Robots.txt es un archivo en forma de texto que indica a los bots rastreadores que indexen o no ciertas páginas. También se le conoce como el guardián de tu sitio web. El primer objetivo de los bots rastreadores es encontrar y leer el archivo robots.txt antes de acceder a tu mapa del sitio o a cualquier página o carpeta.
Con robots.txt podrás:
- Regular cómo los robots de los motores de búsqueda rastrean tu página web
- Ofrecer cierto acceso
- Ayudar a los motores de búsqueda a indexar el contenido del sitio
- Mostrar cómo ofrecer contenido a los usuarios
Robots.txt es parte del Protocolo de Exclusión de Robots (R.E.P por sus siglas en inglés), que incluye las directivas de nivel del sitio/página/URL. Aunque los robots de los motores de búsqueda pueden rastrear todo tu sitio, depende de ti ayudarles a decidir si ciertas páginas merecen el tiempo y el esfuerzo.
Por qué necesitas Robots.txt
Tu página web no necesita un archivo robots.txt para que funcione correctamente. La razón principal por la que necesita un archivo robots.txt es porque cuando los bots rastrean tu sitio, piden permiso para rastrear e intentar conseguir información de la página para indexarla. Un sitio web sin un archivo robots.txt básicamente está pidiendo a los rastreadores de robots que indexen el sitio como les parezca mejor. Es importante entender que los bots seguirán rastreando tu sitio sin el archivo robots.txt.
La ubicación de tu archivo robots.txt también es importante porque todos los bots buscarán www.123.com/robots.txt. Si no encuentran nada, asumirán que el sitio no tiene un archivo robots.txt e indexarán todo. El archivo debe ser un archivo de texto ASCII o UTF-8. También es importante tener en cuenta que las reglas distinguen entre mayúsculas y minúsculas.
Funciones que robots.txt hará y no hará:
- El archivo puede controlar el acceso de los rastreadores a ciertas áreas de tu sitio web. Debes tener mucho cuidado al configurar robots.txt, ya que puedes bloquear toda la página web para que no se indexe.
- Evita que el contenido duplicado se indexe y aparezca en los resultados de los motores de búsqueda.
- El archivo especifica la demora del rastreo para evitar que los servidores se sobrecarguen cuando los rastreadores cargan varias partes de contenido a la vez.
Estos son algunos Googlebots que pueden rastrear tu sitio de vez en cuando:
| Web Crawler | User-Agent String |
| Googlebot News | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (teléfono) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (compatible; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (Calidad de la página de destino de PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (busca recursos para dispositivos móviles) | AdsBot-Google-Mobile-Apps |
Aquí puedes ver una lista de bots adicionales.
- Los archivos ayudan en la especificación de la ubicación del mapa del sitio.
- También evitan que los robots de los motores de búsqueda indexen varios archivos en el sitio web, como imágenes y PDF.
Cuando un bot quiere visitar tu sitio web (por ejemplo, www.123.com), inicialmente se fija en www.123.com/robots.txt y encuentra:
User-agent: *
Disallow: /
Este ejemplo indica a todos los robots de los motores de búsqueda (User-agents*) que no indexen (Disallow: /) el sitio web.
Si eliminas la barra diagonal de Disallow, como en el siguiente ejemplo,
User-agent: *
Disallow:
los bots podrán rastrear e indexar todo en el sitio web. Por eso es importante comprender la sintaxis de robots.txt.
Entiende la sintaxis de robots.txt
La sintaxis de robots.txt se puede considerar como el “lenguaje” de los archivos robots.txt. Hay cinco términos comunes que probablemente encontrarás en un archivo robots.txt
- User-agent: rastreador web específico al que le estás dando instrucciones de rastreo (generalmente un motor de búsqueda). Aquí puedes encontrar una lista de la mayoría de los agentes de usuario.
- Disallow: es el comando que se usa para decirle a un agente de usuario que no rastree una URL en particular. Solo se permite una línea “Disallow:” para cada URL.
- Allow (solo aplicable para Googlebot): el comando le dice al robot de Google que puede acceder a una página o subcarpeta aunque su página principal o subcarpeta no esté permitida.
