Vous savez quand vous utilisez Google pour rechercher un service, ou [trouver] des informations ? Et une fois que la page se charge, il y a toujours un site web tout en haut.
Les sites en position 1 dans la page de résultats du moteur de recherche Google (SERP) obtiennent la majorité de tous les clics. Inutile de dire qu'il est donc important de suivre les [meilleures] pratiques SEO pour essayer de maximiser la position de votre site dans le SERP.
Mais savez-vous comment Google trouve même votre site en premier lieu ?
La réponse est les crawlers de Google. Les crawlers de Google sont comme des petits robots numériques qui visitent des sites web et collectent des informations sur ces sites.
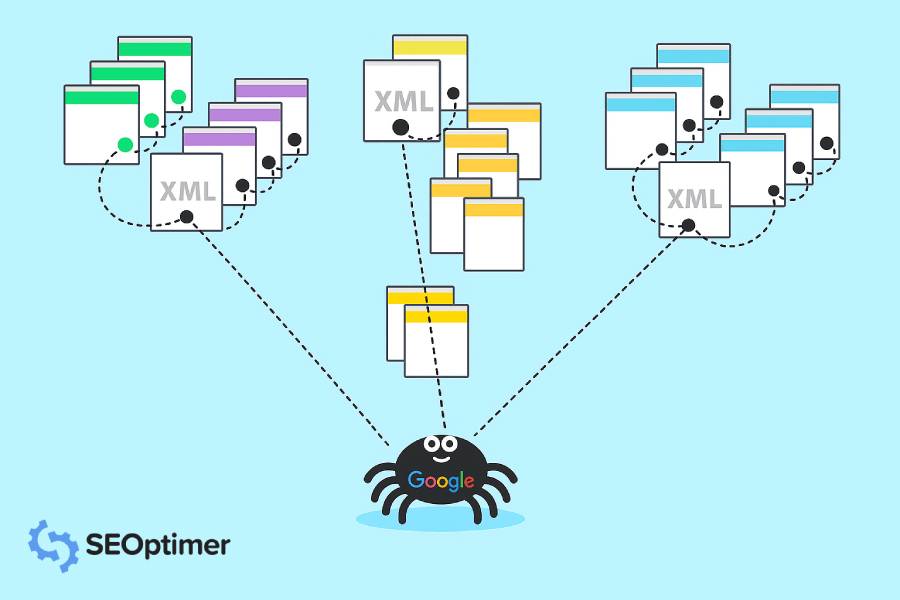
Ensuite, Google indexe toutes ces informations et les utilise pour améliorer son algorithme de recherche. Lorsqu'une personne tape une requête dans Google, l'algorithme de recherche parcourt toutes les informations indexées pour trouver les meilleurs résultats pour la [requête] de la personne.
Et c’est ainsi que Google est capable de vous apporter les meilleurs résultats lorsque vous recherchez quelque chose sur Internet !
Qu'est-ce qu'un "Google Crawler" ?
Un Google Crawler est également connu sous le nom de “robot” ou “araignée,” (vous comprenez, parce qu'ils rampent) et ils vont de site en site à la recherche de nouvelles informations à stocker dans leurs bases de données. Il existe 15 types de crawlers utilisés par Google mais le plus important est Googlebot.

Bien que Google soit puissant, il ne peut pas tout faire, chaque fois qu'une nouvelle page web est créée, Google ne le sait pas jusqu'à ce que cette page ait été explorée.
Google utilise le Googlebot pour obtenir constamment les dernières informations à stocker dans sa base de données.
Indexation Google vs Exploration Google
L'indexation ne se produit qu'après que le site web a été exploré par GoogleBot. Lorsqu'il est exploré, il est analysé, et les informations analysées à partir de ce site ou de cette page sont stockées dans l'index de Google.
L'index "catégorisera" et "classera" les pages en conséquence dans les résultats de recherche.
Pourquoi les "Google Crawlers" sont-ils importants ?
Alors pourquoi tout cela est-il [important] ?
Eh bien, disons que vous dirigez une entreprise et avez un site web. Vous voulez que votre site web soit aussi proche du sommet que possible. Si votre site web n'est pas "exploré" et "analysé", il ne se chargera pas sur la page de recherche.
Sans aucune présence sur Internet, vous ne pourrez pas atteindre votre public ou vos consommateurs. Le "crawling" et l'indexation rendent [cela] légèrement plus facile pour les sites web d'obtenir un peu d'attention.
