De SEO Crawler van SEOptimer helpt je de pagina's op je website te scannen en te [controleren] om technische SEO-problemen op [schaal] te identificeren.
In plaats van pagina's één voor één te controleren, bekijkt de crawler de structuur van je site, analyseert SEO-elementen over meerdere URL's en markeert problemen die van invloed kunnen zijn op indexering, bruikbaarheid of zichtbaarheid in zoekmachines.
In deze gids zul je:
- "Voer uw eerste crawl uit"
- "Bekijk het crawlrapport"
- "Leer hoe u aangepaste crawlregels instelt"
- "Plan en exporteer websitecrawls"
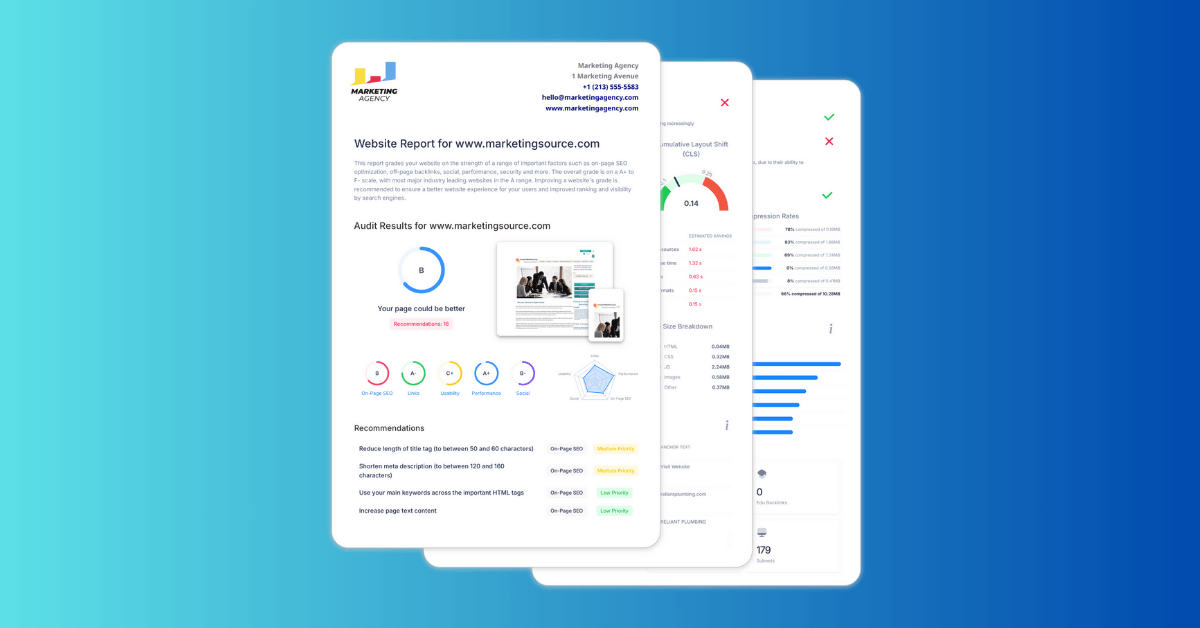
Wat is de SEO Crawler van SEOptimer?
SEOptimer's SEO Crawler is een website-crawlingtool die de pagina's van uw site scant en SEO-gerelateerde problemen identificeert op meerdere URL's.
Het werkt door pagina's op uw website te bezoeken en technische en on-page SEO-gegevens te verzamelen zoals paginatitels, metabeschrijvingen, koppen, statuscodes, indexeerbaarheid, redirects en kapotte links.
Na voltooiing van de crawl genereert de tool een crawlrapport dat de "problemen" samenvat die op uw site zijn gevonden en groepeert ze op type en ernst.
Dit maakt het gemakkelijker om terugkerende problemen te herkennen en prioriteiten te stellen voor oplossingen, vooral op grotere websites waar handmatige [pagina]controles niet praktisch zijn.
De SEO Crawler is nuttig voor het uitvoeren van technische SEO-audits, het monitoren van de gezondheid van de site in de loop der tijd, en het controleren of belangrijke pagina's "SEO best practices" volgen.
Hoe u uw eerste crawl uitvoert
Om je eerste crawl uit te voeren, klik op de optie “Website Crawls” onder “Auditing” in je SEOptimer-dashboard.
Voeg vervolgens de URL van je website toe aan het open veld en klik op “Crawl toevoegen.”
Dat is het, je bent begonnen met je eerste SEOptimer site-crawl!
Onze SEO Crawler zal nu alle pagina's op uw site doorlopen om eventuele [problemen] die ze kunnen hebben te [identificeren].
Crawls worden in realtime uitgevoerd, maar de totale crawltijd varieert afhankelijk van de grootte van uw website en het aantal pagina's dat gescand moet worden.
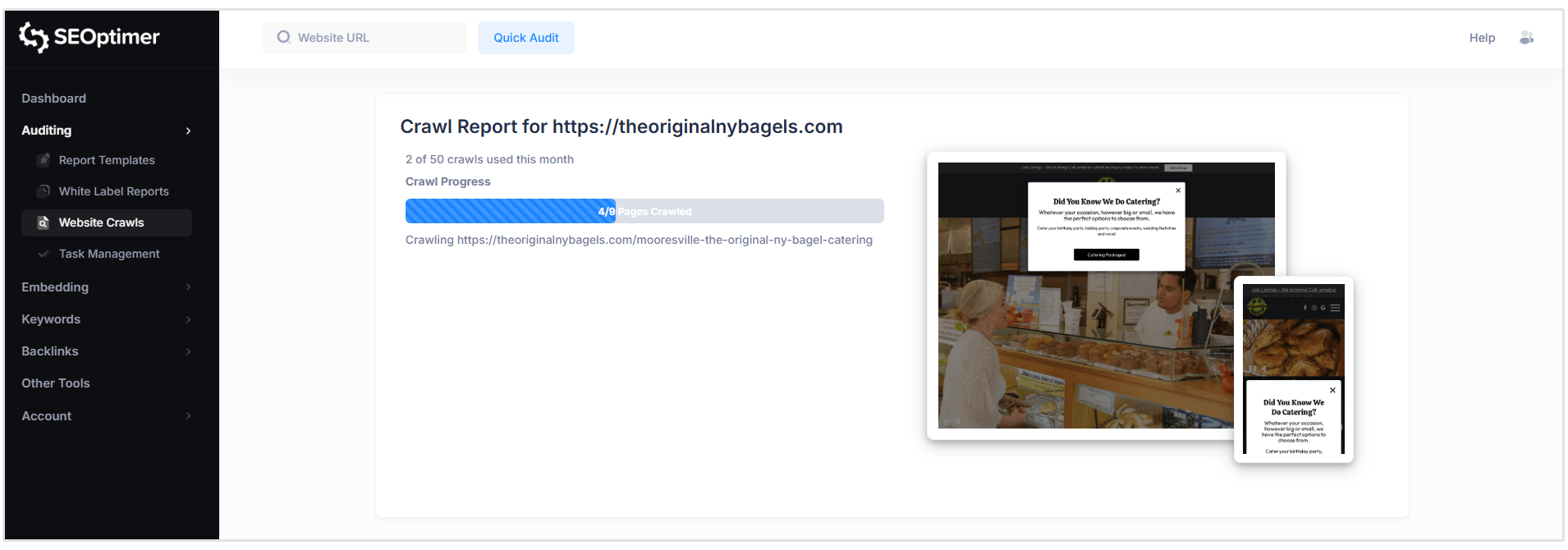
Terwijl de crawl nog bezig is, kunt u beginnen met het beoordelen van [problemen] zodra ze worden gedetecteerd door het [crawlrapport] te openen.
