Bir hizmet aramak veya bilgi bulmak için Google kullandığınızda biliyor musunuz? Ve sayfa yüklendiğinde her zaman en üstte bir web sitesi olur.
Google arama motoru sonuç sayfasında (SERP) 1. sıradaki siteler tüm tıklamaların çoğunu alır. Dolayısıyla, SERP'deki sitenizin konumunu en üst düzeye çıkarmaya çalışmak için SEO en iyi uygulamalarını takip etmek önemlidir.
Ancak Google'ın sitenizi ilk etapta nasıl bulduğunu biliyor musunuz?
Cevap Google'un tarayıcılarıdır. Google'un tarayıcıları, web sitelerini ziyaret eden ve bu siteler hakkında bilgi toplayan küçük dijital robotlar gibidir.
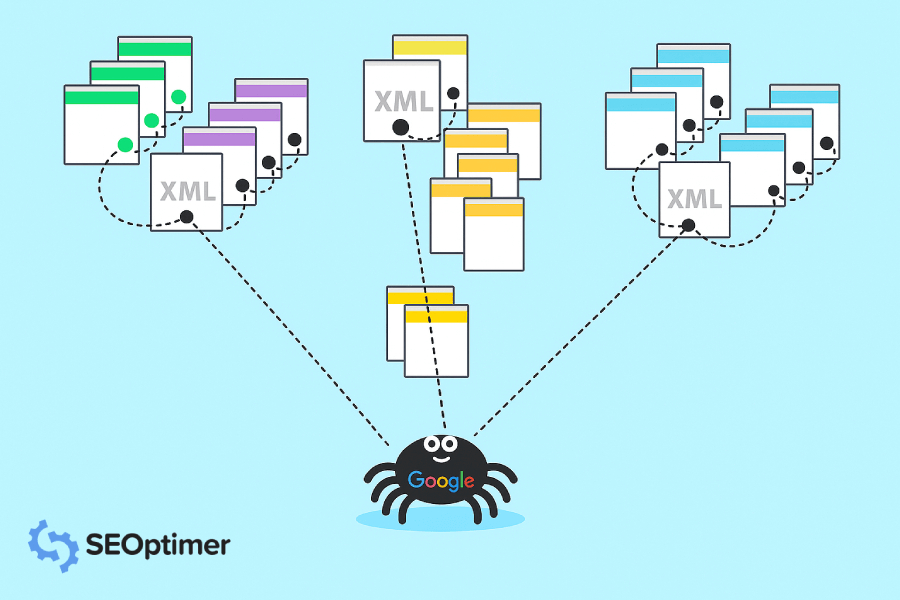
Ardından, Google tüm bu bilgileri dizine ekler ve arama algoritmasını geliştirmek için kullanır. Birisi Google'a bir sorgu yazdığında, arama algoritması kişinin sorgusu için en iyi sonuçları bulmak amacıyla dizine eklenmiş tüm bilgileri inceler.
Ve işte bu şekilde Google, internette bir şey aradığınızda size en iyi sonuçları sunabiliyor!
Google Crawler [nedir]?
Bir Google Crawler ayrıca “robot” veya “örümcek” olarak da bilinir (anladınız mı, çünkü [sürünürler]) ve veritabanlarında saklamak için yeni bilgi arayışında bir siteden diğerine giderler. Google tarafından kullanılan 15 çeşit crawler vardır ancak en önemlisi Googlebot'tur.

Google güçlü olsa da her şeyi yapamaz, her yeni web sayfası oluşturulduğunda Google bu sayfayı tarayana kadar hakkında bilgi sahibi olmaz.
Google, en son bilgileri sürekli olarak veritabanında depolamak için Googlebot'u kullanır.
Google Dizin Oluşturma vs Google Tarama
İndeksleme yalnızca web sitesi GoogleBot tarafından tarandıktan sonra gerçekleşir. Tarandığında, taranır ve o site veya sayfadan taranan bilgiler Google dizininde saklanır.
Dizin, sayfaları arama sonuçlarında [uygun şekilde] "sınıflandıracak" ve "sıralayacaktır".
Google "Crawlers" Neden Önemlidir?
Öyleyse neden tüm bunlar "önemli"?
