SEO Crawler SEOptimer’a pomaga [skanować] i [audytować] [strony] na Twojej stronie internetowej, aby [zidentyfikować] techniczne problemy SEO na dużą skalę.
Zamiast sprawdzać strony pojedynczo, "crawler" przegląda strukturę Twojej witryny, analizuje elementy SEO na wielu URL-ach i podkreśla problemy, które mogą wpłynąć na [indeksowanie], użyteczność lub widoczność w wyszukiwarce.
W tym przewodniku, [będziesz]:
- Uruchom swoje pierwsze [crawl]
- [Przejrzyj] raport z [crawl]
- [Dowiedz się], jak [ustawić] niestandardowe zasady [crawl]
- [Zaplanuj] i [eksportuj] [crawl] strony internetowej
Czym jest "SEO Crawler" SEOptimer?
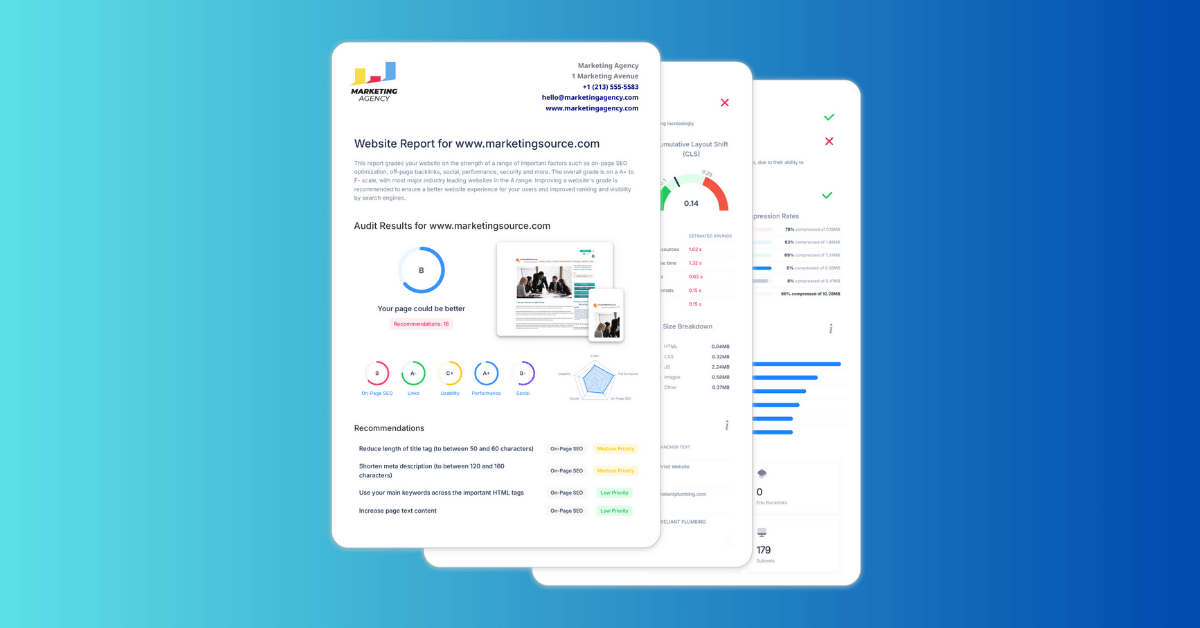
SEO Crawler SEOptimer’a to narzędzie do przeszukiwania stron internetowych, które skanuje strony twojej witryny i identyfikuje [problemy] związane z SEO na wielu URL.
Działa poprzez odwiedzanie stron na Twojej witrynie i zbieranie danych technicznych i dotyczących SEO na stronie, takich jak "tytuły stron", "opisy meta", "nagłówki", "kody statusu", "indeksowalność", "przekierowania" i "zepsute linki".
Po zakończeniu przeszukiwania, narzędzie generuje raport przeszukiwania, który podsumowuje "problemy" znalezione na Twojej stronie i grupuje je według "typu" i "stopnia ważności".
To "ułatwia" zauważenie "powtarzających się" problemów i [priorytetyzację] poprawek, zwłaszcza na większych stronach internetowych, gdzie ręczne sprawdzanie stron nie jest praktyczne.
"SEO Crawler" jest przydatny do przeprowadzania "technicznych audytów SEO", monitorowania [zdrowia] witryny w czasie oraz sprawdzania, czy kluczowe strony przestrzegają najlepszych praktyk SEO.
Jak uruchomić swoje pierwsze "crawl"
Aby uruchomić swoje pierwsze "crawl", kliknij opcję „Crawl witryny” w sekcji „Audytowanie” na pulpicie nawigacyjnym SEOptimer.
Następnie dodaj URL swojej strony internetowej do otwartego pola i kliknij “Dodaj Crawl.”
To już wszystko, rozpocząłeś swoje pierwsze [skanowanie] strony SEOptimer!
Nasz "SEO Crawler" przeanalizuje teraz wszystkie strony na Twojej witrynie, aby zidentyfikować wszelkie [problemy], jakie mogą występować.
Crawle są uruchamiane w [czasie] rzeczywistym, ale całkowity [czas] crawl będzie się różnić w zależności od rozmiaru Twojej strony internetowej i liczby stron, które muszą być przeskanowane.
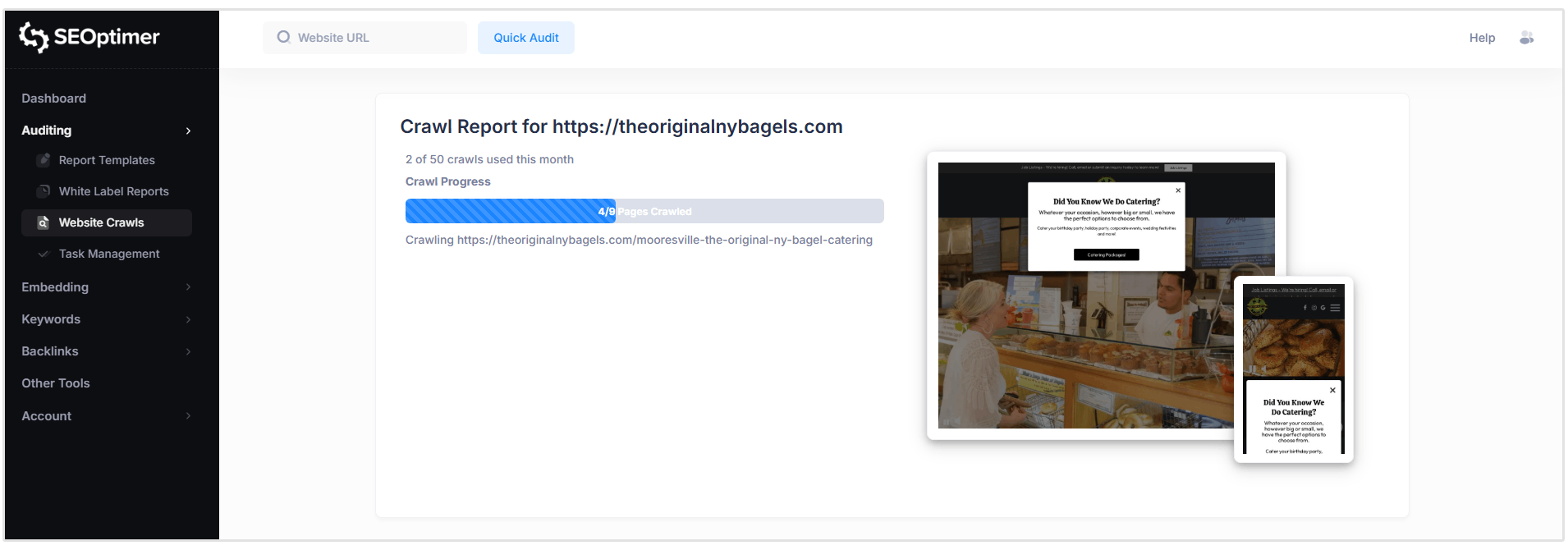
Podczas gdy "crawl" jest nadal uruchomiony, możesz zacząć przeglądać [problemy], gdy zostaną wykryte, otwierając raport z "crawl".