Wat kun je Zien in Elk Crawlrapport?
Wanneer onze tool klaar is met het crawlen van je site, zie je drie hoofdsecties:
- Rapportkop
- [Geïdentificeerde] Pagina's
- [Samenvatting van het probleem]
Laten we door elk van deze secties [lopen].
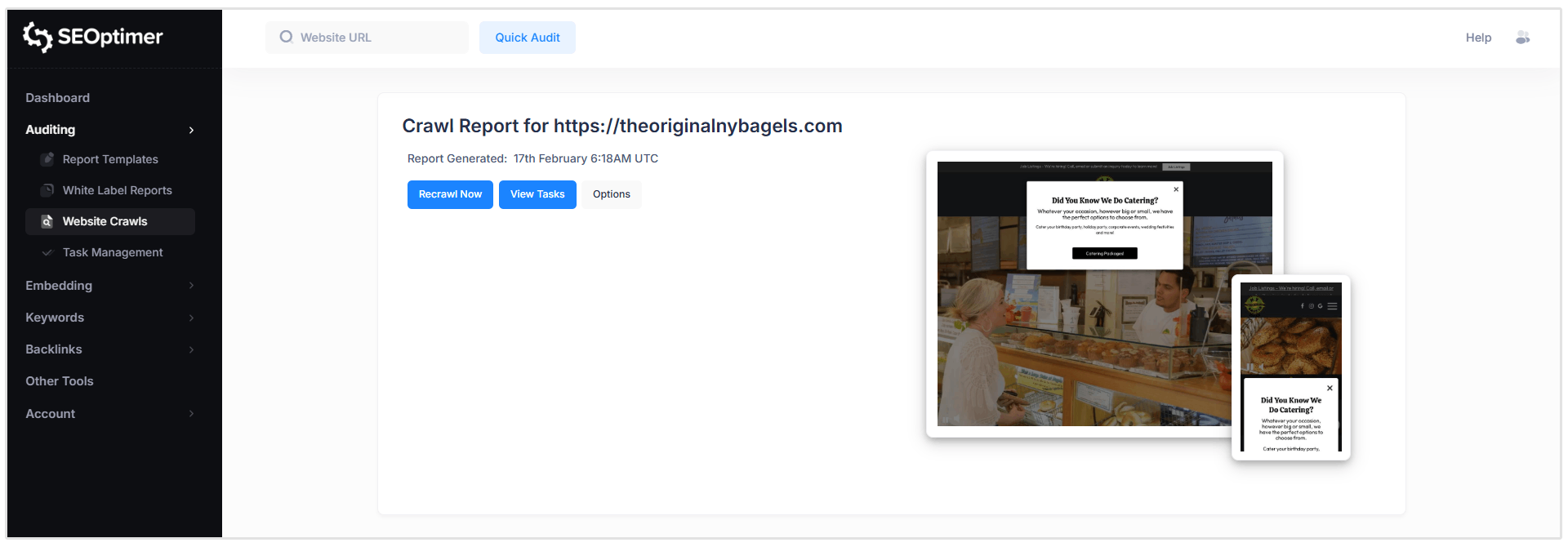
Rapportkop
Hier kunt u zien wanneer het rapport is gegenereerd, een nieuwe crawl aanvragen, taken bekijken en crawlregels aanpassen. (meer over deze functies later)
Geïdentificeerde Pagina's
Dit gedeelte toont een tabel van alle pagina's die tijdens de crawl zijn ontdekt, samen met de SEO-problemen die voor elke pagina zijn gedetecteerd.
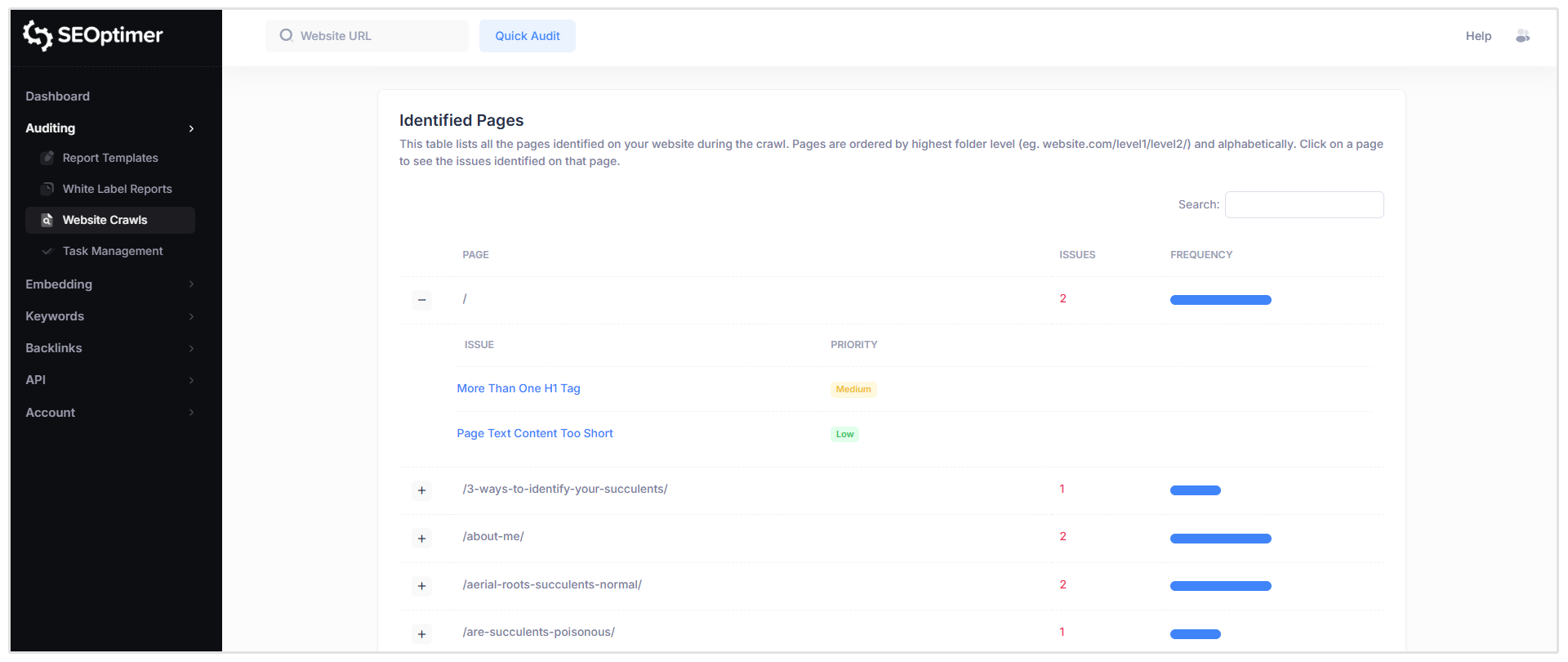
Wanneer je op een specifieke pagina klikt (bijvoorbeeld het hoofdpaden van de homepage weergegeven als “/”), zie je een lijst van alle [problemen] die voor die URL zijn gemarkeerd, inclusief het [ernstniveau] van elk [probleem].