Şey, diyelim ki bir işletme yönetiyorsunuz ve bir web siteniz var. Web sitenizin mümkün olduğunca üst sıralarda olmasını istiyorsunuz. Eğer web siteniz taranmaz ve taranmazsa arama sayfasında yüklenmez.
Hiçbir internet varlığı olmadan, kitlenize veya tüketicilerinize ulaşamazsınız. Tarama ve dizine ekleme, web sitelerinin biraz dikkat çekmesini biraz daha kolay hale getirir.
Google Crawler Nasıl Çalışır
Yani, ne olduğunu biliyorsunuz ama nasıl çalışıyor? Google güçlü olsa da her şeyi yapamaz, her yeni web sayfası oluşturulduğunda Google bu sayfayı tarayana kadar bundan haberdar olmaz. Google, veritabanında saklamak için sürekli olarak ek bilgi edinmek amacıyla Googlebot'u kullanır.
Bir web sayfası tarandığında veya tarandıktan sonra. Sayfa işlenir ve Googlebot'un web sitelerini dizine eklemesi ve sıralaması için gereken HTML, CSS, JavaScript ve üçüncü taraf kodu verilir. En büyük tarayıcı olan Googlebot, tüm web sayfalarını ve web sitelerini Chromium ile görebilir ve işleyebilir.
Chromium her zaman güncelleniyor, böylece stabil kalabilir ve görevini doğru bir şekilde yerine getirebilir. Bu, herkese açıktır ve yeni özellikleri test etmek ve yeni tarayıcılar yapmak için de kullanılabilir.
Sitenizi Tarama İçin Daha Kolay Hale [Getirmek]
Şimdi neyle çalıştığımızı bildiğimize göre, web sitenizin taranmasını kolaylaştırmak üzerinde çalışalım.
İşte web sitenizi bir tarayıcı mıknatısı haline getirmek ve arama sonuçları sayfasında üst sıralara çıkmak için bazı ipuçları ve püf noktaları.
Dahili Bağlantılar
Dahili bağlantılar tarama için en iyi arkadaşınız olabilir. Siteniz daha önce Google tarafından taranmış olabilir ancak son zamanlarda daha fazla sayfa eklemiş olabilirsiniz. Tarayıcı sitenizi zaten biliyorsa, yalnızca ana sayfalara odaklanacaktır.
Unutmayın, Google yeni bir sayfa her oluşturulduğunda bilgilendirilmez, bu sayfaları bulmak için tarar.
Ana sayfalarda dahili bağlantılar kullanmak, tarayıcının gitmesi gereken yeri yönlendirir. Bu dahili bağlantılar için en iyi yer ana sayfanızdır; bu sayfa en fazla trafiği alan ve tarayıcının ilk tarayacağı sayfadır.
Geri bağlantılar
Geri bağlantılar, sitenizin taranması için başka harika bir yoldur. Bu yöntem, web sitenizi tarayıcıya “tanıtmak” için kullanılabilir.
Daha popüler bir web sitesine bağlantı vermek, tarayıcı tarafından keşfedilme şansınızı artıracaktır.
Not: Rakipleriniz de dahil olmak üzere herhangi bir sitenin geri bağlantı profilini kolayca kontrol edebilirsiniz, SEOptimer'ın ücretsiz Geri Bağlantı Araştırma aracını kullanarak.
Görseller
Görseller taranabilir, aslında sadece görseller için özel bir tarayıcı vardır. Bu tarayıcı Googlebot Image olarak bilinir ve veritabanı için görselleri toplar.
Sitemapler
Google'a hangi sayfaları daha doğrudan taramasını istediğinizi söylemenin bir yolu vardır. Google tarafından taranmasını istediğiniz sayfaların ayrıntılı bir listesini içeren bir site haritası gönderebilirsiniz.
Tüm web sitenizin site haritasını oluşturmak için XML Site Haritası Oluşturucu kullanın. Yapın, adlandırın ve Google Arama Konsolu'na yüklemek için bilgisayarınıza indirin.
Tıklama Derinliği
Tıklama derinliği (aynı zamanda tarama derinliği olarak da bilinir) bir tarayıcının sayfanıza ulaşmak ve taramak için ne kadar iş yapması gerektiğini gösterir. Tarayıcının çok fazla iş yapmasını asla istemezsiniz, sayfanızın veya web sitenizin mümkün olduğunca tarayıcı dostu olmasını istersiniz.