- Crawl-delay: hace referencia a la cantidad de milisegundos que un rastreador tiene que esperar antes de cargar y rastrear el contenido de la página. Ten en cuenta que Googlebot no reconoce este comando, pero la frecuencia de rastreo se puede configurar en Google Search Console.
- Sitemap: se usa para indicar la ubicación de cualquier mapa del sitio XML asociado con una URL. Recuerda que este comando solo es compatible con Google, Ask, Bing y Yahoo.
Resultados de la instrucción robots.txt
Se pueden obtener tres resultados con robots.txt:
- Permiso completo
- Prohibición total
- Permiso condicionado
Veamos a continuación cada uno de ellos.
Este resultado significa que se puede rastrear todo el contenido de tu sitio web. Los archivos robots.txt están destinados a bloquear el rastreo de los robots de los motores de búsqueda, por lo que este comando puede ser muy importante.
Este resultado podría significar que no tienes ningún archivo robots.txt en tu sitio web. Incluso si no lo tienes, los robots de los motores de búsqueda lo buscarán en tu sitio. Si no lo obtienen, rastrearán todas las partes de tu sitio web.
La otra opción dentro de este resultado consiste en crear un archivo robots.txt pero mantenerlo vacío. Cuando se comience a rastrear, se identificará e incluso leerá el archivo robots.txt. Como no se encontrará nada, se procederá a rastrear el resto del sitio.
Si tienes un archivo robots.txt y tienes las dos líneas siguientes,
User-agent:*
Disallow:
el motor de búsqueda rastreará tu sitio web, identificará el archivo robots.txt y lo leerá. Llegará a la segunda línea y a continuación procederá a rastrear el resto del sitio.
En este caso, no se rastreará ni indexará ningún contenido. Este comando se emite con la siguiente línea:
User-agent:*
Disallow:/
Cuando hablamos de ningún contenido, queremos decir que no se puede rastrear nada del sitio web (contenido, páginas, etc.). Esto nunca es una buena idea.
Significa que solo se puede rastrear cierto contenido del sitio web.
Un permiso condicionado tiene este formato:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Aquí puedes encontrar la sintaxis completa de robots.txt.
Ten en cuenta que las páginas bloqueadas aún se podrán indexar incluso si se rechazó la URL como se muestra a continuación:
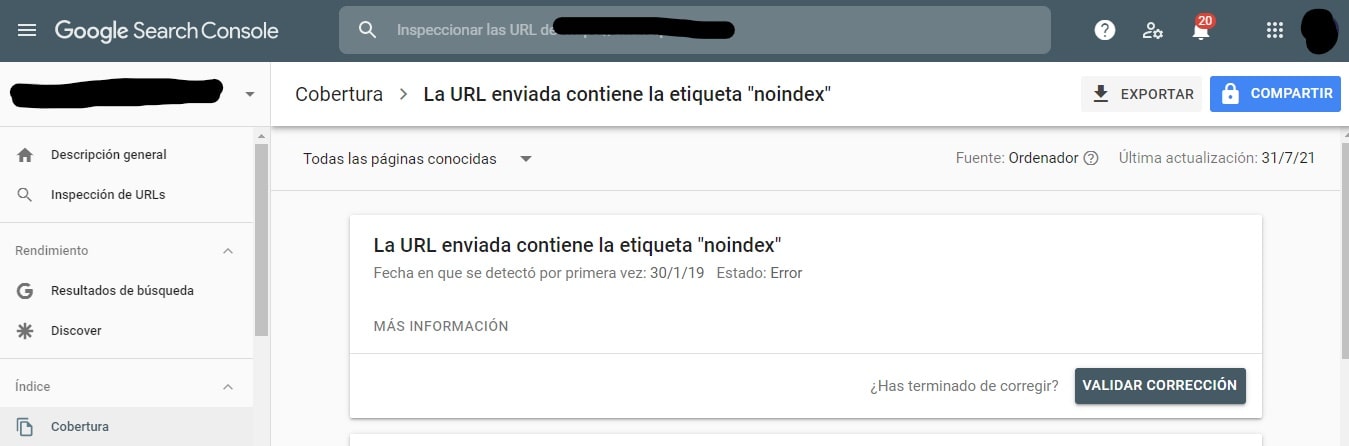
Como se ve en la captura de pantalla anterior, quizás recibas un correo electrónico de los motores de búsqueda de que tu URL ha sido indexada. Si tu URL no permitida está vinculada desde otros sitios, como texto de anclaje en enlaces, se indexará. La solución consiste en: 1) proteger con contraseña tus archivos en tu servidor; 2) usar la metaetiqueta noindex; 3) o eliminar completamente la página.