Comment fonctionne un Google Crawler
Alors, vous savez ce que c'est mais comment cela fonctionne-t-il ? Bien que Google soit puissant, il ne peut pas tout faire, chaque fois qu'une nouvelle page web est créée, Google ne la connaît pas tant que cette page n'a pas été "explorée". Google utilise le Googlebot pour constamment obtenir des informations supplémentaires à stocker dans sa base de données.
Une fois que cette page web est explorée ou scannée. La page est restituée et reçoit un HTML, CSS, JavaScript, et du code tiers, qui sont tous nécessaires pour que le Googlebot indexe et classe les sites web. Googlebot, le plus grand robot d'exploration, est capable de voir et de restituer toutes les pages web et sites web avec Chromium.
Le Chromium est toujours en cours de mise à jour afin qu'il puisse rester stable et accomplir son travail avec précision. Ceci est disponible pour tout le monde et peut également être utilisé pour tester de nouvelles fonctionnalités et créer de nouveaux navigateurs.
Comment "rendre" votre site plus facile à [explorer]
Maintenant que nous savons avec quoi nous travaillons, travaillons sur la façon de rendre votre site web facile à explorer.
Voici quelques "conseils" et astuces pour faire de votre site web un aimant à robots d'indexation et grimper en haut de la page des résultats de recherche.
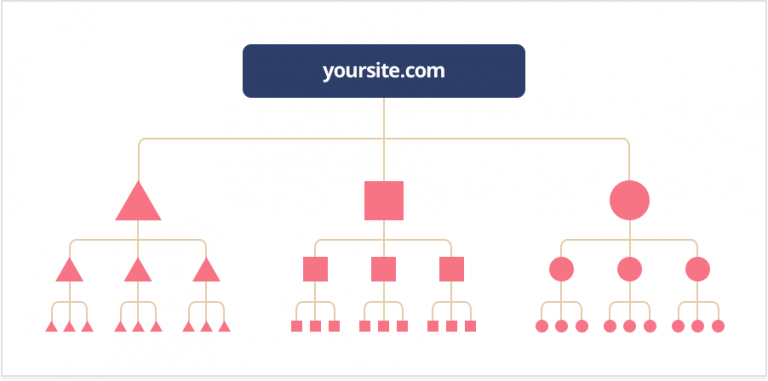
Liens internes
Les liens internes peuvent être votre meilleur ami pour l'exploration. Votre site a peut-être déjà été exploré par Google dans le passé mais récemment, vous avez peut-être ajouté plus de pages. Si le robot d'exploration connaît déjà votre site web, il se concentrera uniquement sur les pages principales.
N'oubliez pas, Google n'est pas alerté chaque fois qu'une nouvelle page est créée, il explore pour trouver ces pages.
L'utilisation de liens internes sur les pages principales guide le robot d'exploration là où il doit aller. Le meilleur endroit pour ces liens internes est votre page d'accueil, c'est la page qui reçoit le plus de trafic et où le robot d'exploration scannera en premier.
Backlinks
Backlinks sont un autre excellent moyen de faire explorer votre site. Cette méthode peut être utilisée pour “promouvoir” votre site web auprès du crawler.
Faire un lien vers un site web plus populaire augmentera vos chances d'être découvert par le robot d'exploration.