Om meer [details] te bekijken, klik op een [probleem] in de lijst.
Bijvoorbeeld, het selecteren van “Meer Dan Eén H1 Tag” zal een gedetailleerde uitsplitsing van dat probleem voor de geselecteerde pagina openen.
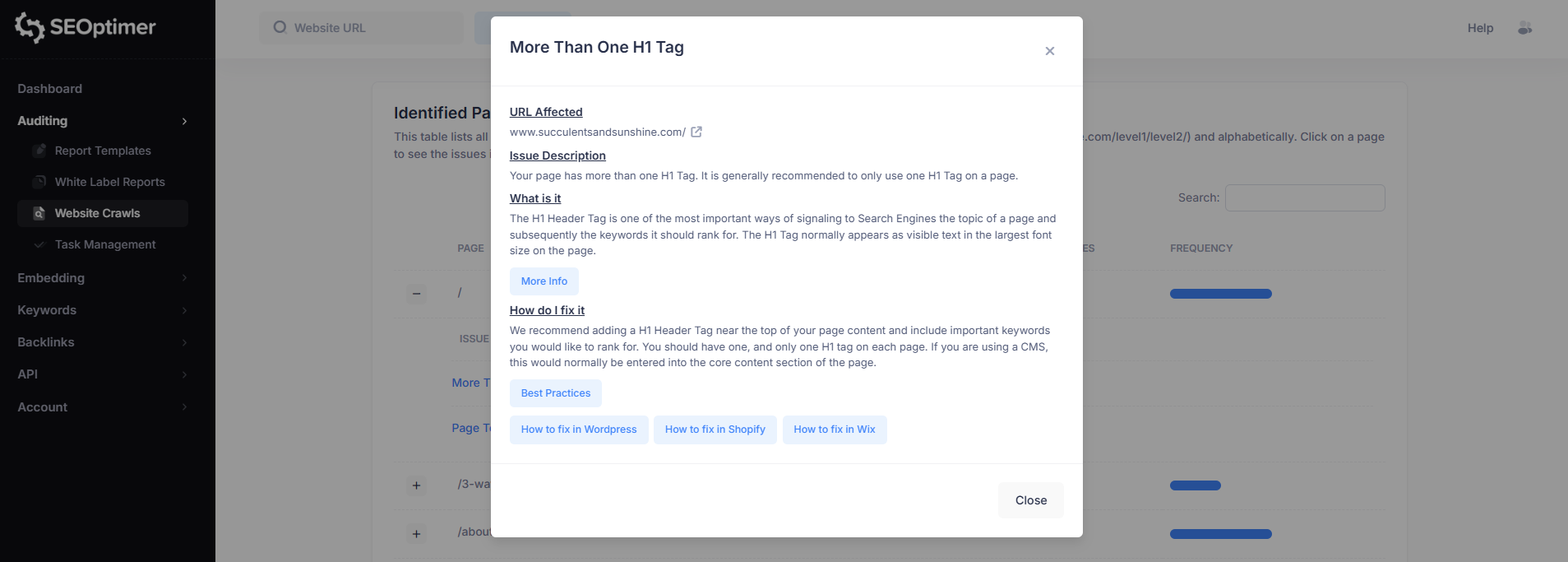
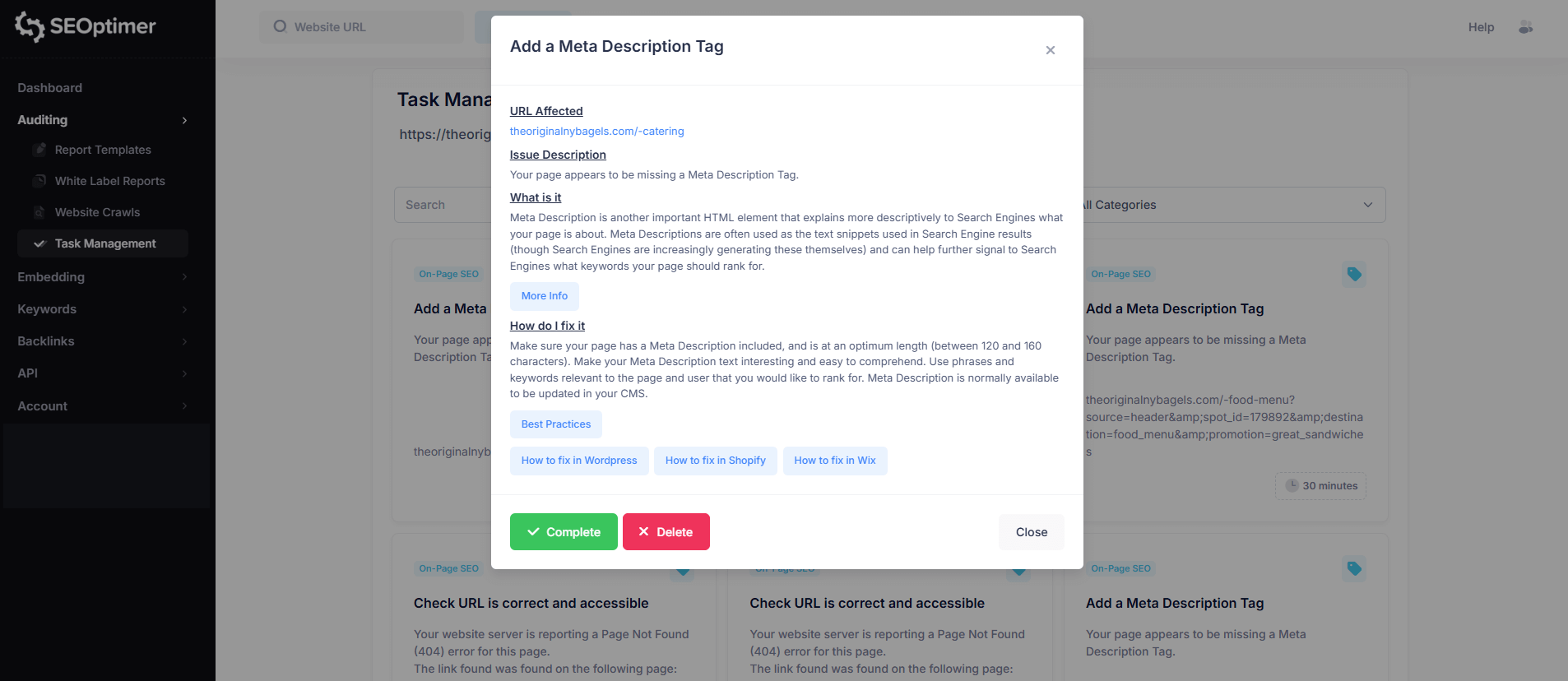
Deze "issue view" bevat:
- Betrokken URL
- [Probleem]beschrijving
- Wat het [probleem] betekent
- Hoe het op te lossen
Elk "probleem pop-up" zal ook links bevatten naar ondersteunende gidsen om je te helpen het [probleem] op je website op te lossen.