¿Un robot podrá escanear e ignorar mi archivo robots.txt?
Sí. Es posible que un robot pueda eludir el archivo robots.txt. Esto se debe a que Google utiliza otros factores como información externa y enlaces entrantes para determinar si una página debe indexarse o no. Si no quieres indexar una página, debes utilizar la metaetiqueta noindex robots. Otra opción consiste en utilizar el encabezado X-Robots-Tag HTTP.
¿Se pueden bloquear los robots defectuosos?
En teoría, es posible bloquear robots defectuosos, pero hacerlo en la práctica puede ser más complicado. Veamos algunas maneras de hacerlo:
- Puedes bloquear un robot defectuoso excluyéndolo. Sin embargo, necesitas saber el nombre en particular del robot en el campo User-Agent. A continuación, debes añadir una sección en tu archivo robots.txt que excluya al robot defectuoso.
- Configuración del servidor. Esto solo funcionaría si la operación del robot defectuoso se realiza desde una dirección IP única. La configuración del servidor o un firewall de red impedirá que el robot defectuoso acceda a tu servidor web.
- Configuración avanzada del firewall. Bloquea automáticamente el acceso a las diferentes direcciones IP donde hay copias del robot defectuoso. Un buen ejemplo de bots que operan en varias direcciones IP es el caso de PC secuestradas que incluso podrían ser parte de una red de bots más grande (aquí puedes ver más información sobre una red de bots).
Si el robot defectuoso opera desde una única dirección IP, puedes bloquear su acceso a tu servidor web a través de la configuración del servidor o con un firewall de red.
Si las copias del robot funcionan en varias direcciones IP diferentes, será más difícil bloquearlas. En este caso, la mejor opción consiste en utilizar una configuración avanzada del firewall que bloquee automáticamente el acceso a direcciones IP que llevan a cabo muchas conexiones; desafortunadamente, esto también puede afectar el acceso de los mejores bots.
¿Cuáles son las mejores acciones SEO al usar robots.txt?
Ahora es posible que te estés preguntando cómo tener éxito con robots.txt. Veámoslo con más detalle:
- Asegúrate de no bloquear ningún contenido o secciones de tu sitio que quieres rastrear.
- Si quieres que la equidad del enlace pase de una página con robots.txt (lo que significa que está prácticamente bloqueada) al destino del enlace, usa un mecanismo de bloqueo diferente al de robots.txt.
- No uses robots.txt para evitar que los datos confidenciales, como la información privada de los usuarios, aparezcan en los resultados del motor de búsqueda. Si lo haces, podría permitir que otras páginas se vinculen a páginas que contienen información privada de los usuarios, lo que puede hacer que la página se indexe. En este caso, se ha omitido el archivo robots.txt. Otras opciones que puedes explorar son la protección con contraseña o meta directiva noindex.
- No hace falta especificar directivas para todos los rastreadores de un motor de búsqueda ya que la mayoría de los agentes de usuario siguen las mismas reglas si pertenecen al mismo motor de búsqueda. Google utiliza Googlebot para motores de búsqueda y Googlebot Image para búsquedas de imágenes. La única ventaja de saber cómo especificar cada rastreador es que puedes ajustar exactamente cómo rastrear el contenido de tu sitio web.
- Si has cambiado el archivo robots.txt y quieres que Google lo actualice con mayor rapidez, envíalo directamente a Google. Haz clic aquí para recibir instrucciones sobre cómo hacerlo. Es importante tener en cuenta que los motores de búsqueda almacenan en caché el contenido de robots.txt y actualizan el contenido en caché al menos una vez al día.
Directrices básicas robots.txt
Ahora que tienes un conocimiento básico de la relación que hay entre el SEO y robots.txt, ¿qué debes tener en cuenta al usar robots.txt? En esta sección analizamos algunas pautas a seguir al usar robots.txt, aunque es importante leer la sintaxis completa.
