não têm nenhum link em suas páginas.
Quando meu site aparecerá na pesquisa do Google?
Isso sempre "variará" dependendo de quanto tempo leva para o seu site ser "crawled" e indexado. Isso pode levar apenas alguns dias ou até algumas semanas.
Quais outros "web crawlers" existem?
Sim! Existem muitos "web crawlers" além dos quinze do Google. Aqui estão alguns para referência:
- Existe o BingBot usado pelo mecanismo de busca Bing.
- SlurpBot, usado pelo Yahoo! Este rastreador da web é uma mistura entre Yahoo! e Bing, porque o Bing é a principal fonte do Yahoo!.
- ExaBot é o mecanismo de busca e rastreador mais popular na França.
- AppleBot é usado pela grande empresa de tecnologia Apple para buscas no spotlight e sugestões da Siri.
- O Facebook, acredite ou não, usa links para enviar conteúdo para outros perfis e só pode rastrear se fornecido um link.
Otimize Seu Site para Rastreamento do Google
Agora que você entende o básico de Google Crawling e como ele funciona, use-o a seu favor! Faça com que seu site seja indexado corretamente e suba para o topo da página inicial dos resultados de busca. É gratuito e está completamente à sua disposição.