Co możesz "zobaczyć" w każdym [raporcie] z [pełzania]?
Gdy nasze narzędzie zakończy przeszukiwanie Twojej witryny, zobaczysz trzy główne sekcje:
- "Nagłówek raportu"
- "Zidentyfikowane strony"
- "Podsumowanie problemu"
Przejdźmy przez każdą z tych [sekcji].
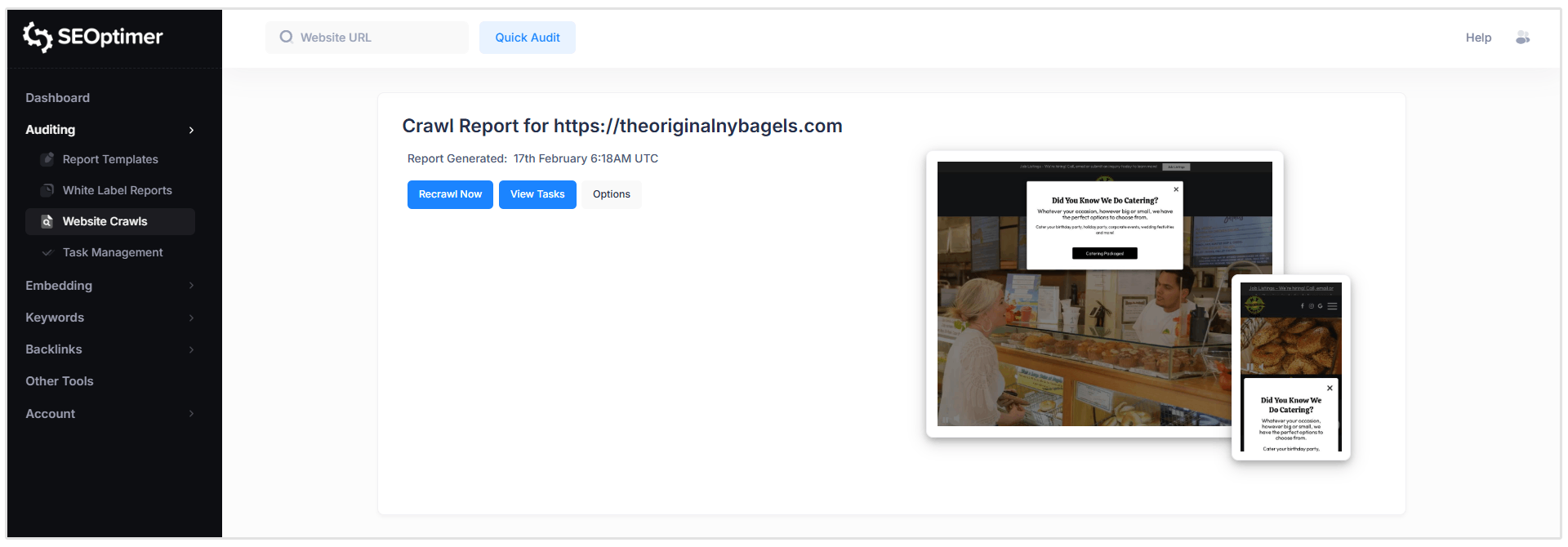
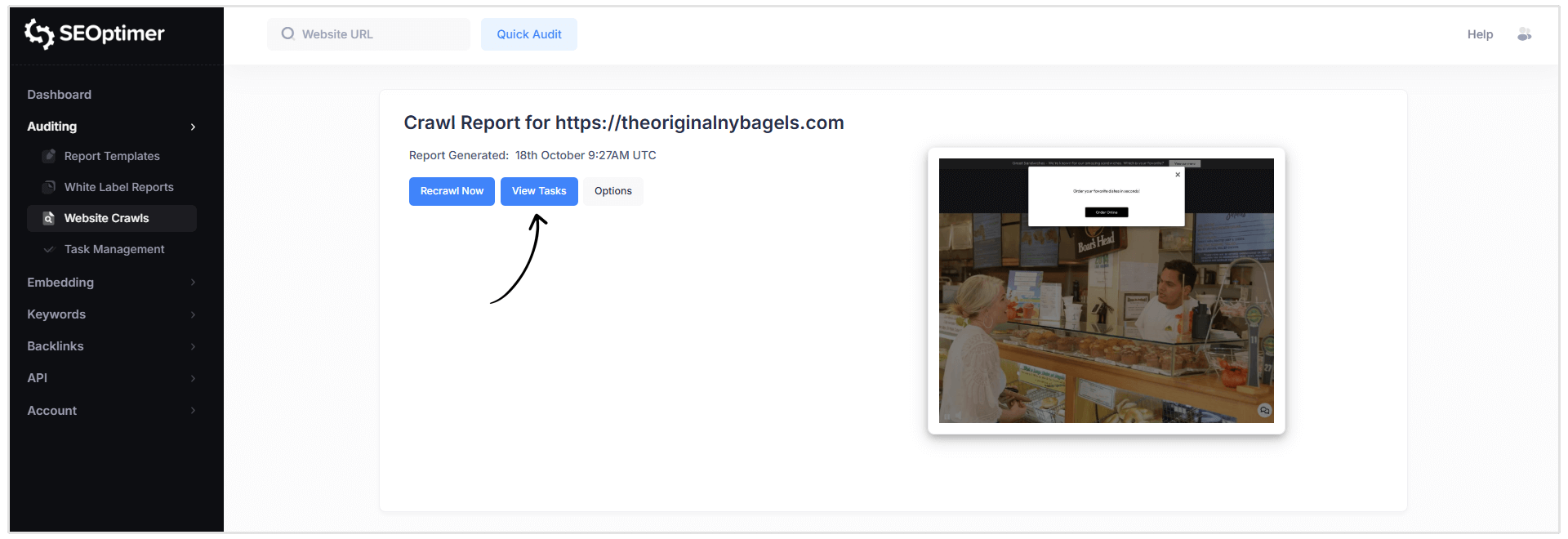
Raport [Nagłówek]
Tutaj możesz zobaczyć, kiedy raport został wygenerowany, poprosić o ponowne przeszukanie, wyświetlić zadania i dostosować zasady przeszukiwania. (więcej o tych funkcjach później)
Zidentyfikowane strony
Ta sekcja pokazuje tabelę wszystkich stron odkrytych podczas [crawl], wraz z wykrytymi problemami [SEO] dla każdej strony.