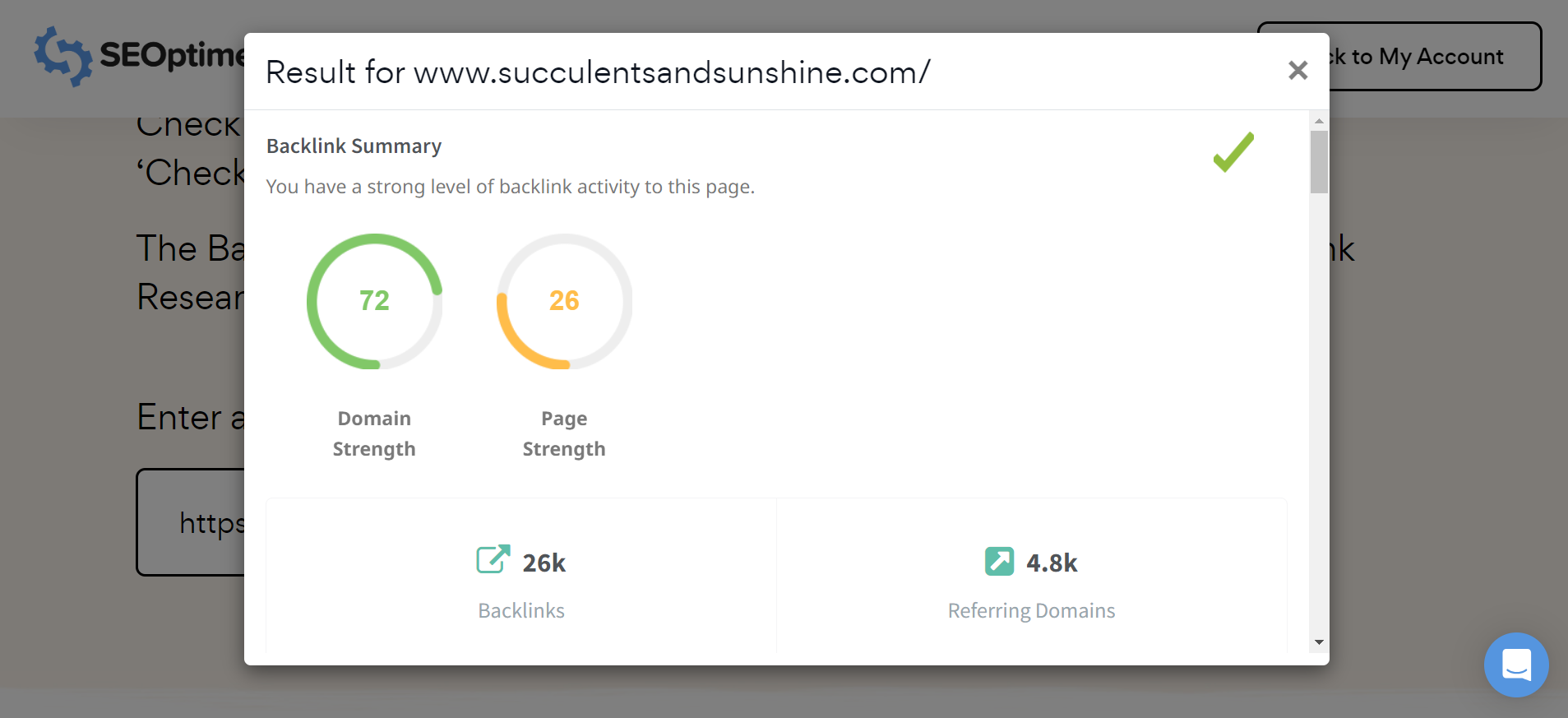
Remarque : Vous pouvez facilement vérifier le profil de [backlink] pour n'importe quel site, y compris vos concurrents, en utilisant l'outil gratuit de recherche de [backlink] de SEOptimer.
Images
Les images peuvent être explorées, en fait, il existe un robot d'exploration spécifique juste pour les images. Ce robot d'exploration est connu sous le nom de Googlebot Image, et il collecte des images pour la base de données.
Sitemaps
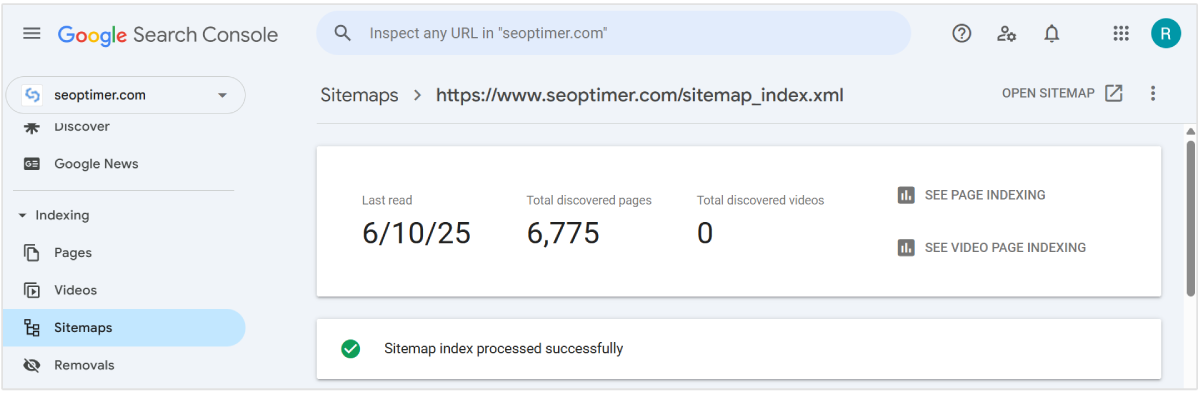
Il existe un moyen de dire à Google quelles pages vous souhaitez qu'il explore plus directement. Vous pouvez soumettre un plan du site avec une liste détaillée des pages que vous souhaitez faire explorer par Google.