El editor de texto que uses para crear un archivo robots.txt debe poder crear archivos de texto ASCII o UTF-8 estándar. No es una buena idea usar un procesador de texto ya que se pueden añadir algunos caracteres que pueden afectar el rastreo.
Aunque puedes utilizar prácticamente cualquier editor de texto para crear tu archivo robots.txt, esta herramienta es muy recomendable ya que te permite realizar pruebas en tu sitio web.
Estas son algunas pautas sobre el formato y la ubicación:
- Debes nombrar el archivo que crea “robots.txt” porque el archivo distingue entre mayúsculas y minúsculas. No se usan caracteres en mayúscula.
- Solo puedes tener un archivo robots.txt en todo el sitio.
- El archivo robots.txt solo se encuentra en un lugar: la raíz del host del sitio web al que se aplica. Ten en cuenta que no se puede colocar en un subdirectorio. Si tu página web es http://www.123.com/, entonces la ubicación de robots.txt es http://www.123.com/robots.txt, no http://www.123.com/pages/robots.txt.Recuerda que el archivo robots.txt puede aplicarse a subdominios (http://website.123.com/robots.txt) e incluso a puertos no estándar, como http://www.123.com: 8181/robots.txt .
Como mencionamos previamente, robots.txt no es la mejor manera para evitar que se indexe información personal confidencial. Esta es una preocupación válida, especialmente en la actualidad con la aplicación del GDPR. Es imprescindible que la privacidad de la información no esté en peligro.
¿Cómo te aseguras de que robots.txt no mostrará datos confidenciales en los resultados de búsqueda?
El uso de un subdirectorio separado que “no se pueda listar” en la web evitará la distribución de información confidencial. Puedes asegurarte de que “no se puede listar” configurando el servidor. Simplemente almacena todos los archivos que no quieres que robots.txt visite e indexa en este subdirectorio.
¿La lista de páginas o directorios en el archivo robots.txt no genera un acceso no intencionado?
Como mencionamos previamente, poner en un subdirectorio separado todos los archivos que no quieres indexar y luego hacer que no se puedan listar en la configuración del servidor, debe garantizar que no aparezcan en los resultados de búsqueda. La única lista que harás en el archivo robots.txt es la del nombre del directorio. La única manera de acceder a estos archivos es mediante un enlace directo a uno de los archivos.
A continuación puedes ver un ejemplo:
En vez de
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Usa
User-Agent:*
Disallow:/norobots/
A continuación, debes crear un directorio “norobots” que incluya foo.html y bar.html. Ten en cuenta que las configuraciones de tu servidor deben ser claras en cuanto a no generar una lista de directorios para el directorio “norobots”.
Esto puede que no sea un enfoque muy seguro porque la persona o el bot que ataque tu página web todavía podrá ver que tienes un directorio “norobots”, aunque no se puedan ver los archivos dentro del directorio. Sin embargo, alguien podría publicar un enlace a esos archivos en tu sitio web o, lo que es peor, el enlace puede aparecer en un archivo de registro accesible al público (por ejemplo, un registro del servidor web como referencia). También es posible una configuración incorrecta del servidor, lo que da como resultado una lista de directorios.
¿Qué significa esto? Robots.txt no puede ayudarte a controlar el acceso por la sencilla razón de que no está diseñado para ello. Un buen ejemplo es una “señal de prohibición de entrada”. Hay personas que aún así se saltarán la norma.
Si hay archivos a los que solo quieres que accedan personas autorizadas, las configuraciones del servidor ayudarán con la autenticación. Si usas un CMS (sistema de gestión de contenido), tienes a tu disposición controles de acceso a páginas individuales y diferentes recursos.
¿Se puede optimizar robots.txt para el SEO?
Por supuesto. La mejor guía sobre cómo optimizar robots.txt es el contenido del sitio. Pero recuerda: robots.txt nunca se debe usar para impedir que los robots de los motores de búsqueda rastreen las páginas. Úsalo únicamente para bloquear las secciones de tu sitio web que no son accesibles al público, por ejemplo, páginas de inicio de sesión como wp-admin.
Esta es la línea de rechazo de la página de inicio de sesión de Neil Patel en uno de sus sitios web:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Puedes utilizar esta línea de rechazo para bloquear tu inicio de sesión y evitar que se indexe.
