Wiesz, kiedy używasz Google, aby wyszukać "usługę", lub znaleźć "informacje"? A gdy strona się ładuje, zawsze jest jedna witryna na samym [szczycie].
Strony na pozycji 1 na stronie wyników wyszukiwania Google (SERP) otrzymują większość wszystkich kliknięć. Więc nie trzeba dodawać, że "ważne jest" przestrzeganie najlepszych praktyk SEO, aby spróbować i "zmaksymalizować pozycję swojej strony" w SERP.
Ale czy wiesz, jak Google w ogóle [znajduje] twoją stronę w pierwszej kolejności?
Odpowiedzią są crawlery Google. Crawlery Google to jak małe cyfrowe roboty, które odwiedzają strony internetowe i zbierają informacje o tych stronach.
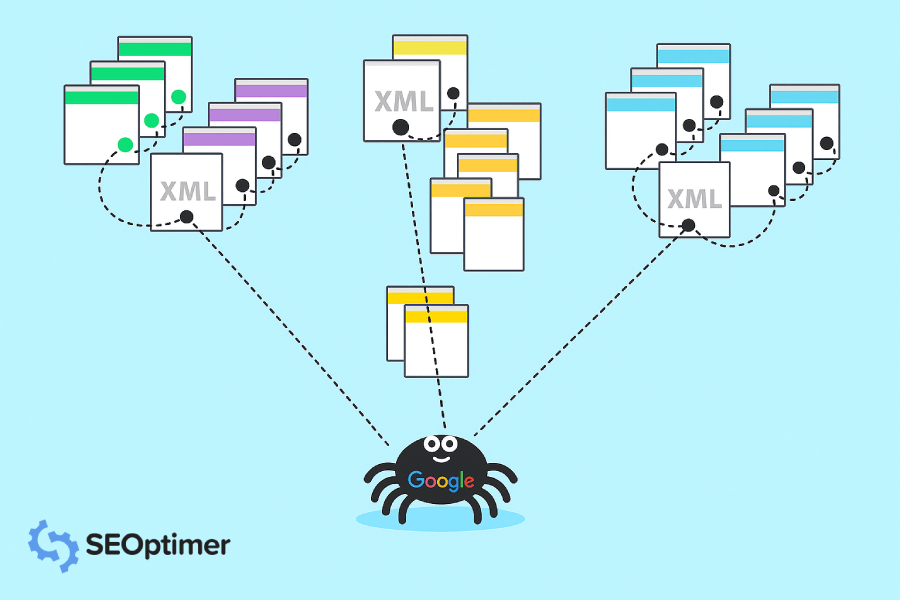
Potem, Google indeksuje wszystkie te informacje i wykorzystuje je do ulepszania swojego algorytmu wyszukiwania. Gdy ktoś wpisuje zapytanie w Google, algorytm wyszukiwania przeszukuje wszystkie zindeksowane informacje, aby znaleźć najlepsze wyniki dla zapytania tej osoby.
I tak właśnie Google jest w stanie dostarczyć Ci najlepsze wyniki, gdy [szukasz] czegoś w internecie!
Czym jest Google Crawler?
Google Crawler jest również znany jako “robot” lub “pająk,” (rozumiesz, bo one “czołgają się”) i przechodzą z witryny na witrynę w poszukiwaniu nowych informacji do przechowywania w ich bazach danych. Istnieje 15 rodzajów crawlerów używanych przez Google, ale najważniejszym z nich jest Googlebot.

Chociaż Google jest potężny, nie może zrobić wszystkiego, za każdym razem, gdy tworzona jest nowa strona internetowa, Google o niej nie wie, dopóki ta strona nie zostanie [przeskanowana].
Google używa Googlebot do ciągłego pozyskiwania najnowszych informacji do przechowywania w swojej bazie danych.
Indeksowanie Google vs "crawling" Google
Indeksowanie odbywa się dopiero po tym, jak strona internetowa zostanie zindeksowana przez GoogleBot. Gdy zostanie zindeksowana, jest skanowana, a informacje zeskanowane z tej strony lub podstrony są przechowywane w indeksie Google.
Indeks "skategoryzuje" i "uszereguje" strony odpowiednio w wynikach wyszukiwania.
Dlaczego "Google Crawlers" są [ważne]?
Więc dlaczego to wszystko jest ważne?
Cóż, powiedzmy, że prowadzisz biznes i masz stronę internetową. Chcesz, aby Twoja strona była jak najbliżej szczytu. Jeśli Twoja strona nie zostanie [zeskanowana] i przeskanowana, nie załaduje się na stronie wyszukiwania.
Bez obecności w internecie, nie będziesz w stanie dotrzeć do swojej "publiczności" lub "konsumentów". "Przeszukiwanie" i "indeksowanie" sprawiają, że stronom internetowym jest nieco łatwiej przyciągnąć uwagę.
Jak działa "Google Crawler"
Więc wiesz, co to jest, ale jak to działa? Chociaż Google jest potężne, nie może [zrobić] wszystkiego, za każdym razem gdy tworzona jest nowa strona internetowa, Google nie wie o niej, dopóki ta strona nie zostanie [zaindeksowana]. Google używa Googlebota do ciągłego zdobywania dodatkowych informacji do przechowywania w swojej bazie danych.
Gdy ta strona internetowa jest przeszukiwana lub skanowana. Strona jest renderowana i otrzymuje kod HTML, CSS, JavaScript i kod zewnętrzny, które są potrzebne Googlebotowi do indeksowania i rankingu stron internetowych. Googlebot, największy "crawler", jest w stanie zobaczyć i renderować wszystkie strony internetowe za pomocą Chromium.
Chromium jest zawsze aktualizowany, aby [mógł] pozostać stabilny i wykonywać swoje zadania dokładnie. Jest to dostępne dla wszystkich i [może] być również używane do testowania nowych funkcji i tworzenia nowych przeglądarek.
Jak "ułatwić" [indeksowanie] Twojej strony
Teraz, gdy wiemy, z czym pracujemy, [pracujmy] nad tym, aby Twoja strona internetowa była łatwa do indeksowania.
Oto kilka wskazówek i trików, które sprawią, że Twoja strona internetowa stanie się magnesem dla crawlerów i wzrośnie na szczyt strony wyników wyszukiwania.
Linki "wewnętrzne"
Linki wewnętrzne mogą być Twoim najlepszym przyjacielem podczas indeksowania. Twoja strona mogła już wcześniej zostać zindeksowana przez Google, ale ostatnio mogłeś dodać więcej stron. Jeśli robot indeksujący już zna Twoją witrynę, skupi się tylko na głównych stronach.
Pamiętaj, Google nie jest informowane za każdym razem, gdy tworzona jest nowa strona, "przeszukuje" [sieć], aby znaleźć te strony.
Używanie linków wewnętrznych na głównych stronach prowadzi robota tam, gdzie [musi] iść. Najlepszym miejscem dla tych linków wewnętrznych jest Twoja strona główna, to jest strona, która otrzymuje najwięcej ruchu i gdzie robot będzie skanować najpierw.
Linki zwrotne
Backlinki są kolejnym świetnym sposobem, aby Twoja strona została zindeksowana. Ta metoda może być używana do „promowania” Twojej strony internetowej dla robota indeksującego.
Linkowanie do bardziej popularnej strony zwiększy Twoje szanse na [bycie] odkrytym przez crawlera.
Uwaga: Możesz łatwo sprawdzić "profil linków zwrotnych" dla każdej strony, w tym swoich konkurentów, używając darmowego narzędzia do badań linków zwrotnych SEOptimer.
Obrazy
Obrazy mogą być "przeszukiwane", w rzeczywistości istnieje specjalny "crawler" tylko dla obrazów. Ten "crawler" jest znany jako Googlebot Image i zbiera obrazy do bazy danych.
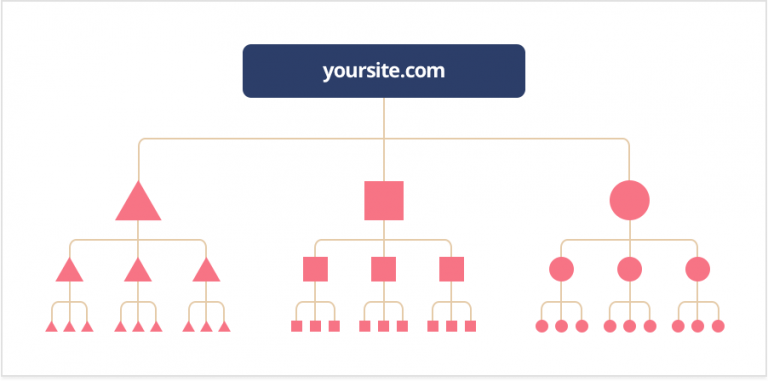
Mapy strony
Istnieje sposób, aby bezpośrednio powiedzieć Google, które strony chcesz, aby były przez nie [przeszukiwane]. Możesz przesłać mapę witryny z [szczegółową] listą stron, które chcesz, aby były [przeszukiwane] przez Google.