Utilisez notre générateur de sitemap XML pour créer un sitemap de l'ensemble de votre site web. [Faites-le], nommez-le. Et téléchargez-le sur votre ordinateur pour le télécharger dans Google Search Console.
Profondeur de "clic"
La "profondeur de clic" (également connue sous le nom de "profondeur d'exploration") vous montre combien de travail un robot d'exploration devrait faire pour atteindre et analyser votre page. Vous ne voulez jamais que le robot d'exploration ait à faire trop de travail, vous voulez que votre page ou site web soit aussi convivial que possible pour les robots d'exploration.
Il devrait falloir environ trois clics ou moins, plus cela prend de temps, plus cela ralentit le robot d'exploration.
Une bonne structure doit vous permettre d'ajouter de nouvelles pages sans influencer votre profondeur de clic. Le robot d'exploration doit également pouvoir accéder facilement à ces pages.
FYI : Une bonne règle empirique est de s'assurer que vous pouvez naviguer d'une page de votre site à n'importe quelle autre page de votre site en pas plus de 3 clics. Cela garantit que Google peut trouver et indexer toutes vos pages efficacement. De plus, c'est excellent pour "l'expérience utilisateur".
Instructions d'indexation
Il y a des instructions que Google suit lors de l'exploration et de la création de pages. Robots.txt, balise noindex, balise méta robots, et X-Robots-Tag. Ne vous inquiétez pas, nous allons "décortiquer" cela pour vous.
Robots.txt. est un fichier de répertoire racine qui [withholds] certaines pages et contenus de Google. Lorsque le [crawler] analyse une page, il examinera ceci pour obtenir des informations. Si le [crawler] ne peut pas trouver ces informations, il cessera son exploration et la page ne fera pas partie des résultats de recherche.
La balise Noindex empêche tous les types de robots d'exploration de pouvoir analyser et indexer une page.
La balise méta robots peut aider à contrôler la façon dont une page est censée être indexée et chargée pour les internautes dans les résultats de recherche.
X-Robots-Tag, fait partie de l'en-tête HTTP et aidera à contrôler le comportement du crawler. Il supervise comment la page entière est indexée. Vous pouvez bloquer les images et vidéos sur une page en utilisant cette méthode. Vous pouvez également cibler des types de crawlers individuellement, mais uniquement si c’est spécifié.
Si le type de [crawler] n'est pas spécifié, alors les instructions seront pour tous les [Google crawlers].
Structure d'URL
Vous avez peut-être déjà entendu celle-ci auparavant mais assurez-vous d'avoir une URL conviviale.

Une URL qui est facile, une que vos consommateurs et les algorithmes adoreront. Essayez de garder votre URL aussi courte et "douce" que possible.
Si vous avez une longue URL, cela peut être déroutant non seulement pour l'œil humain mais aussi pour le bot Google.
Plus le Googlebot est "confus", plus il épuisera ses [ressources] de "crawling" et ce n'est certainement pas ce que vous voulez.
Problèmes courants (et solutions) avec le crawl de Google
Donc, vous avez une page mais elle ne fonctionne pas comme vous le souhaitez. Cela pourrait être parce que le robot d'exploration a des difficultés à essayer de "scanner" et "d'indexer" votre site.
Voici quelques problèmes courants que les gens ont rencontrés avec le "Google Crawling".
1. Google ne "crawle" pas votre site web
Assurez-vous de vérifier si votre page ou site est adapté à l'exploration. Cela signifie avoir une bonne URL, incorporer les liens internes et backlinks si nécessaire, ou prendre le temps de créer un plan du site pour montrer à Googlebot où explorer.
De plus, gardez à l'esprit qu'il peut falloir un certain temps à Google pour explorer et indexer votre site web car il doit venir vous trouver !
2. Vous avez été retiré de l'index de Google
Google supprimera un site web si elle en ressent le besoin, que ce soit par la loi, la pertinence ou pour ne pas avoir suivi les "directives" en place. Utilisez notre [SEO Crawler] pour vérifier tout ce qui pourrait bloquer le [crawler] de votre page.
Une fois que vous avez fait cela, vous pouvez soumettre votre site web à Google pour réexamen.
3. Vous avez du "contenu" en double
Le "contenu dupliqué" est une page qui a un contenu similaire à une autre page ou plusieurs URLS liant à une page.

Dans le cas de pages ayant un contenu similaire, ce qui pourrait également signifier que vous avez une version bureau et mobile d'une page. Cependant, l'exemple le plus courant de "contenu dupliqué" sur un certain nombre de pages.
Ces problèmes peuvent être évités et corrigés avec une URL canonique, ou URL qui sert de représentante pour ces pages dupliquées.
Google n'affichera que la page qu'ils estiment avoir le contenu le plus utile et la désigneront comme canonique. C'est la page qui sera explorée à la place des doublons.
Pour éviter cela, envisagez de réécrire le texte sur ces pages afin qu'elles ne soient pas confondues comme des doublons.
4. Il y a des [problèmes] de "rendu"
Si vous rencontrez des problèmes de rendu, assurez-vous que votre codage n'est pas trop volumineux. Votre codage doit être aussi propre que possible afin que le [crawler] puisse tout rendre correctement.
Si le crawler ne peut pas rendre la page, elle sera considérée comme "vide".
FAQ sur le robot d'exploration Google
Combien de temps faut-il à Google pour explorer un site web ?
Il faut normalement à Google de quelques jours à plusieurs semaines pour "crawler". Vous pouvez surveiller le "crawling" en utilisant le rapport d'état de l'index ou l'outil d'inspection des URL. Rappelez-vous, Google n'est pas informé chaque fois qu'un nouveau site web ou une nouvelle page est créé, il doit "crawler" et la trouver.
FYI : Les sites plus populaires sont explorés plus rapidement. Les sites tout nouveaux nécessiteront généralement des semaines pour être explorés, tandis que les sites réputés comme NY Times, Wall Street Journal et Wikipedia sont explorés plusieurs fois par jour.
Qu'est-ce que l'algorithme Google Crawler ?
L'algorithme du Google Crawler est basé sur la [facilité] avec laquelle votre site peut être exploré par le crawler. Cela inclut les [mots-clés], les URLs, le [contenu] et l'[information], le codage, et bien plus encore. Il vous appartient de fournir à Google le meilleur [contenu] et les meilleures [indications] afin qu'il puisse trouver votre page et commencer à l'explorer.
Toutes les pages sont-elles disponibles pour l'exploration ?
C'est une "bonne" question. La "réponse courte" est non. Certaines pages ne peuvent pas être explorées et indexées car elles sont protégées par mot de passe, ont été spécifiquement exclues des instructions d'indexation ou n'ont pas de liens sur leurs pages.
Quand mon site web apparaîtra-t-il dans la recherche Google ?
Cela variera toujours en fonction du temps qu'il faut pour que votre site web soit exploré et indexé. Cela pourrait prendre seulement quelques jours ou jusqu'à quelques semaines.
Quels sont les autres "web crawlers" ?
Oui ! Il existe des tonnes de robots d'exploration web en dehors des quinze de Google. Voici quelques-uns à titre de référence :
- Il y a BingBot utilisé par le moteur de recherche Bing.
- SlurpBot, utilisé par Yahoo! Ce "robot d'exploration" est un mélange entre Yahoo! et Bing, car Bing alimente principalement Yahoo!.
- ExaBot est le "moteur de recherche" et "robot d'exploration" le plus populaire en France.
- AppleBot est utilisé par la grande entreprise technologique Apple pour la [recherche] Spotlight et les suggestions Siri.
- Facebook, croyez-le ou non, utilise des liens pour envoyer du contenu à d'autres profils et ne peut explorer que si un lien est fourni.
Optimisez Votre Site pour le Crawl de Google
Maintenant que vous comprenez les bases de l'exploration Google et comment cela fonctionne, utilisez-le à votre avantage ! Faites indexer correctement votre site web et grimpez en haut de la page d'accueil des résultats de recherche. C’est gratuit et entièrement à votre disposition.