Si hay algunas páginas específicas que no quieres que se indexen, usa el mismo comando que el anterior. Por ejemplo:
User-agent:*
Disallow:/page/
Especifica la página que no quieres que se indexe después de la barra y cierra con otra barra. Por ejemplo:
User-agent:*
Disallow:/page/thank-you/
¿Cuáles son las páginas que quizás deberías excluir de la indexación?
- Contenido duplicado intencional. ¿Qué significa esto? En ocasiones creas contenido duplicado intencionalmente para conseguir un propósito específico. Un buen ejemplo es una versión para imprimir una página web en particular. Puedes usar robots.txt para bloquear la indexación de la versión para imprimir el contenido idéntico.
- Páginas de agradecimiento. La razón por la que debes bloquear estas páginas para que no se indexen es muy sencilla: se supone que es el último paso del embudo de ventas. Cuando tus visitantes lleguen a esta página, deberían haber seguido todo el embudo de ventas. Si esta página se indexa, significa que puedes perder clientes potenciales o que recibirás oportunidades falsas.
El comando para bloquear una de estas páginas es:
Disallow:/thank-you/
Como estamos comentando en este artículo, usar robots.txt no es una garantía al 100% de que tu página no se indexará. Veamos dos maneras de estar seguro de que tu página bloqueada no se indexará.
Funciona junto al comando disallow. Usa ambos en tu directiva, como por ejemplo:
Disallow:/thank-you/
Noindex:/thank-you/
Funciona para indicar específicamente a los bots de Google que no rastreen los enlaces en una página. No forma parte del archivo robots.txt. Para usar el comando nofollow e impedir que las páginas se rastreen e indexen, debes encontrar el código fuente de la página específica que no quieres indexar.
Pega esto entre las etiquetas del título de apertura y cierre:
<meta name = “robots” content=”nofollow”>
Puedes utilizar “nofollow” y “noindex” a la vez. Usa esta línea de código:
<meta name = “robots” content=”noindex,nofollow”>
Generar robots.txt
Si te resulta difícil escribir robots.txt utilizando todos los formatos y la sintaxis necesaria, puedes usar herramientas que simplifiquen el proceso. Un buen ejemplo es nuestro generador de robots.txt gratis.
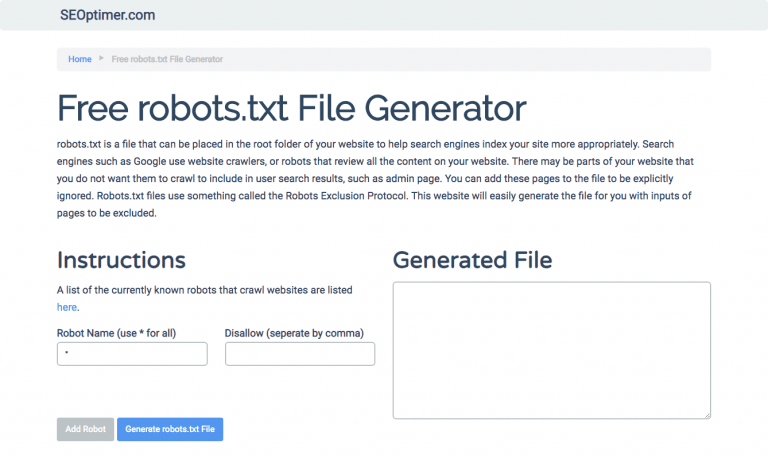
Esta herramienta te permite elegir el tipo de resultado que necesitas en tu sitio web y el archivo o directorios que quieres añadir. Incluso puedes probar tu archivo y ver qué está haciendo tu competencia.
Evalúa tu archivo robots.txt
Debes probar tu archivo robots.txt para estar seguro de que funciona como debe.
Utiliza el probador de robots.txt de Google.
Para ello, inicia tu sesión en tu cuenta de webmaster.
- A continuación, selecciona tu propiedad. En este caso, tu sitio web.
- Haz clic en “rastrear” en la barra lateral izquierda.
- Haz clic en “probador de robots.txt”.
- Reemplaza cualquier código existente con tu archivo robots.txt nuevo.
- Haz clic en “probar”.