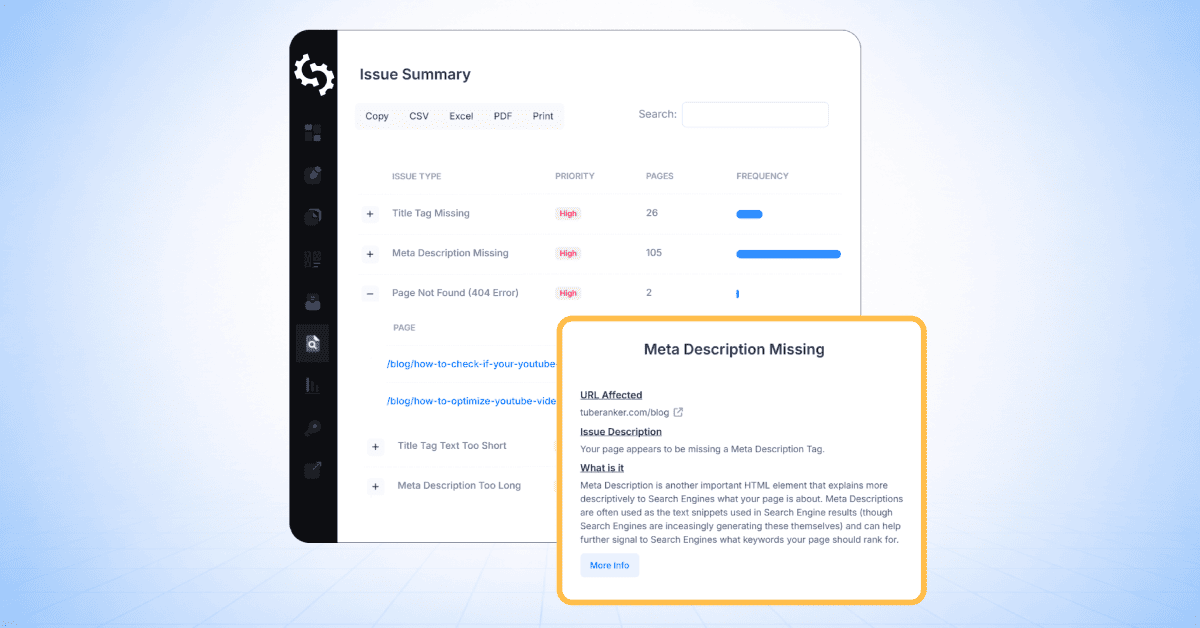
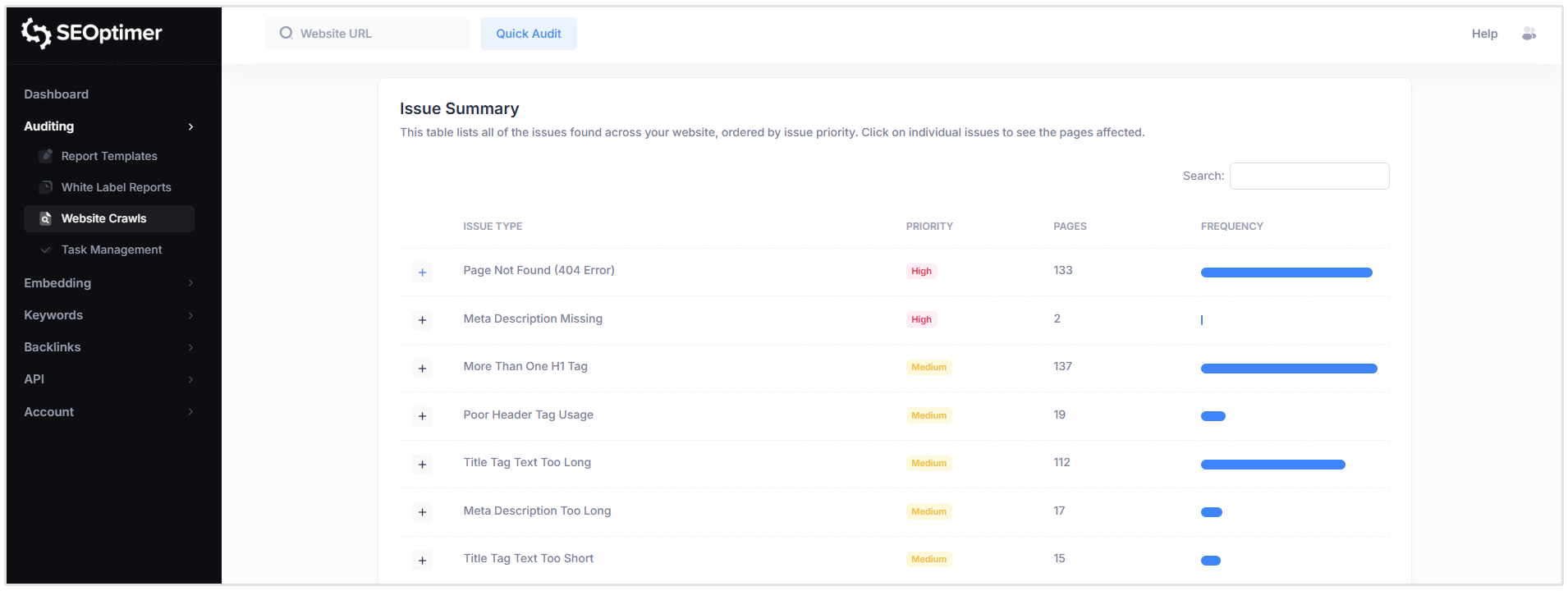
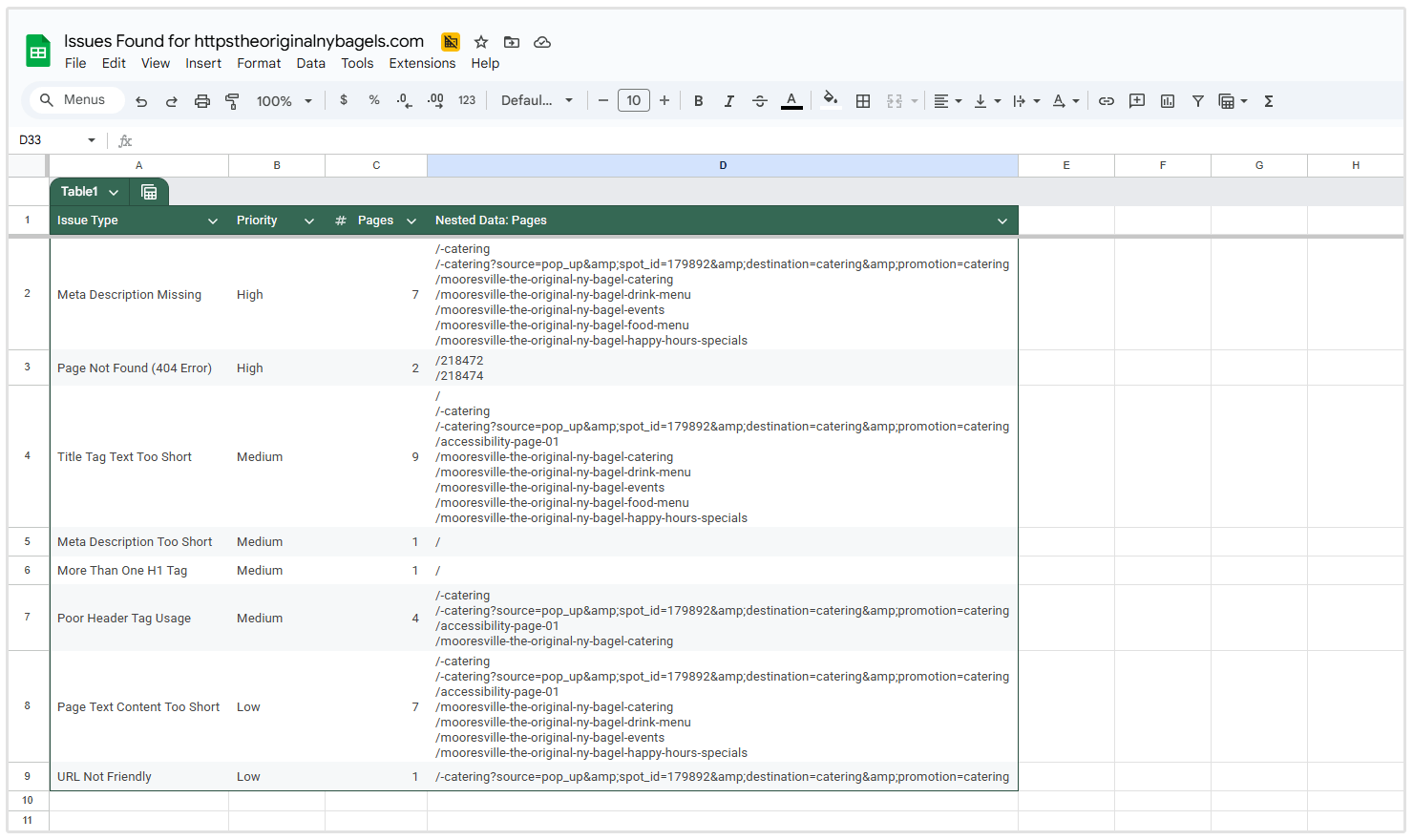
Samenvatting van het probleem
De sectie Samenvatting van Problemen biedt een overzicht van alle SEO-problemen die op je website zijn gedetecteerd, gegroepeerd op type probleem en gerangschikt op prioriteit.
Voor elk probleem toont de tabel:
- [Probleem]type
- [Prioriteit]niveau
- Aantal [getroffen] pagina's
Dus in de onderstaande screenshot van een site die ik heb gecrawld, kun je zien dat er 137 pagina's zijn die meer dan één