Użyj naszego Generatora mapy witryny XML, aby zbudować mapę witryny dla całej swojej strony internetowej. "Stwórz", "nazwij". I pobierz ją na swój komputer, aby przesłać do Google Search Console.
Głębokość kliknięcia
"Głębokość kliknięcia" (znana również jako "głębokość indeksowania") pokazuje, ile pracy musiałby wykonać crawler, aby dotrzeć i zeskanować Twoją stronę. Nigdy nie chcesz, aby crawler musiał wykonywać zbyt dużo pracy, chcesz, aby Twoja strona lub witryna była jak najbardziej przyjazna dla crawlerów.
"Powinno" to "zająć" około trzech kliknięć lub mniej, im więcej to zajmuje, tym bardziej spowalnia "crawlera".
"Dobra struktura" [powinna] "pozwolić" [na dodanie] nowych stron bez wpływu na głębokość kliknięć. "Crawler" [powinien nadal móc łatwo] dotrzeć do tych stron.
FYI: Dobrym "złotym środkiem" jest upewnienie się, że można przejść ze strony na Twojej witrynie do dowolnej innej strony w maksymalnie 3 [kliknięciach]. To zapewnia, że Google może znaleźć i zaindeksować wszystkie Twoje strony [wydajnie]. Dodatkowo, jest to świetne dla "doświadczenia użytkownika".
Instrukcje indeksowania
Są instrukcje, które Google "przestrzega" podczas indeksowania i stron ideacyjnych. Robots.txt, tag noindex, meta tag robots i X-Robots-Tag. Nie martw się, "rozbijemy" to dla ciebie.
Robots.txt. jest plikiem katalogu głównego, który "wstrzymuje" określone strony i treści przed Google. Kiedy "crawler" skanuje stronę, będzie szukać tego dla informacji. Jeśli "crawler" nie może znaleźć tych informacji, zaprzestanie swojego skanowania i strona nie będzie częścią wyników wyszukiwania.
Tag noindex [zapobiega] wszystkim typom robotów indeksujących przed [skanowaniem] i [indeksowaniem] strony.
Tag meta robots, może pomóc kontrolować sposób, w jaki strona [powinna] być indeksowana i ładowana dla użytkowników internetu w wynikach wyszukiwania.
X-Robots-Tag, jest częścią nagłówka HTTP i pomaga kontrolować [zachowanie] "crawlera". Nadzoruje, jak cała [strona] jest indeksowana. Możesz zablokować obrazy i filmy na [stronie] przy użyciu tej metody. Możesz również celować w poszczególne typy "crawlerów", ale tylko wtedy, gdy jest to określone.
Jeśli "typ" [crawlera] nie jest określony, wówczas "instrukcje" będą dotyczyły wszystkich [crawlerów] Google.
Struktura URL
Możliwe, że słyszałeś to już wcześniej, ale upewnij się, że masz "przyjazny dla użytkownika" URL.

URL, który jest "łatwy", taki, który zarówno twoi konsumenci, jak i algorytmy będą [uwielbiać]. Staraj się utrzymać swój URL tak krótki i przyjemny, jak to możliwe.
Jeśli masz długi URL, może być on mylący nie tylko dla ludzkiego oka, ale również dla bota Google.
Im bardziej "zdezorientowany" jest Googlebot, tym bardziej "wyczerpie" swoje zasoby indeksowania i to zdecydowanie nie jest to, czego chcesz.
Typowe "problemy" (i "rozwiązania") z "indeksowaniem Google"
Więc masz stronę, ale nie działa tak, jakbyś tego chciał. Może to być spowodowane tym, że "crawler" ma trudności z próbą skanowania i indeksowania twojej witryny.
Oto kilka typowych problemów, z którymi ludzie się spotykają podczas "Google Crawling".
1. Google nie indeksuje Twojej strony internetowej
Upewnij się, że sprawdzasz, czy Twoja strona lub witryna jest przyjazna dla indeksowania. Oznacza to posiadanie dobrej [struktury] URL, włączenie wewnętrznych [linków] i backlinków, jeśli to konieczne, lub poświęcenie czasu na stworzenie mapy witryny, aby pokazać Googlebotowi, gdzie indeksować.
Również pamiętaj, że Google może potrzebować trochę czasu na zindeksowanie i przeszukanie Twojej strony internetowej, ponieważ musi Cię znaleźć!
2. Zostałeś usunięty z indeksu Google
Google usunie stronę internetową, jeśli uzna to za konieczne, czy to ze względu na prawo, "trafność" czy za nieprzestrzeganie obowiązujących wytycznych. Użyj naszego SEO Crawler, aby sprawdzić [czy] coś może blokować crawler przed dostępem do Twojej strony.