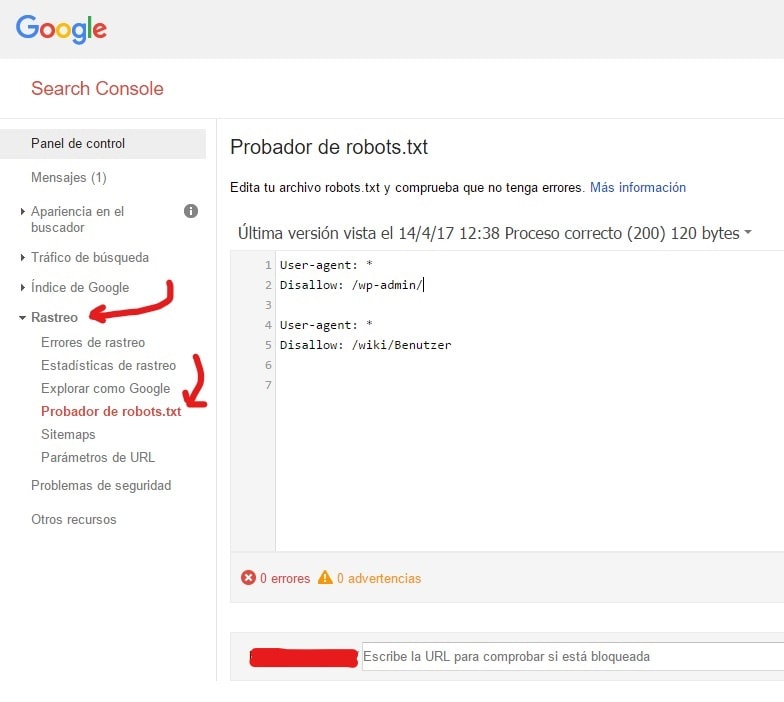
Si el archivo es válido, deberías ver un cuadro de texto que diga “permitido”. Para obtener más información, consulta esta guía detallada para el probador robots.txt Google.
Si tu archivo es válido, ahora es el momento de subirlo a tu directorio raíz o guardarlo como otro archivo robots.txt.
Cómo añadir robots.txt en tu página WordPress
Para añadir un archivo robots.txt a tu archivo de WordPress, nos centraremos en el complemento y las opciones de FTP.
Para la opción de complemento, puedes utilizar un plugin como All in One SEO Pack.
Para hacer esto, inicia tu sesión en tu panel de WordPress.
Desplázate hacia abajo hasta llegar a “complementos”.
Haz clic en “Añadir nuevo”.
Dirígete a “Buscar complementos”.
Escribe “All in One SEO Pack” (Paquete de SEO todo en uno).
Instálalo y actívalo.
En la sección Configuración General del complemento All in One SEO, puedes configurar las reglas noindex y nofollow para que se incluyan en tu archivo robots.txt.
Puedes especificar qué URL deben ser NOINDEX, NOFOLLOW. Si los dejas sin marcar, se indexarán de manera predeterminada:
Para crear reglas avanzadas en tu archivo robots.txt, haz clic en el administrador de funciones y después en el botón de activación justo debajo de robots.txt.

Ahora robots.txt aparece justo debajo del administrador de funciones. Haz clic ahí. Verás una sección llamada “Crear un archivo robots.txt”.
Hay una sección de creación de reglas que te permite elegir y completar las reglas que deseas para tu sitio, según lo que quieras y no quieras indexar.
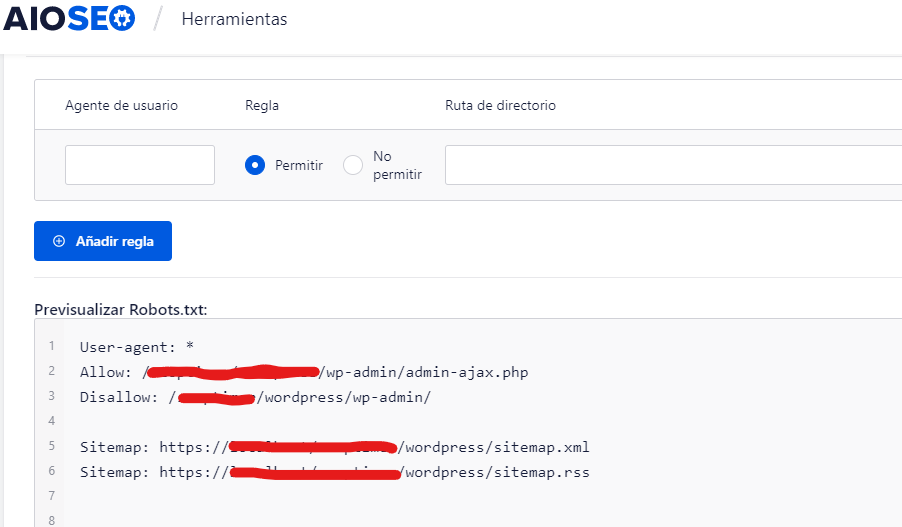
Una vez que termines de crear la regla, haz clic en “Añadir regla"=”.