H1-tag hebben, 133 pagina's die 404-fouten hebben, en 2 pagina's die geen meta beschrijving hebben.
Wanneer je de samenvatting van het probleem hebt beoordeeld, kun je doorgaan met het configureren van crawl-instellingen en het verkennen van aanvullende SEO Crawler-opties.
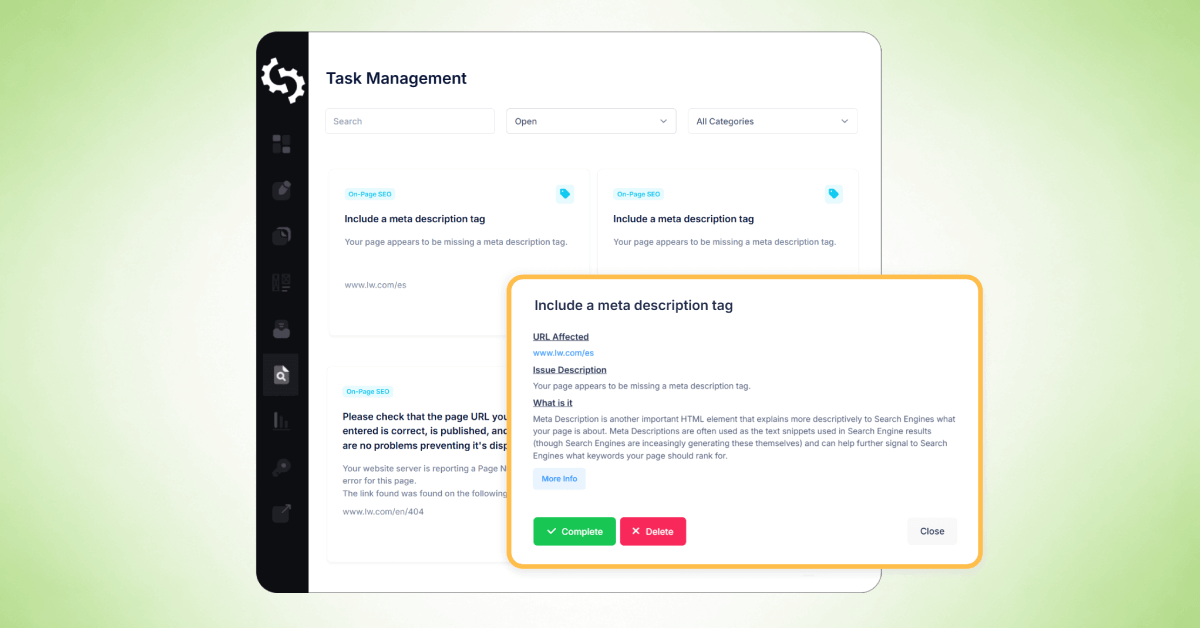
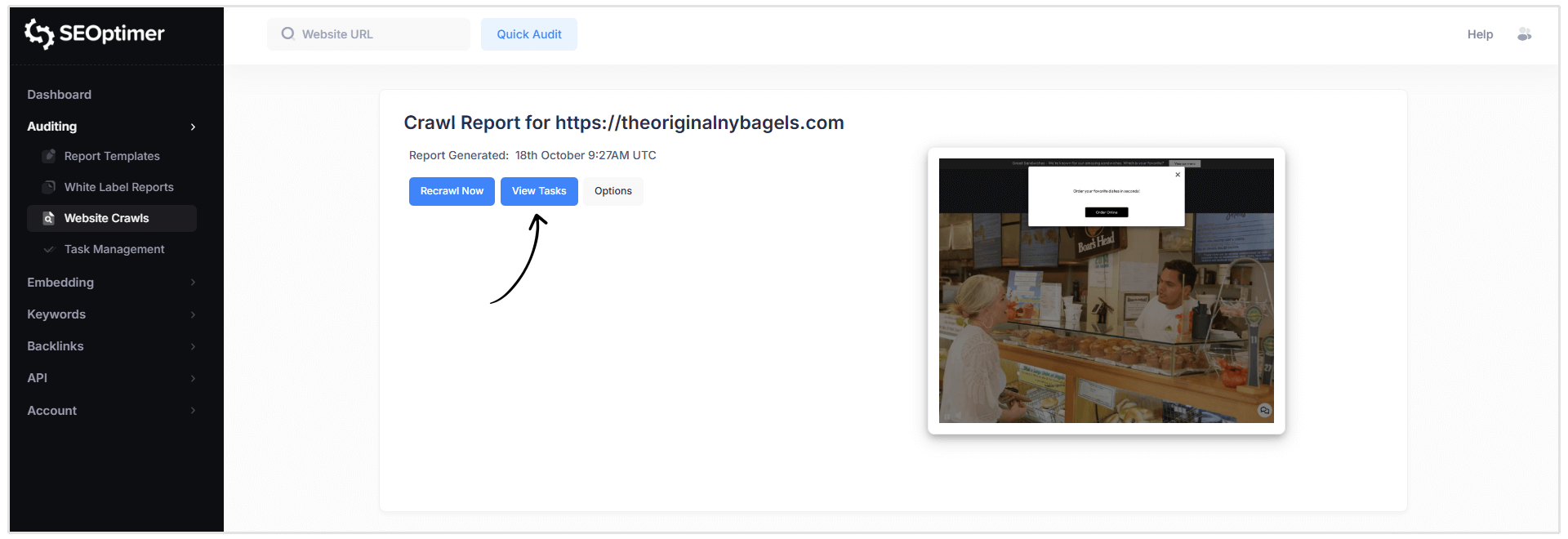
[Taken Bekijken]
Na het voltooien van een website crawl, kun je de Taakbeheer functie van SEOptimer gebruiken om de problemen die in je crawl rapport zijn geïdentificeerd te organiseren en bij te houden.