Gdy to zrobisz, możesz zgłosić swoją stronę internetową do Google w celu ponowne rozpatrzenie.
3. Masz "zduplikowaną treść"
"Powielona treść" to strona, która ma "podobną treść" do innej strony lub wiele URL-i prowadzących do jednej strony.

W przypadku posiadania stron o podobnej treści, co może również oznaczać, że masz wersję stacjonarną i mobilną jednej strony. Jednak najczęstszym przykładem [zduplikowanej treści] na wielu stronach.
Można tego uniknąć i naprawić za pomocą kanonicznego adresu URL, czyli adresu URL, który służy jako przedstawiciel dla tych zduplikowanych stron.
Google pokaże tylko stronę, którą uznają za zawierającą "najbardziej przydatną treść" i oznaczą ją jako kanoniczną. To jest strona, która zostanie zindeksowana zamiast duplikatów.
Aby tego uniknąć, rozważ przepisanie tekstu na tych stronach, aby nie były mylone jako "duplikaty".
4. Występują problemy z renderowaniem
Jeśli masz problemy z renderowaniem, upewnij się, że twoje kodowanie nie jest zbyt duże. Twoje kodowanie musi być jak najczystsze, aby robot indeksujący mógł wszystko prawidłowo [renderować].
Jeśli "crawler" nie może [renderować] strony, zostanie uznana za pustą.
Często zadawane pytania dotyczące Google Crawler
Ile czasu zajmuje Google przeszukanie witryny?
Zazwyczaj Google zajmuje od kilku dni do tygodni, aby "przeskanować". Możesz monitorować skanowanie za pomocą "Raportu stanu indeksu" lub narzędzia do inspekcji URL. Pamiętaj, że Google nie jest powiadamiany za każdym razem, gdy zostanie utworzona nowa strona internetowa lub strona, musi ją "przeskanować" i znaleźć.
Do wiadomości: Bardziej popularne strony są indeksowane szybciej. Nowe strony zazwyczaj wymagają kilku tygodni na indeksowanie, podczas gdy renomowane strony jak NY Times, Wall Street Journal i Wikipedia są indeksowane wielokrotnie w ciągu dnia.
Czym jest algorytm Google Crawler?
Algorytm Google Crawler opiera się na tym, jak przyjazna dla crawlera jest Twoja strona. Obejmuje to "słowa kluczowe", URL-e, "treść i informacje", kodowanie i wiele więcej. To od Ciebie zależy, aby dostarczyć Google najlepsze "treści i wskazówki", aby mógł znaleźć Twoją stronę i rozpocząć "crawling".
Czy wszystkie strony są dostępne do [crawlingu]?
To jest dobre pytanie. Krótka odpowiedź brzmi nie. Niektóre strony nie mogą być przeszukiwane i indeksowane, ponieważ są [chronione] hasłem, zostały [specjalnie wykluczone] z instrukcji indeksowania lub nie mają żadnych [linków] na swoich stronach.
Kiedy moja strona internetowa pojawi się w wyszukiwarce Google?
To zawsze będzie się różnić w zależności od tego, jak długo potrwa, zanim Twoja strona internetowa zostanie zindeksowana i zaindeksowana. Może to zająć tylko kilka dni lub nawet kilka tygodni.
Jakie inne "web crawlers" [są]?
"Tak"! Istnieje mnóstwo "web crawlerów" poza piętnastoma Google’a. Oto kilka dla odniesienia:
- Jest BingBot używany przez wyszukiwarkę Bing.
- SlurpBot, używany przez Yahoo! Ten "web crawler" to mieszanka między Yahoo! a Bing, ponieważ Bing głównie zasila Yahoo!.
- ExaBot jest najpopularniejszą [wyszukiwarką] i "crawler" we Francji.
- AppleBot jest używany przez główną firmę technologiczną Apple do wyszukiwania w spotlight i sugestii Siri.
- Facebook, wierzcie lub nie, używa linków do wysyłania treści do innych profili i może indeksować tylko wtedy, gdy zostanie dostarczony link.
Optymalizuj swoją witrynę dla indeksowania przez Google
Teraz, gdy rozumiesz podstawy [Google Crawling] i jak to działa, wykorzystaj to na swoją korzyść! Spraw, aby Twoja strona została poprawnie zindeksowana i wspięła się na szczyt strony wyników wyszukiwania. To jest "darmowe" i całkowicie do Twojej dyspozycji.