"Üç tıklama" veya daha az sürmelidir, ne kadar uzun sürerse tarayıcıyı o kadar yavaşlatır.
İyi bir yapı, yeni sayfalar eklemenize izin vermeli ve tıklama derinliğinizi etkilememelidir. Tarayıcı da bu sayfalara kolayca ulaşabilmelidir.
BİLGİNİZE: İyi bir genel kural, sitenizdeki herhangi bir sayfadan başka bir sayfaya en fazla 3 tıklamayla geçiş yapabilmenizden emin olmaktır. Bu, Google'ın tüm sayfalarınızı verimli bir şekilde bulup dizine eklemesini sağlar. Ayrıca, kullanıcı deneyimi için harikadır.
İndeksleme Talimatları
Google'ın tarama ve fikir sayfaları oluşturma sırasında izlediği talimatlar vardır. Robots.txt, noindex etiketi, robots meta etiketi ve X-Robots-Tag. Endişelenmeyin, bunu sizin için açıklayacağız.
Robots.txt, Google'dan belirli sayfaları ve içeriği saklayan bir kök dizin dosyasıdır. Tarayıcı bir sayfayı tararken, bilgi için buna bakacaktır. Eğer tarayıcı bu bilgiyi bulamazsa, tarama işlemini durduracak ve sayfa arama sonuçlarının bir parçası olmayacaktır.
Noindex etiketi, tüm tarayıcı türlerinin bir sayfayı taramasını ve dizine eklemesini engeller.
Robotlar meta etiketi, bir sayfanın arama sonuçlarında web gezginleri için nasıl dizine eklenmesi ve yüklenmesi gerektiğini kontrol etmeye yardımcı olabilir.
X-Robots-Tag, HTTP başlığının bir parçasıdır ve tarayıcının davranışını kontrol etmeye yardımcı olur. Tüm sayfanın nasıl dizine eklendiğini denetler. Bu yöntemle bir sayfadaki görüntüleri ve videoları engelleyebilirsiniz. Ayrıca, yalnızca belirtilmişse, tarayıcı türlerini bireysel olarak hedefleyebilirsiniz.
Eğer tarayıcı türü belirtilmemişse, talimatlar tüm Google tarayıcıları için olacaktır.
URL Yapısı
Bunu daha önce duymuş olabilirsiniz ancak kullanıcı dostu bir URL'ye sahip olduğunuzdan emin olun.

Hem tüketicilerinizin hem de algoritmaların seveceği kolay bir URL. URL'nizi mümkün olduğunca kısa ve öz tutmaya çalışın.
Uzun bir URL'ye sahipseniz, bu yalnızca insan gözü için değil, Google botu için de kafa karıştırıcı olabilir.
Googlebot ne kadar kafası karışırsa, tarama kaynaklarını o kadar fazla tüketecektir ve bu kesinlikle istemediğiniz bir durumdur.
Google Tarama ile İlgili Yaygın Sorunlar (ve Çözümleri)
Yani, bir sayfanız var ancak istediğiniz gibi performans göstermiyor. Bu, tarayıcının sitenizi tarama ve dizine ekleme konusunda zorluk yaşaması nedeniyle olabilir.
İnsanların Google Tarama ile karşılaştığı birkaç yaygın sorun burada.
1. Google Web Sitenizi Tarayamıyor
Sayfanızın veya sitenizin tarama dostu olup olmadığını kontrol ettiğinizden emin olun. Bu, iyi bir URL'ye sahip olmak, gerekirse dahili ve geri bağlantıları entegre etmek veya Googlebot'a nereleri tarayacağını göstermek için bir site haritası oluşturmak için zaman ayırmak anlamına gelir.
Ayrıca, Google'ın web sitenizi taraması ve dizine eklemesi biraz zaman alabilir çünkü sizi bulması gerekiyor!
2. Google’ın Dizini'nden Kaldırıldınız
Google, yasalar, alaka düzeyi veya mevcut yönergeleri takip etmemek gibi bir ihtiyaç duyarsa bir web sitesini kaldıracaktır. Sayfanızdan tarayıcıyı engelleyebilecek herhangi bir şeyi kontrol etmek için SEO Crawler'ımızı kullanın.
Bunu yaptıktan sonra, web sitenizi yeniden değerlendirme için Google'a gönderebilirsiniz.