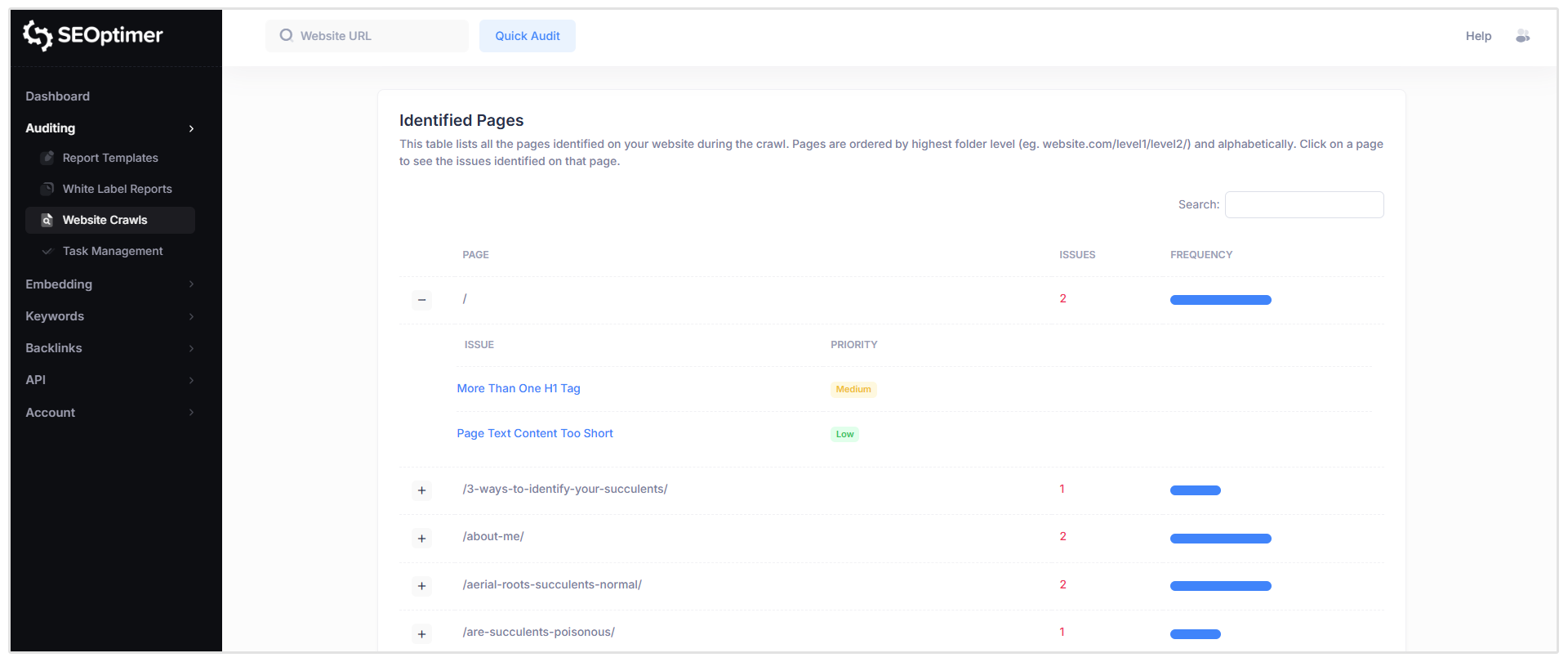
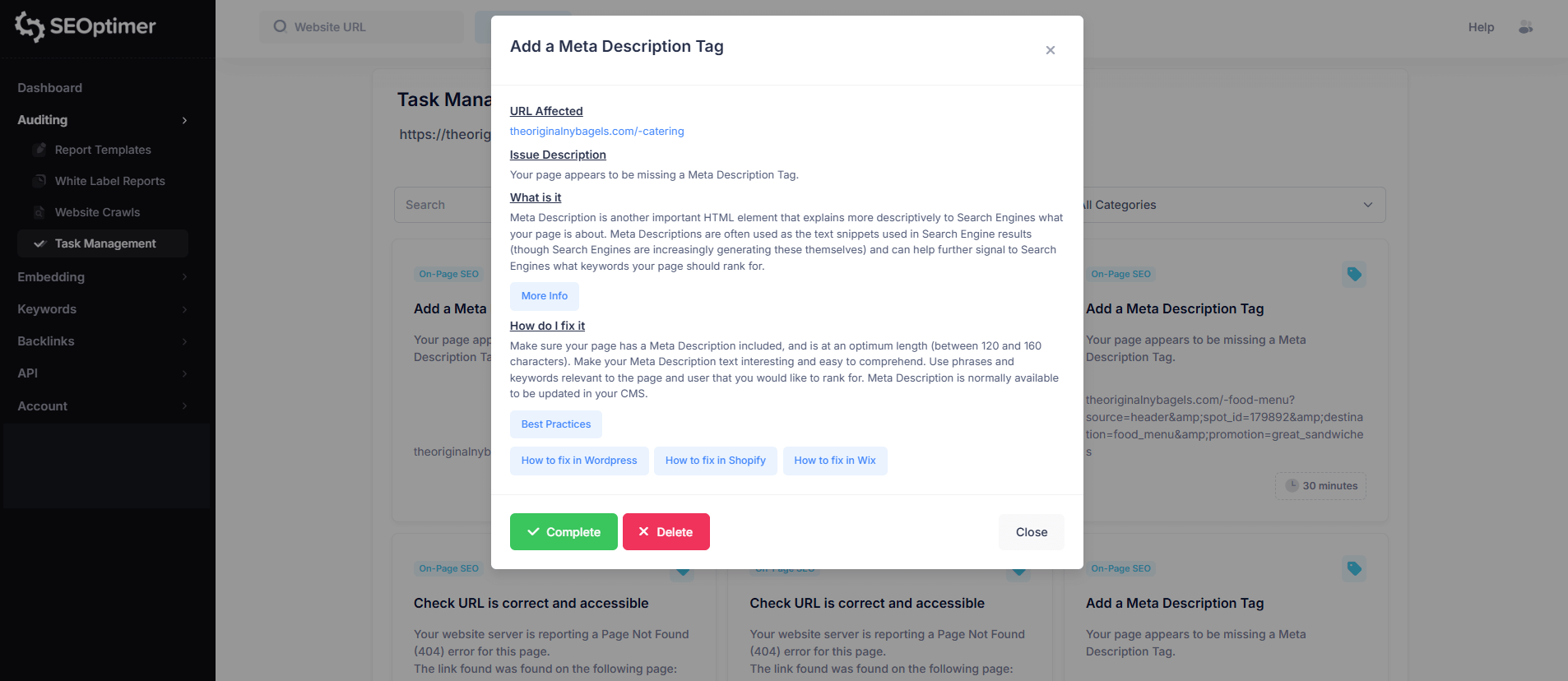
Kiedy klikniesz na określoną stronę (na przykład, główną ścieżkę strony startowej pokazaną jako “/”), zobaczysz listę wszystkich [problemów] oznaczonych dla tego URL, w tym poziom [ważności] każdego [problemu].
Aby [zobaczyć] więcej [szczegółów], kliknij dowolny [problem] na [liście].
Na przykład, wybranie “Więcej niż jeden tag H1” otworzy szczegółowy podział tego problemu dla wybranej strony.
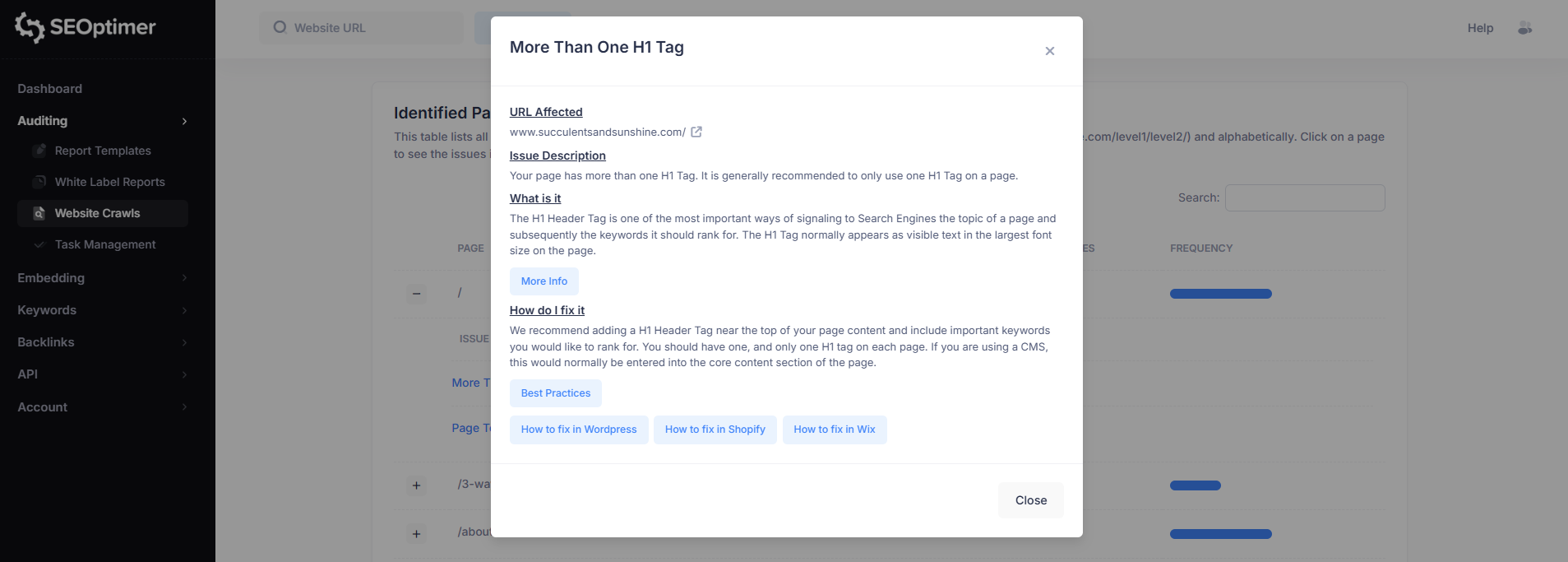
Ten widok "problemu" [zawiera]:
- "Dotknięty [URL]"
- "Opis problemu"
- "Co oznacza problem"
- "Jak go naprawić"
Każdy "pop-up" z problemem będzie również zawierał linki do wspierających przewodników, aby pomóc Ci rozwiązać [problem] na Twojej stronie internetowej.
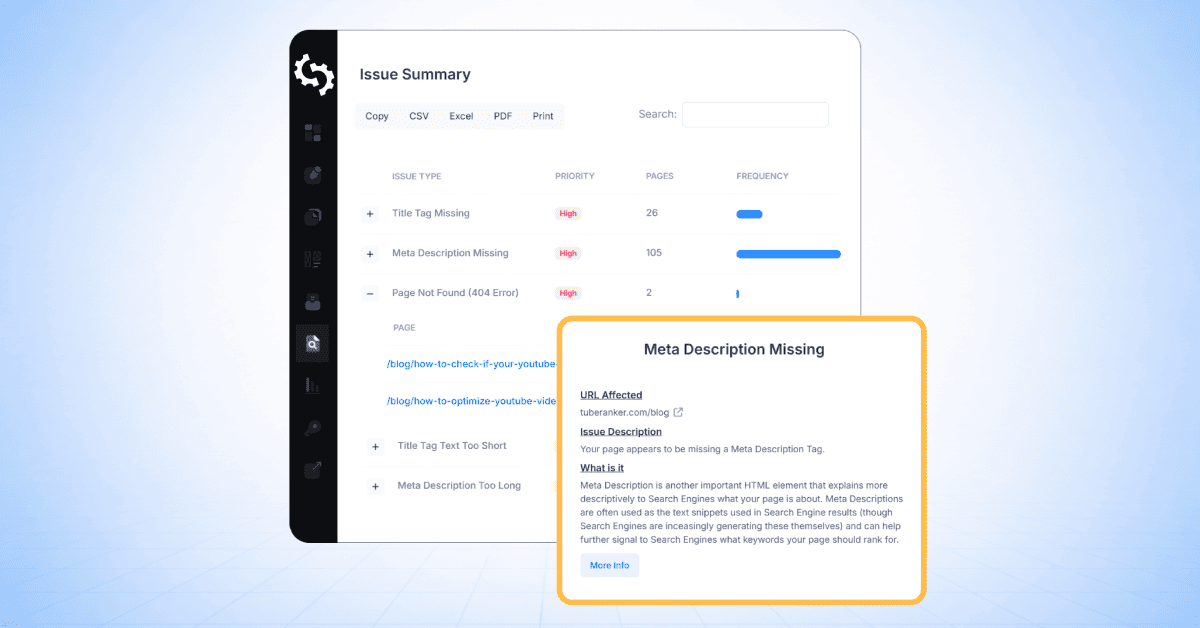
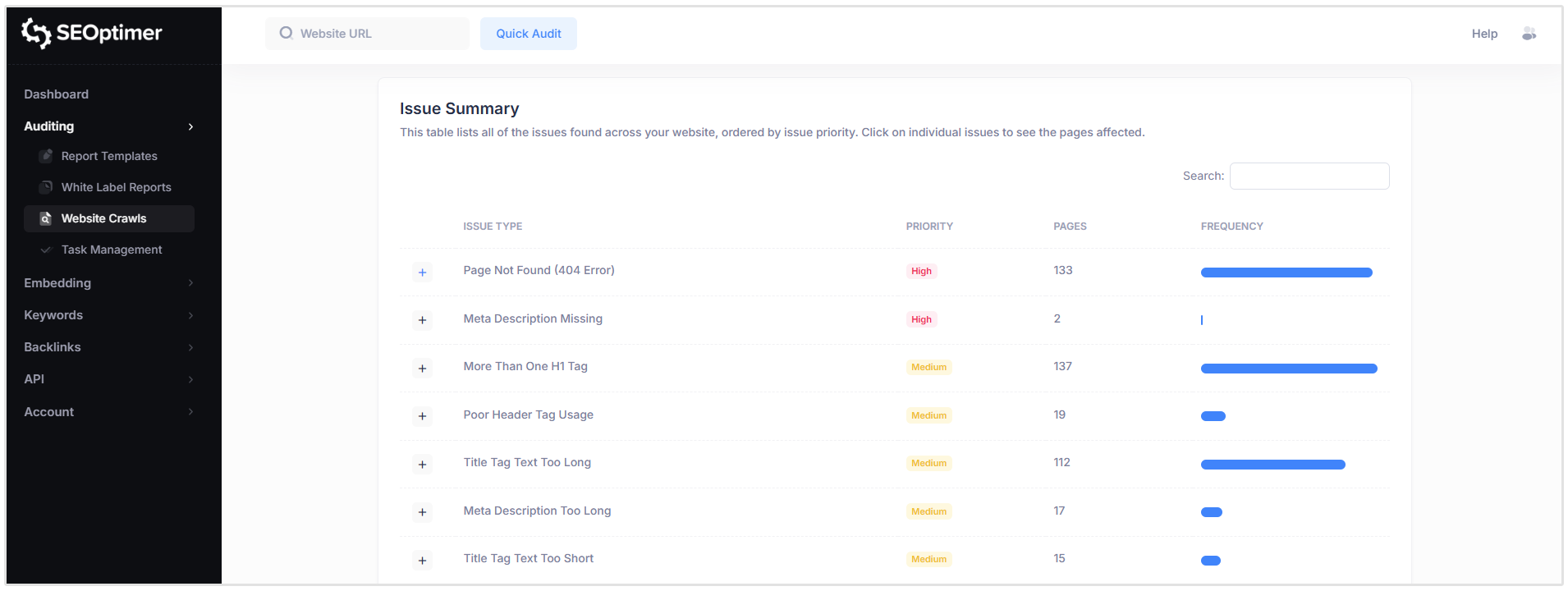
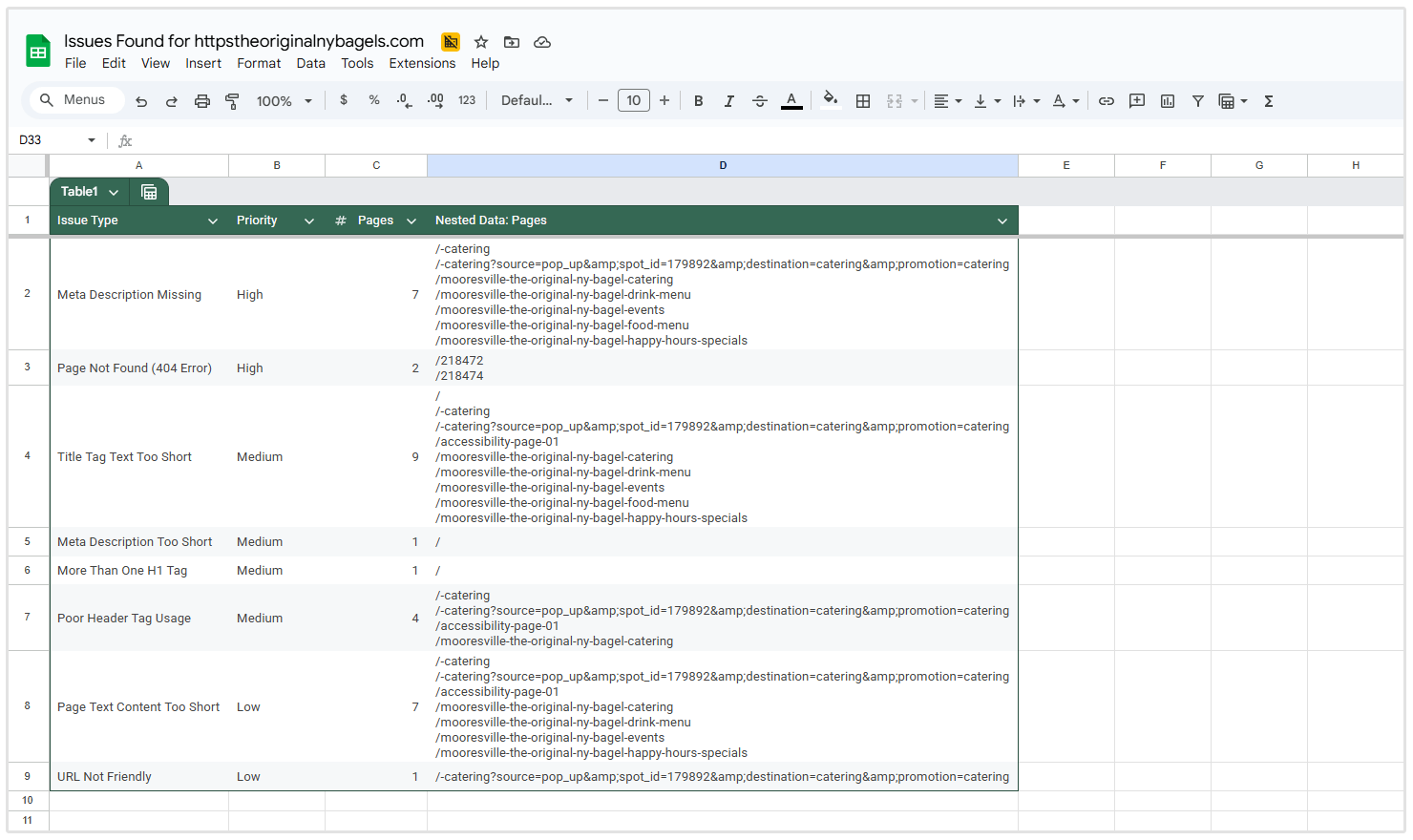
Podsumowanie problemu
Sekcja "Podsumowanie problemów" zapewnia przegląd wszystkich wykrytych problemów SEO na Twojej stronie internetowej, pogrupowanych według typu problemu i uporządkowanych według priorytetu.
Dla każdego "problemu", tabela pokazuje:
- Typ "problemu"
- Poziom "priorytetu"
- Liczba "dotkniętych" stron
Więc na poniższym zrzucie ekranu strony, którą przeszukałem, możesz zobaczyć, że jest 137 stron, które mają więcej niż jeden znacznik H1, 133 strony, które mają błędy 404 i 2 strony, które [nie] mają "opisu meta".
Gdy już zapoznasz się z podsumowaniem problemu, możesz przejść do "konfigurowania" ustawień indeksowania i "eksplorowania" dodatkowych opcji SEO Crawler.
Zobacz "zadania"
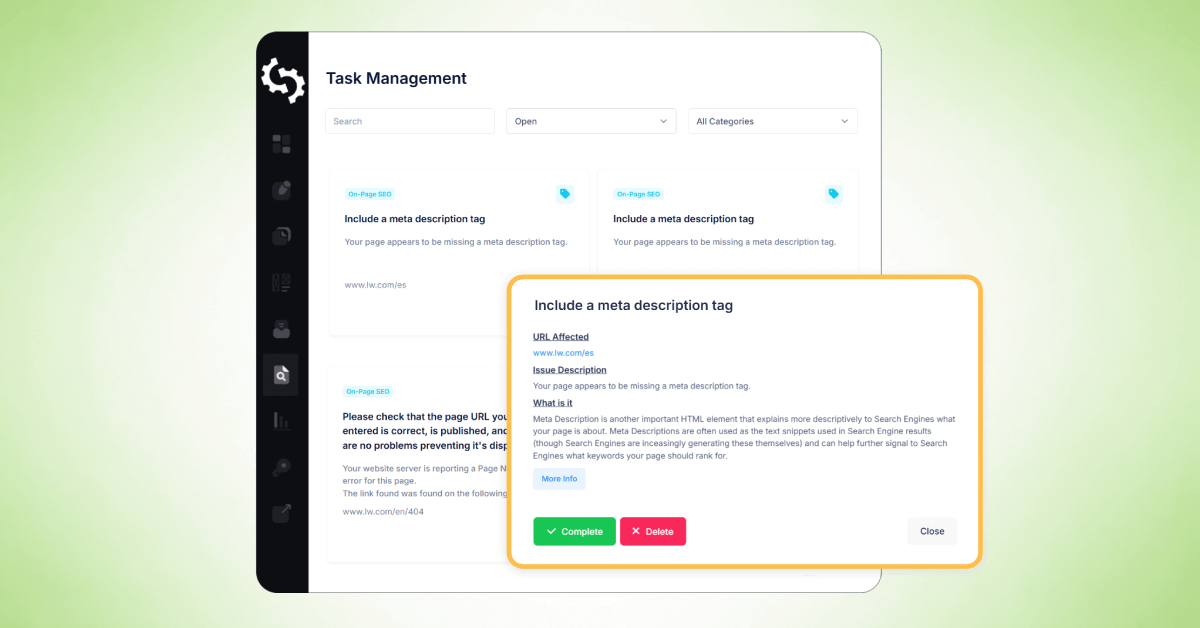
Po zakończeniu przeszukiwania strony internetowej, możesz użyć funkcji zarządzania zadaniami SEOptimer, aby zorganizować i śledzić "problemy" zidentyfikowane w [Twoim] raporcie z przeszukiwania.
Narzędzie do zarządzania zadaniami przekształca problemy z indeksowaniem w listę zadań, którą możesz przepracować w jednym miejscu pracy, co ułatwia priorytetyzację poprawek i śledzenie postępów w czasie.
Jak uzyskać dostęp do "Task List"
Możesz otworzyć swoją listę zadań na dwa sposoby:
- Kliknij niebieski przycisk „[Wyświetl] zadania” w nagłówku raportu Crawl.
- Lub wybierz [Zarządzanie zadaniami] z menu nawigacyjnego po lewej stronie w twoim pulpicie nawigacyjnym.
Uwaga: Jeśli przeszukałeś wiele stron internetowych, możesz przełączać się między listami zadań za pomocą menu rozwijanego u góry strony Zarządzanie zadaniami.
Filtrowanie i zarządzanie zadaniami
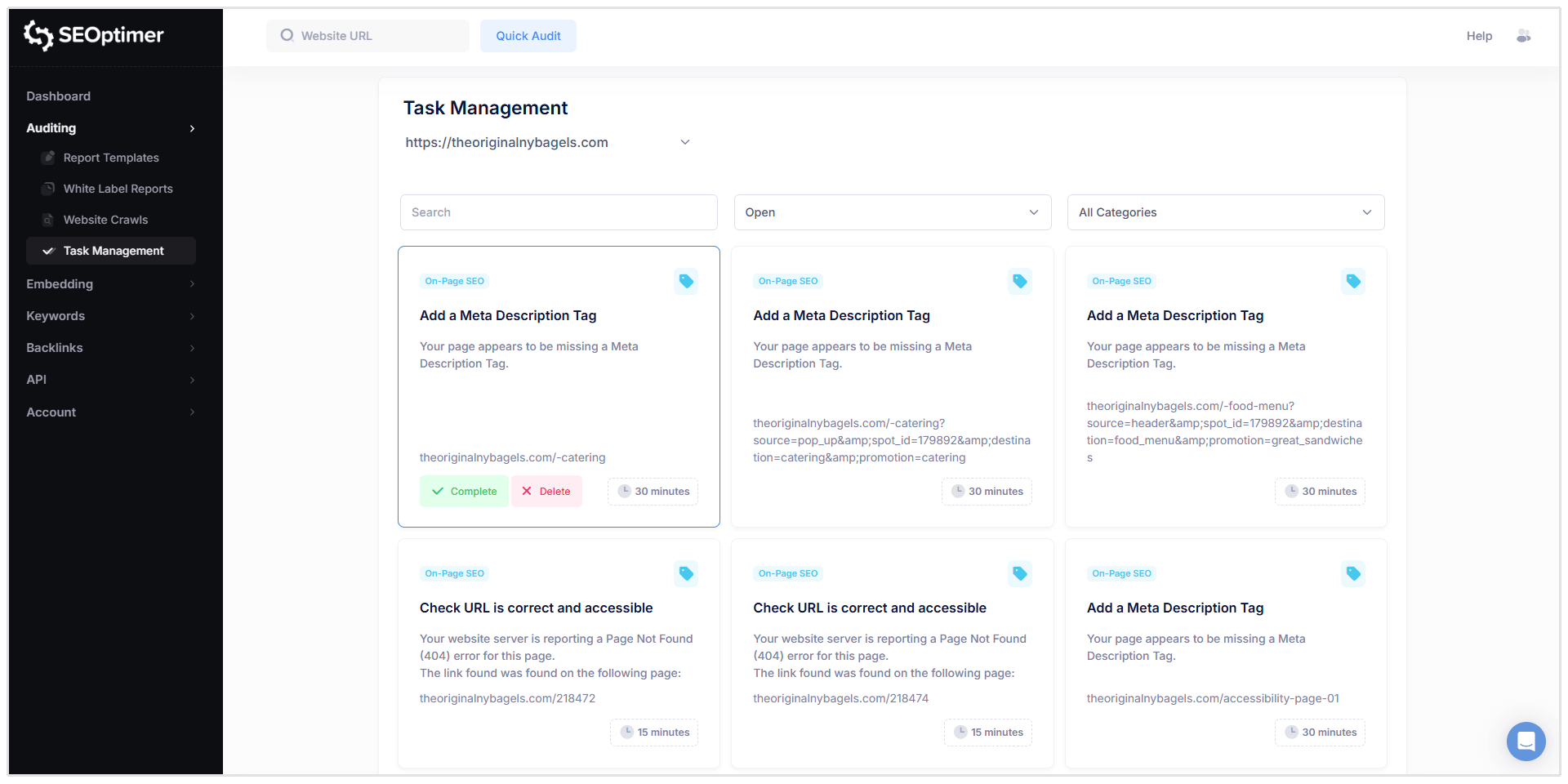
Zadania mogą być filtrowane według:
- Status ("Otwarte", "Zakończone", "Usunięte")
- Kategoria (np. "SEO na stronie", "Linki", itp.)
Kiedy klikniesz na zadanie, zobaczysz szczegółowe informacje podobne do raportu z indeksowania, w tym:
- Adres URL, którego dotyczy problem
- Opis problemu
- Co oznacza problem
- Jak to naprawić
- Opcje ukończenia zadania lub usunięcia go z listy zadań
Jak [zaplanować] "crawls"
Masz również możliwość zaplanowania [przeszukiwań] do uruchomienia na [tygodniowej] lub [miesięcznej] [bazie]. Ta [funkcja] jest szczególnie przydatna dla agencji zarządzających wieloma stronami internetowymi klientów.
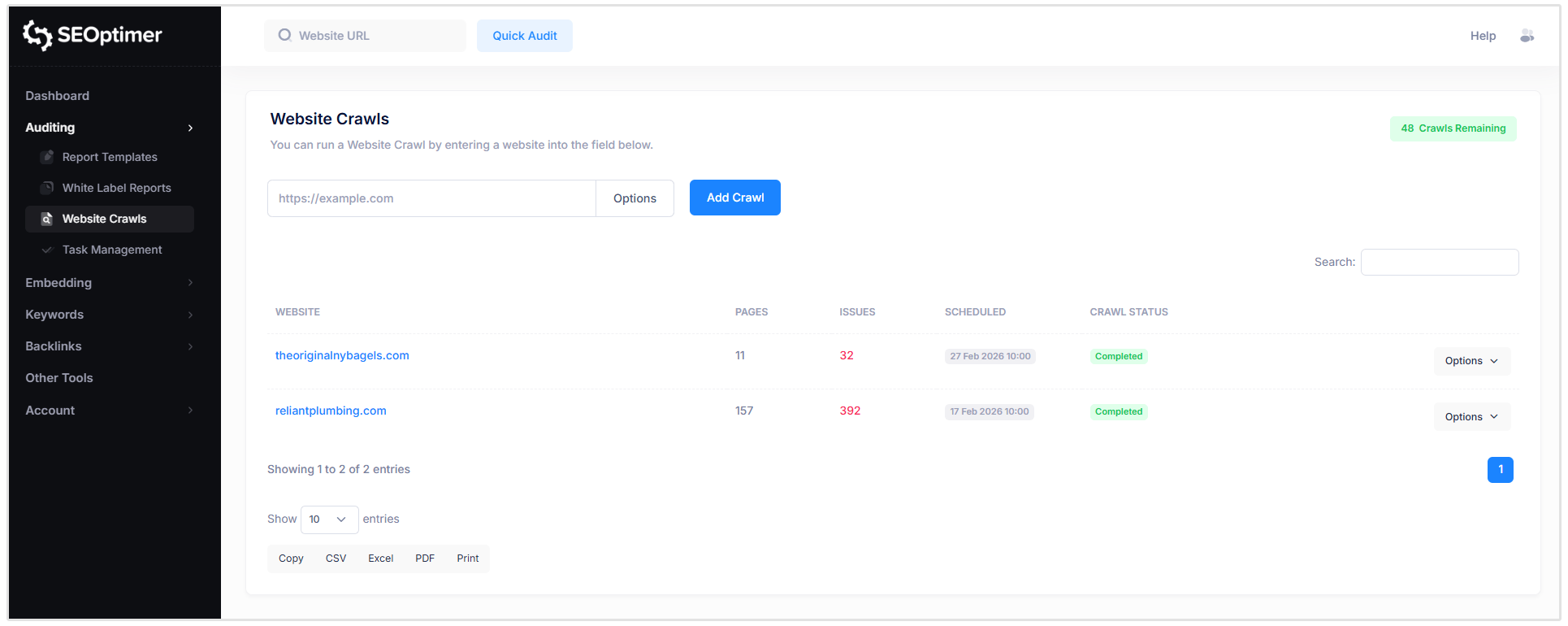
Aby ustawić harmonogram indeksowania, wystarczy kliknąć przycisk „Opcje” po prawej stronie strony internetowej, dla której chcesz zaplanować indeksowanie.
Następnie kliknij opcję “Harmonogram” i dostosuj harmonogram przeszukiwania zgodnie z własnymi preferencjami.
![Jak zaplanować [crawl] w SEOptimer](/storage/images/2026/02/7611-How to schedule crawl in SEOptimer.png)
Kiedy zaplanowane "crawl" zostanie zakończone, otrzymasz wiadomość e-mail z kilkoma szczegółowymi informacjami na wysokim poziomie.
Ustawianie własnych "zasad" [Crawl]
"SEO Crawler" [zawiera] opcje konfiguracji indeksowania, które pozwalają [kontrolować], które strony są [uwzględnione] w indeksowaniu.
Te ustawienia są przydatne, jeśli chcesz ograniczyć wyniki, unikać zduplikowanych adresów URL lub upewnić się, że crawler zachowuje się zgodnie z zasadami indeksowania Twojej witryny.
Przestrzegaj wykluczeń w pliku Robots.txt
Domyślnie, robot indeksujący może przestrzegać zasad zdefiniowanych w pliku robots.txt Twojej witryny. Określa to, czy robot indeksujący powinien unikać skanowania stron oznaczonych jako [niedozwolone].
- Włączone (zalecane): Robot indeksujący będzie respektować wykluczenia w pliku robots.txt i pominie zablokowane strony.
- Wyłączone: Robot indeksujący zignoruje zasady pliku robots.txt i spróbuje przeszukać wszystkie strony, do których ma dostęp.
W większości przypadków zaleca się przestrzeganie "robots.txt", zwłaszcza podczas uruchamiania [crawlów] na żywych stronach produkcyjnych.
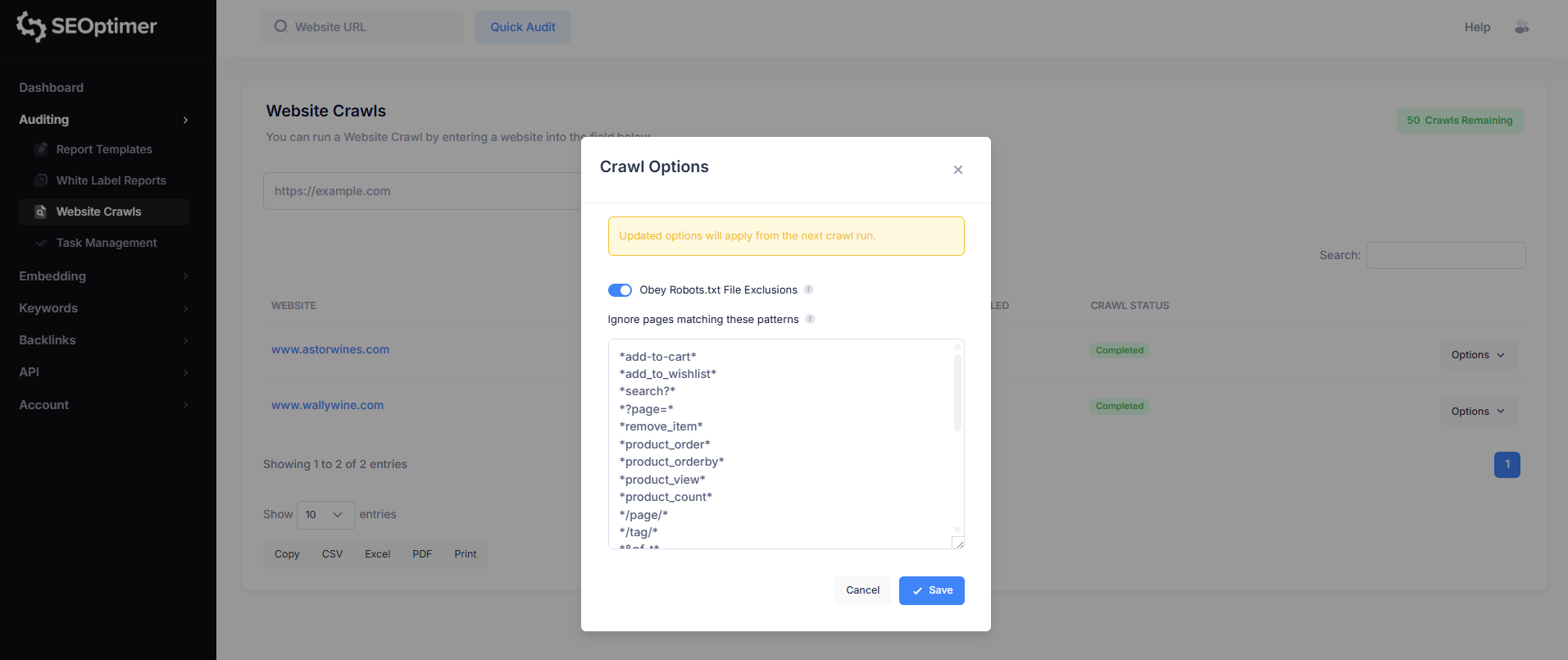
Ignoruj strony pasujące do tych wzorców
Niektóre strony internetowe generują wiele wersji tej samej strony przy użyciu parametrów URL (na przykład, "sortowanie", "filtrowanie", "stronicowanie" lub "kody śledzenia").
To jest szczególnie powszechne na stronach internetowych [ecommerce].
Opcja “Ignoruj strony pasujące do tych wzorców” pozwala wykluczyć te zduplikowane lub niskowartościowe adresy URL z indeksowania. Pomaga to utrzymać wyniki indeksowania w czystości i ułatwia przeglądanie raportów o problemach.
To jest bardziej zaawansowana funkcja i jest głównie przydatna dla stron internetowych z dużą liczbą adresów URL opartych na parametrach.
SEOptimer zawiera domyślny zestaw wzorców wykluczeń do [filtrowania] [typowych] duplikatów opartych na parametrach, ale możesz dodać własne [zasady], jeśli zajdzie taka potrzeba.
Te wzorce "podążają" za standardową "składnią" dopasowywania robots.txt.
Jeśli nie jesteś zaznajomiony z zasadami "robots.txt" lub dopasowywaniem wzorców URL, zaleca się zapoznanie się z podstawami przed dodaniem niestandardowych wykluczeń "crawl". Nieprawidłowe wzorce mogą uniemożliwić indeksowanie ważnych stron.
Oto kilka przydatnych "odniesień":
- Robots.txt - "Ostateczny" przewodnik
- Wprowadzenie do Robots.txt i Przewodnik | Google Search Central
- Jak Google interpretuje specyfikację "robots.txt"
- Składnia pliku robots.txt
Jak [wyeksportować] "dane" z "crawl"
Każda tabela w raporcie SEO Crawler zawiera wbudowane opcje eksportu, umożliwiające pobieranie lub udostępnianie wyników [crawl] poza platformą.

Na dole każdej tabeli, zobaczysz przyciski eksportu, które pozwalają "wyeksportować" dane w różnych formatach:
- CSV: Pobierz tabelę jako plik .csv ("przydatne" dla arkuszy kalkulacyjnych i przetwarzania danych).
- Excel: Eksportuj tabelę jako plik Excel do raportowania lub dalszej analizy.
- PDF: Wygeneruj wersję PDF tabeli do "udostępniania" lub "dokumentacji".
- Print: Otwórz wersję tabeli przyjazną dla [druku].
Eksporty mają zastosowanie do konkretnej tabeli, którą oglądasz, co ułatwia pobieranie "list problemów", "raportów stron" lub [filtrowanych] wyników w razie potrzeby.
Podsumowanie
SEO Crawler firmy SEOptimer ułatwia identyfikację problemów z "techniczne" i "on-page SEO" na całej stronie internetowej w jednym [crawl].
Przeglądając raport z indeksowania i korzystając z wbudowanej listy zadań, możesz szybko przekształcić [crawl findings] w "realne ulepszenia".
Aby uzyskać najlepsze wyniki, rozważ zaplanowanie regularnych "crawlów", aby monitorować zmiany w czasie i wychwytywać nowe problemy w miarę rozwoju Twojej strony internetowej.
Potrzebujesz pomocy?
"Czat na żywo": Kliknij "Czat na żywo" (na dole po prawej)
Email: [email protected]
"Czas odpowiedzi": "W ciągu 24 godzin"