La regla aparecerá en la carpeta robots.txt creada.
Verás un mensaje para indicar que se han actualizado las “Opciones todo en uno”.
Otro método que puedes usar consiste en cargar tu archivo robots.txt directamente a tu cliente FTP (protocolo de transferencia de archivos) como FileZilla.
Cuando hayas generado tu archivo robots.txt, puedes ubicarlo y reemplazarlo. Tu archivo robots.txt se ubicará en: “/applications/[FOLDER NAME]/public_html”.
Cómo editar el archivo robots.txt en Wix
Wix genera un archivo robots.txt para sitios web que utilizan la plataforma para crear páginas web. Para verlo, añade “/robots.txt” a tu dominio. Los archivos añadidos a robots.txt tienen que ver con la estructura de los sitios Wix; por ejemplo, los enlaces noflashhtml que no contribuyen al valor SEO de tu sitio con tecnología Wix.
No puedes editar tu archivo robots.txt si tu sitio funciona con Wix. Solo puedes usar otras opciones como añadir una “etiqueta noindex” a las páginas que no quieres que se indexen.
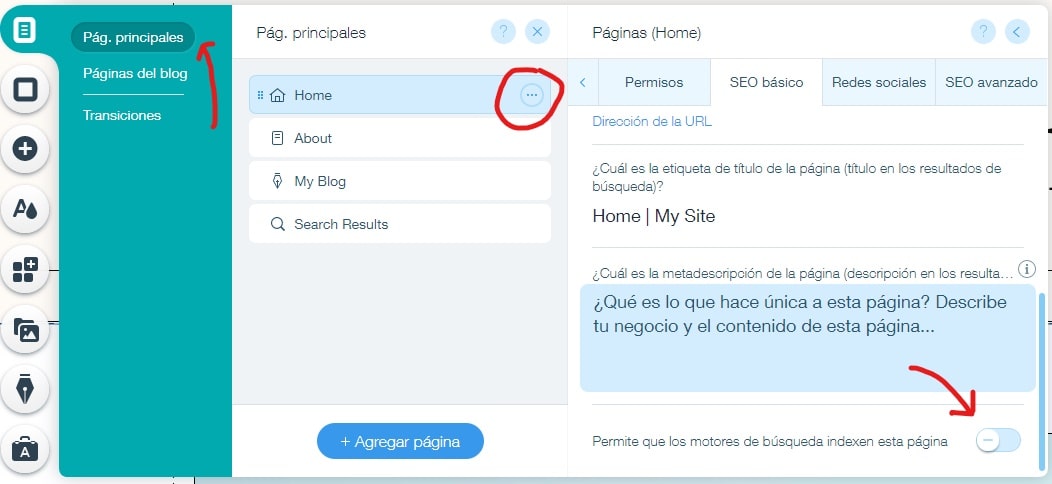
Para crear una etiqueta noindex para una página específica:
- Haz clic en el Menú del sitio.
- Haz clic en la opción Configuración para esa página específica.
- Selecciona la etiqueta SEO (Google).
- Activa Ocultar esta página de los resultados de búsqueda.