3. Yinelenen İçeriğiniz Var
Yinelenen içerik, başka bir sayfaya benzer içeriğe sahip olan bir sayfa veya birden fazla URL'nin tek bir sayfaya bağlandığı bir sayfadır.

Benzer içeriğe sahip sayfalarınızın olması durumunda, bu aynı zamanda bir sayfanın masaüstü ve mobil sürümüne sahip olduğunuz anlamına gelebilir. Ancak, birçok sayfadaki yinelenen içeriğin en yaygın örneği.
Bunlar hem önlenebilir hem de kanonik URL veya bu yinelenen sayfalar için temsilci olarak hizmet veren bir URL ile düzeltilebilir.
Google, en faydalı içeriğe sahip olduğuna inandıkları sayfayı gösterecek ve onu "kanonik" olarak etiketleyecektir. Bu, kopyalar yerine taranacak olan sayfadır.
Bunu önlemek için, bu sayfalardaki metni [yeniden yazmayı] düşünün, böylece kopyalarla karıştırılmasınlar.
4. "Render" Sorunları Var
Eğer renderleme sorunları yaşıyorsanız, kodlamanızın çok büyük olmadığından emin olun. Kodlamanızın mümkün olduğunca temiz olması gerekir ki tarayıcı her şeyi düzgün bir şekilde render edebilsin.
Tarama aracı sayfayı işleyemezse, [boş] kabul edilecektir.
Google Tarayıcı [Sıkça Sorulan Sorular]
Google'ın bir web sitesini taraması ne kadar sürer?
Google'un tarama yapması genellikle günlerden haftalara kadar sürebilir. Tarama işlemini, Dizin Durumu Raporu veya URL denetim aracı kullanarak izleyebilirsiniz. Unutmayın, Google yeni bir web sitesi veya sayfa oluşturulduğunda bildirilmez, bunu tarayıp bulması gerekir.
Bilginize: Daha popüler siteler daha hızlı taranır. Yepyeni sitelerin taranması genellikle haftalar alırken, NY Times, Wall Street Journal ve Wikipedia gibi saygın siteler günde birkaç kez taranır.
Google Crawler algoritması nedir?
Google Crawler algoritması, sitenizin ne kadar tarayıcı dostu olduğuna dayanır. Bu, "anahtar kelimeler", "URL'ler", "içerik ve bilgi", "kodlama" ve çok daha fazlasını içerir. Google'a en iyi içeriği ve rehberliği sağlamanız, sayfanızı bulup taramaya başlaması için size bağlıdır.
Tüm sayfalar tarama için [mevcut] mu?
Bu iyi bir soru. Kısa cevap hayır. Bazı sayfalar, şifre korumalı oldukları, indeks talimatlarından özellikle çıkarıldıkları veya sayfalarında herhangi bir bağlantı bulunmadığı için taranamaz ve indekslenemezler.
Web sitem Google aramasında ne zaman görünecek?
Bu, web sitenizin taranıp dizine eklenmesinin ne kadar sürdüğüne bağlı olarak her zaman değişecektir. Bu sadece birkaç gün sürebilir veya birkaç hafta kadar uzun olabilir.
Başka hangi web tarayıcıları var?
Evet! Google’ın on beş tanesinin dışında bir sürü web tarayıcısı var. İşte referans için bazıları:
- Arama motoru Bing tarafından kullanılan BingBot vardır.
- Yahoo! tarafından kullanılan SlurpBot. Bu web tarayıcısı, Yahoo! ve Bing'in bir karışımıdır, çünkü Bing esas olarak Yahoo!'yu destekler.
- ExaBot, Fransa'daki en popüler arama motoru ve tarayıcıdır.
- AppleBot, büyük teknoloji firması Apple tarafından spotlight araması ve Siri önerileri için kullanılır.
- İnan ya da inanma, Facebook içerikleri diğer profillere göndermek için bağlantılar kullanır ve yalnızca bir bağlantı sağlandığında tarayabilir.
Sitenizi Google Tarama için "optimize" Edin
Artık Google Tarama'nın temelini ve nasıl çalıştığını anladığınıza göre, bunu avantajınıza kullanın! Web sitenizin düzgün bir şekilde dizine eklenmesini sağlayın ve arama sonuçları ana sayfasının en üstüne çıkın. Tamamen ücretsiz ve kullanımınıza hazır.