De "Task Management"-tool zet crawlproblemen om in een takenlijst die je kunt afwerken in een enkele werkruimte, waardoor het gemakkelijker wordt om reparaties te prioriteren en de voortgang in de tijd bij te houden.
Hoe de "Taaklijst" te openen
U kunt uw takenlijst op twee manieren openen:
- Klik op de blauwe “Taken bekijken” knop in de Crawlrapport koptekst.
- Of selecteer Taakbeheer in het navigatiemenu aan de linkerkant van je dashboard.
Opmerking: Als u meerdere websites hebt gecrawld, kunt u wisselen tussen takenlijsten met behulp van het dropdownmenu bovenaan de pagina Taakbeheer.
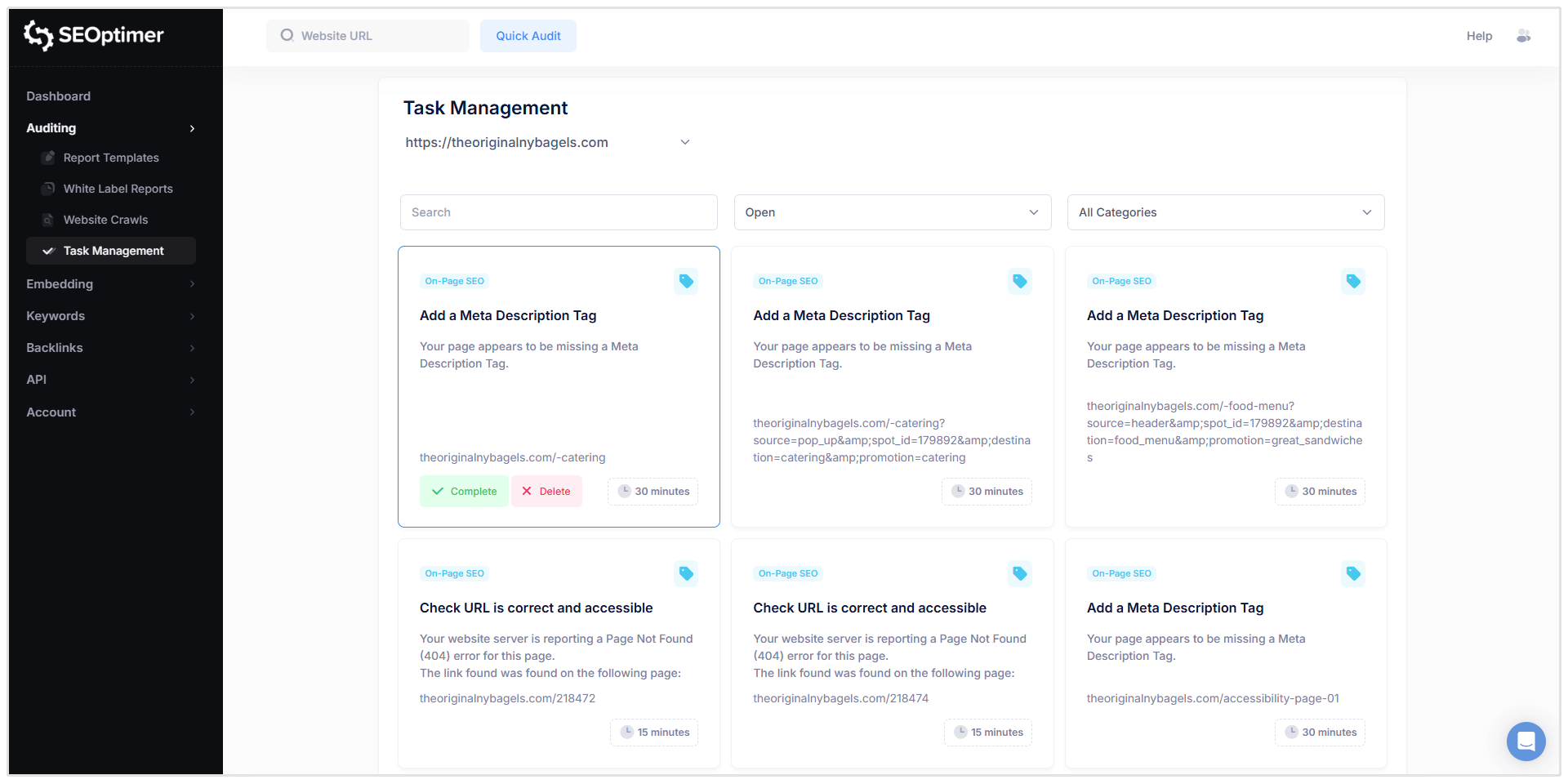
Filteren en Beheren van Taken
Taken kunnen worden gefilterd op:
- Status (Open, Voltooid, Verwijderd)
- Categorie (bijv. On-Page SEO, Links, enz.)
Wanneer je op een taak klikt, zie je gedetailleerde informatie vergelijkbaar met het crawlrapport, inclusief:
- Getroffen URL
- [Probleembeschrijving]
- Wat het probleem betekent
- Hoe het op te lossen
- [Opties] om de taak te voltooien of deze uit de takenlijst te verwijderen
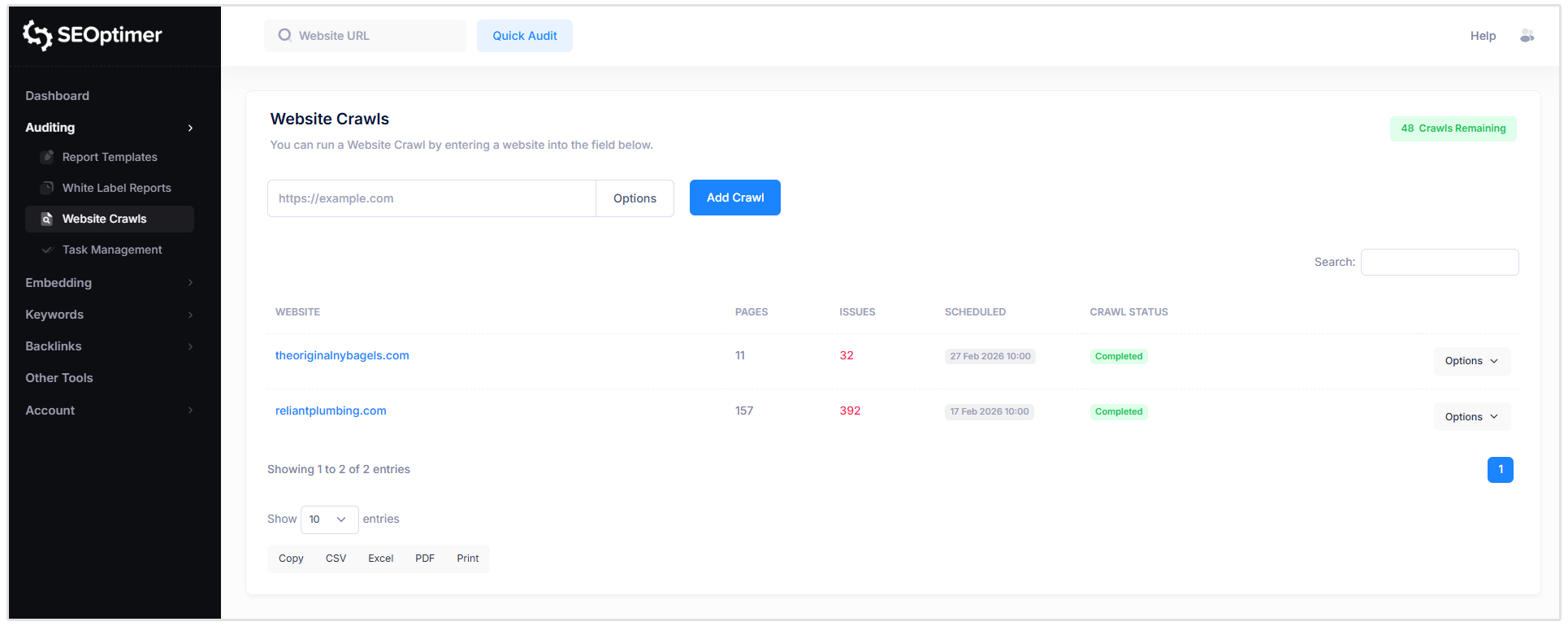
Hoe "Crawls" [in te plannen]
U heeft ook de optie om crawls in te plannen die wekelijks of maandelijks worden uitgevoerd. Deze functie is vooral handig voor bureaus die meerdere klantwebsites beheren.
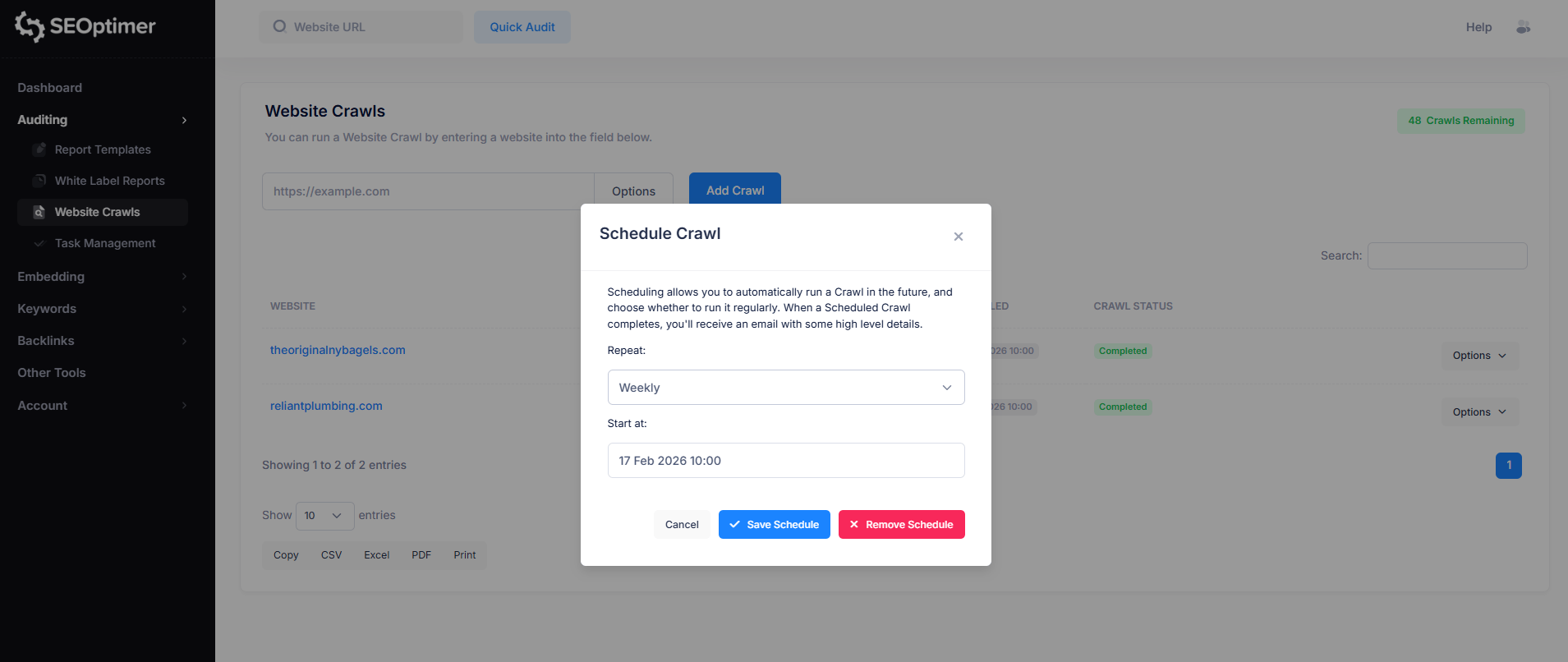
Om een [crawl]schema in te stellen, klik je eenvoudigweg op de “Opties” knop rechts van de website waarvoor je een [crawl] wilt plannen.
Klik vervolgens op de optie “Schema” en pas het [crawl]schema aan volgens jouw voorkeur.
Wanneer een geplande crawl is voltooid, ontvang je een e-mail met enkele "high level" details.
Uw eigen "Crawl Rules" instellen
De SEO Crawler bevat opties voor [crawl]configuratie waarmee je kunt bepalen welke pagina's in een [crawl] worden opgenomen.
Deze instellingen zijn nuttig als u de resultaten wilt beperken, dubbele URL's wilt vermijden of ervoor wilt zorgen dat de crawler zich gedraagt in overeenstemming met de [indexeringsregels] van uw site.
"Houd" Robots.txt "uitsluitingen in acht"
Standaard kan de crawler de regels volgen die zijn gedefinieerd in het robots.txt-bestand van uw site. Dit bepaalt of de crawler pagina's moet vermijden die als niet toegestaan zijn gemarkeerd.
- Ingeschakeld (aanbevolen): De crawler zal de uitsluitingen in robots.txt respecteren en geblokkeerde pagina's overslaan.
- Uitgeschakeld: De crawler zal de regels in robots.txt negeren en proberen alle pagina's te crawlen die hij kan openen.
In de meeste gevallen wordt het aanbevolen om robots.txt te gehoorzamen, vooral bij het uitvoeren van crawls op live productiesites.
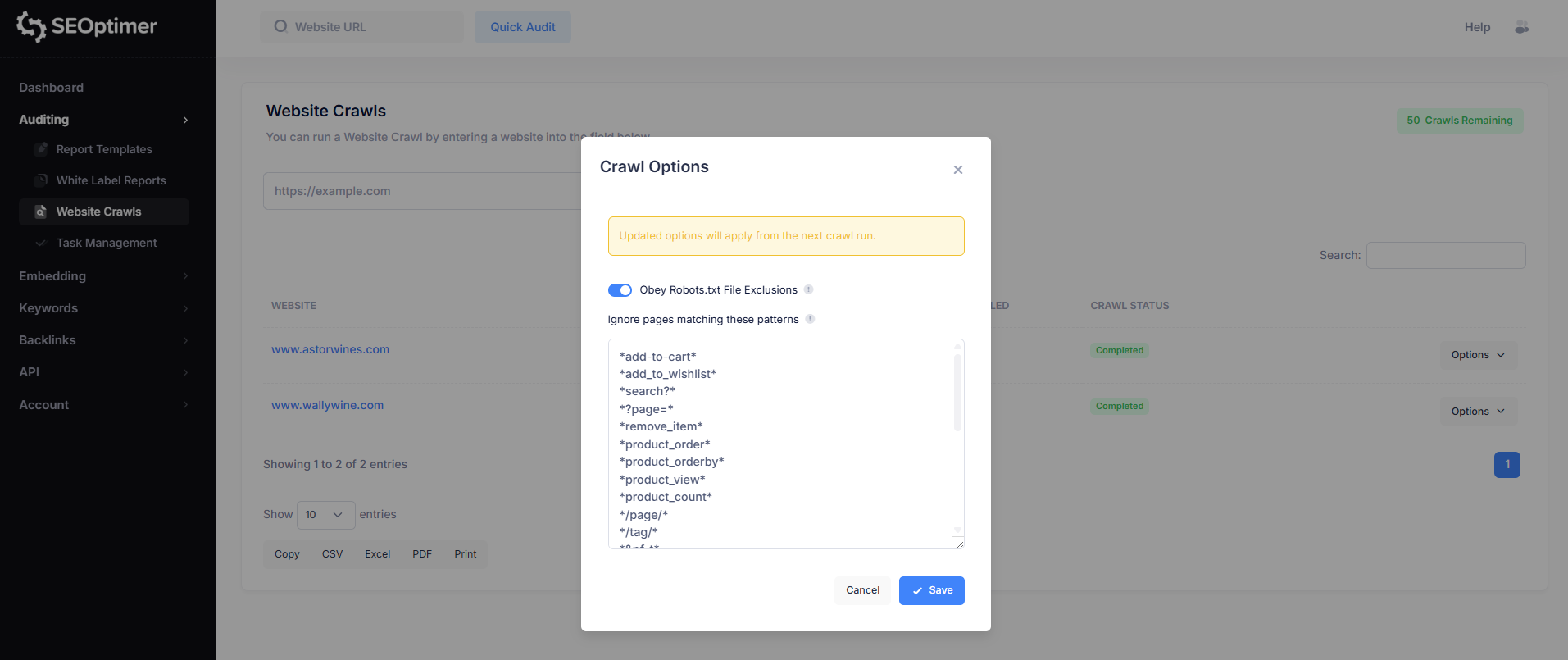
Negeer pagina's die overeenkomen met deze patronen
Sommige websites genereren meerdere versies van dezelfde pagina met behulp van URL-parameters (bijvoorbeeld "sorteren", "filteren", "paginering" of "trackingcodes").
Dit is vooral gebruikelijk op "ecommerce websites".
De “Negeer pagina's die overeenkomen met deze patronen” optie stelt je in staat om deze duplicaat of lage waarde URL's uit te sluiten van het crawlen. Dit helpt om crawlresultaten schoner te houden en maakt het eenvoudiger om probleemrapportages te beoordelen.
Dit is een meer geavanceerde functie en is voornamelijk nuttig voor websites met een groot aantal parameter-gebaseerde URL's.
SEOptimer bevat een standaardset uitsluitingspatronen om veelvoorkomende op parameters gebaseerde duplicaten te filteren, maar je kunt je eigen regels toevoegen indien nodig.
Deze patronen volgen de standaard robots.txt-matching syntax.
Als je niet bekend bent met de regels van robots.txt of URL-patroonmatching, wordt het aanbevolen om de basisprincipes te bekijken voordat je aangepaste crawl-uitsluitingen toevoegt. Onjuiste patronen kunnen voorkomen dat belangrijke pagina's worden gecrawld.
Hier zijn een paar nuttige referenties:
- Robots.txt - De Ultieme Gids
- Robots.txt Introductie en Gids | Google Zoeken Central
- Hoe Google de "robots.txt"-specificatie [interpreteert]
- Robots.txt "Syntax"
Hoe "Crawl Data" te [exporteren]
Elke tabel in het SEO Crawler-rapport bevat ingebouwde exportopties, waarmee je de crawlresultaten buiten het platform kunt downloaden of delen.

Onderaan elke tabel zie je exportknoppen waarmee je de gegevens in verschillende formaten kunt uitvoeren:
- CSV: Download de tabel als een .csv-bestand (handig voor spreadsheets en gegevensverwerking).
- Excel: Exporteer de tabel als een Excel-bestand voor rapportage of verdere analyse.
- PDF: Genereer een PDF-versie van de tabel voor delen of documentatie.
- Print: Open een printvriendelijke versie van de tabel.
Exporteren geldt voor de specifieke tabel die u bekijkt, waardoor het eenvoudig is om [issue lists], paginarapporten of gefilterde resultaten te downloaden indien nodig.
Afronden
SEOptimer’s SEO Crawler maakt het eenvoudig om technische en on-page SEO-problemen op uw gehele website te identificeren in een enkele crawl.
Door het bekijken van het crawlrapport en het gebruik van de ingebouwde takenlijst, kunt u snel bevindingen uit de crawl omzetten in "actiegerichte verbeteringen".
Voor de beste resultaten, overweeg regelmatige crawls te plannen om veranderingen in de tijd te volgen en nieuwe problemen te detecteren naarmate uw website groeit.
Hulp Nodig?
Live Chat: Klik op Live Chat (rechtsonder)
Email: [email protected]
Reactietijd: Binnen 24 uur