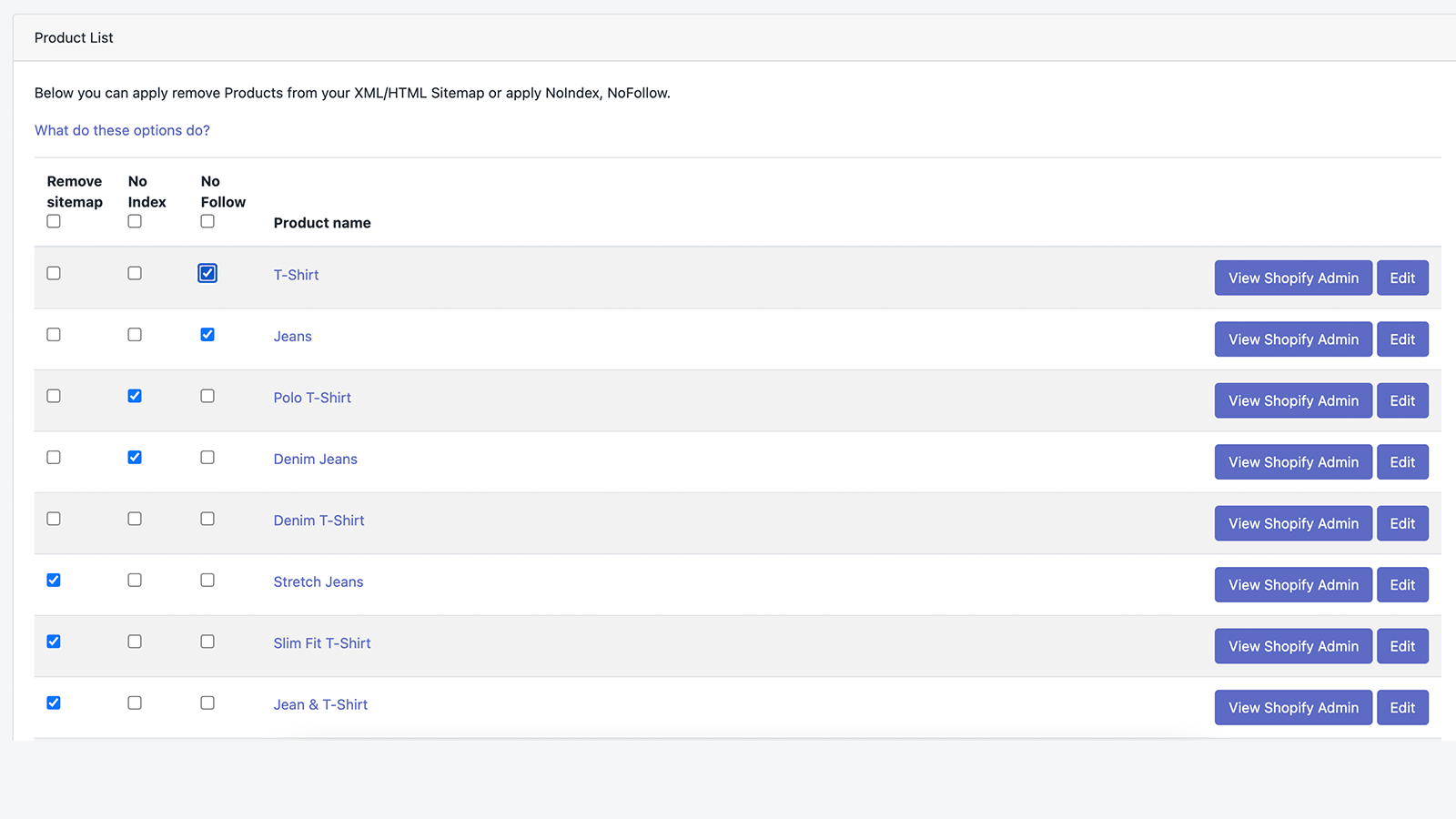
Cómo editar el archivo robots.txt en Shopify
Al igual que con Wix, Shopify añade automáticamente un archivo robots.txt no editable a tu sitio. Si no quieres que se indexen algunas páginas, debes añadir la “etiqueta noindex” o anular la publicación de la página. También puedes añadir metaetiquetas en la sección del encabezado de las páginas que no quieres que se indexen. Esto es lo que debes añadir a tu encabezado:
<meta name= “robots” content = “noindex”>
Shopify creó una guía completa sobre cómo ocultar páginas de los motores de búsqueda que puedes usar.
Otra opción consiste en descargar una aplicación llamada Sitemap & NoIndex Manager de Orbis Labs. Simplemente puedes verificar las opciones noindex o nofollow para cada página de tu sitio Shopify: