Si recibiste la notificación de advertencia ‘Se ha indexado aunque un archivo robots.txt la ha bloqueado’ en la consola de búsqueda de Google, tienes que solucionarlo lo antes posible, ya que podría estar afectando a la capacidad de tus páginas para clasificarse en las páginas de los resultados del motor de búsqueda (SERPS).
Un archivo robots.txt es un archivo que se encuentra dentro del directorio de tu sitio web para ofrecer diferentes instrucciones a los rastreadores de los motores de búsqueda, como el bot de Google, sobre qué archivos deben y no deben ver.
‘Se ha indexado aunque un archivo robots.txt la ha bloqueado’ indica que Google ha encontrado tu página, pero también ha encontrado una instrucción para ignorarla en tu archivo robots (lo que significa que no aparecerá en los resultados).
A veces esto es algo intencional o accidental por una serie de razones que comentaremos a continuación, pero que se puede solucionar.
Esta es una captura de pantalla de la notificación: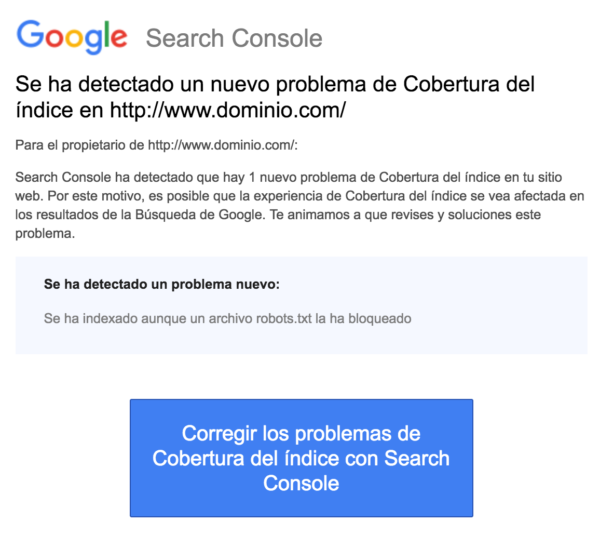
Identificar la(s) página(s) o URL(s) afectada(s)
Si has recibido una notificación de Google Search Console (GSC), debes identificar las páginas o URL específicas.
Puedes ver las páginas con problemas indexados, aunque bloqueadas por robots.txt, en Google Search Console>>Cobertura. Si no ves la etiqueta de advertencia, entonces no tienes ningún problema.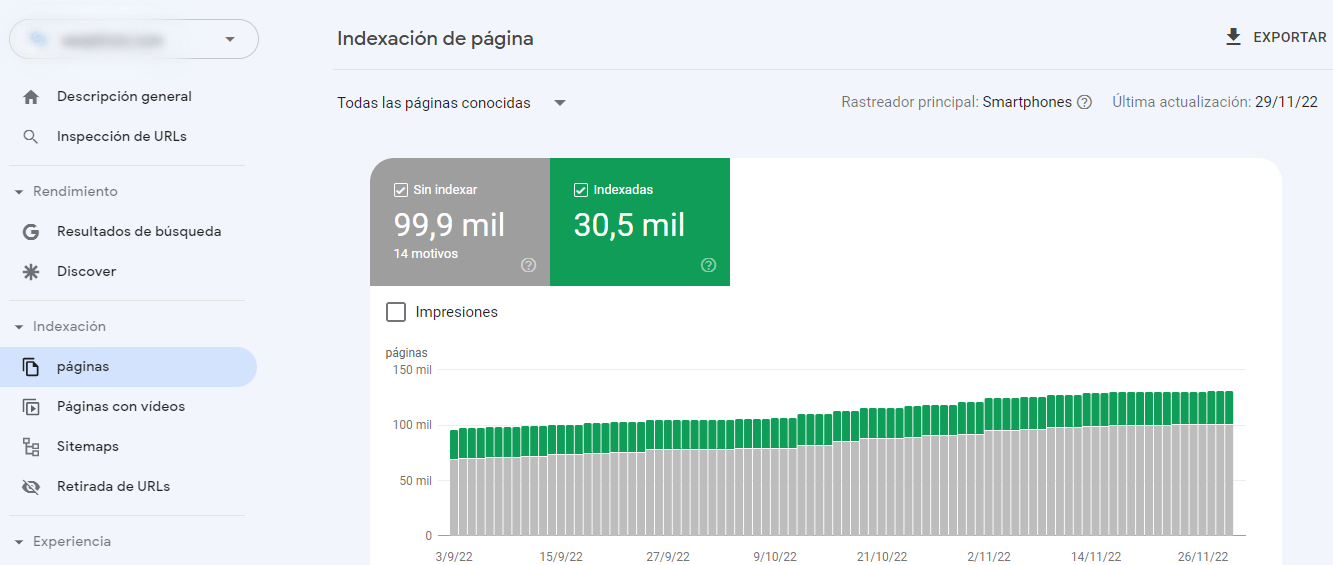
Una forma de evaluar tu robots.txt consiste en usar nuestro probador robots.txt. Quizás estés de acuerdo con lo que sea que está siendo bloqueado que siga “bloqueado”; por lo tanto, no necesitas realizar ninguna acción.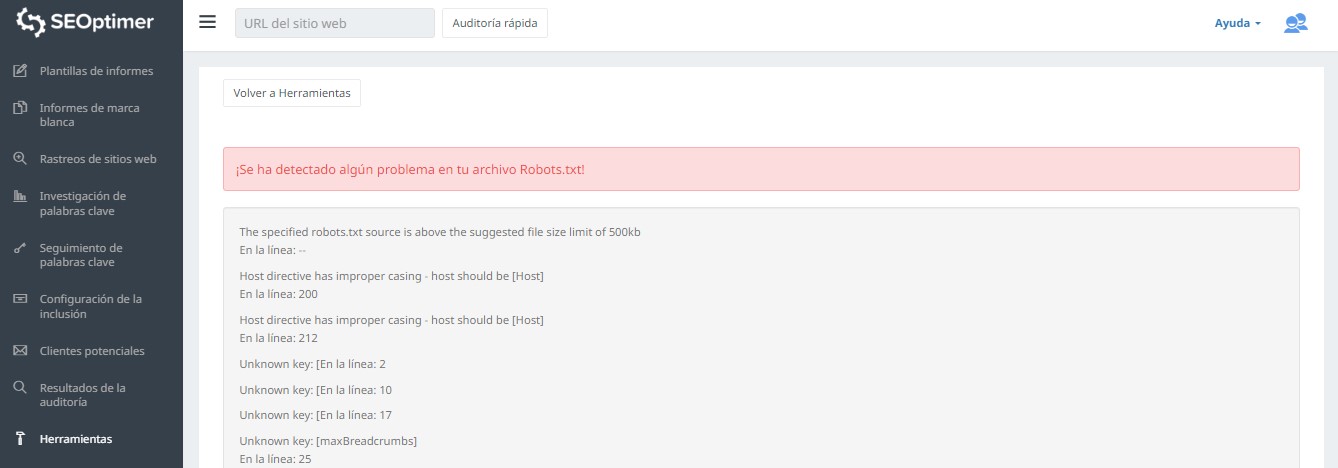
También puedes seguir este enlace GSC. A continuación, debes:
- Abrir la lista de los recursos bloqueados y elegir el dominio.
- Hacer clic en cada recurso. Deberías ver esta ventana emergente:
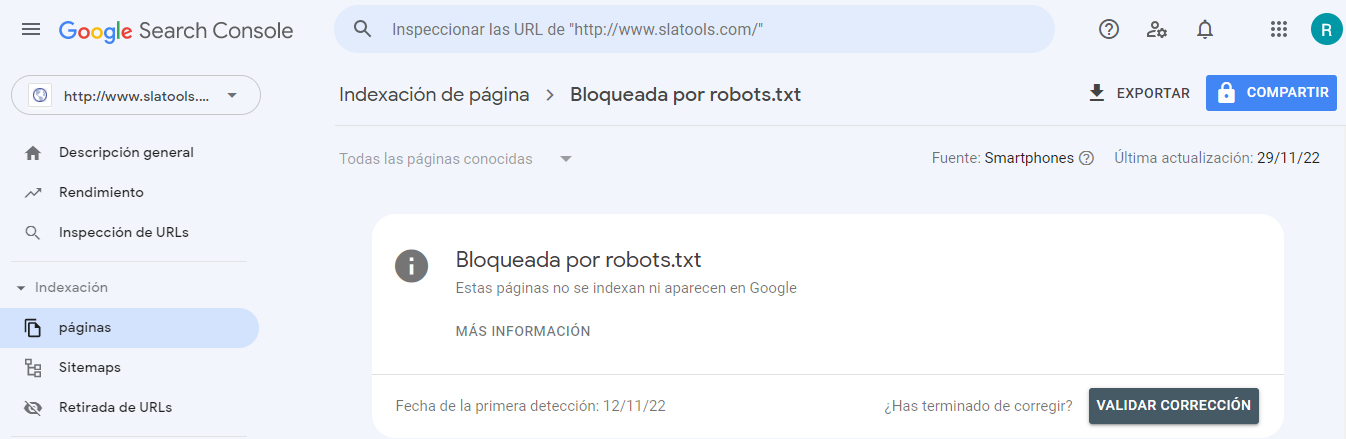
Identificar el motivo de la notificación
La notificación puede deberse a varias razones, siendo estas las más comunes:
Pero primero, no es necesariamente un problema si hay páginas bloqueadas por robots.txt. Se puede haber diseñado por diferentes razones, como que el desarrollador quiere bloquear páginas / categorías innecesarias o duplicados. Entonces, ¿cuáles son las incoherencias?
Formato de URL incorrecto
A veces, el problema puede aparecer por una URL que realmente no es una página. Por ejemplo, si la URL https://www.seoptimer.com/?s=digital+marketing, necesita saber en qué página se resuelve la URL.
Si se trata de una página que contiene contenido significativo que realmente necesitas que vean tus usuarios, entonces debes cambiar la URL. Esto es posible en sistemas de gestión de contenido (CMS) como WordPress, donde puedes editar el slug de una página.
Si la página no es importante, o siguiendo nuestro ejemplo /?s=digital+marketing, es una consulta de búsqueda de nuestro blog, entonces no es necesario corregir el error GSC.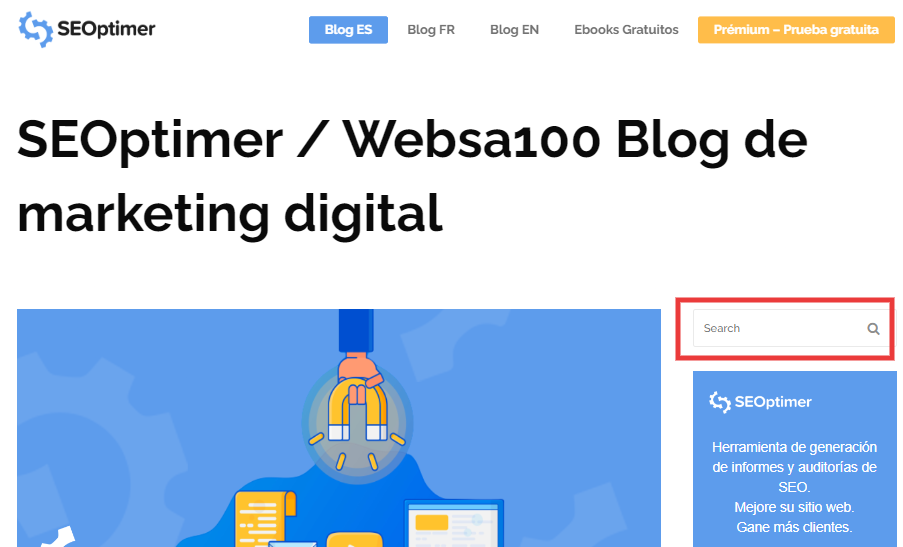
Da igual si está indexado o no, ya que ni siquiera es una URL real, sino una consulta de búsqueda. Otra opción consiste en eliminar la página.
Páginas que deben indexarse
Hay varias razones por las que las páginas que deberían indexarse no se indexan, como por ejemplo:
- ¿Has revisado tus instrucciones para robots? Es posible que hayas incluido instrucciones en tu archivo robots.txt que no permiten la indexación de páginas que realmente deberían indexarse, por ejemplo, etiquetas y categorías. Las etiquetas y categorías son URL reales en tu sitio.
- ¿Estás apuntando el bot de Google a una cadena de redireccionamiento? El bot de Google revisa todos los enlaces que puede encontrar y hace todo lo posible para leer la indexación. Sin embargo, si configuras una redirección múltiple, larga y detallada, o si simplemente la página es inaccesible, el bot de Google dejará de buscar.
- ¿Implementaste correctamente el enlace canónico? Se utiliza una etiqueta canónica en el encabezado HTML para indicar al bot de Google cuál es la página preferida y canónica en el caso de contenido duplicado. Cada página debe tener una etiqueta canónica. Por ejemplo, si tienes una página traducida al inglés, te ‘autocanonizarás’ la URL en inglés y querrás canonizar la página de nuevo a tu versión predeterminada en español.
¿Cómo verificar que tu robots.txt está bien en WordPress?
En WordPress, si el archivo robots.txt es parte de tu sitio, usa el Plugin Yoast para editarlo. Si el archivo robots.txt que está provocando problemas está en otro sitio que no es el tuyo, debes ponerte en contacto con los propietarios del sitio para pedirles que editen su archivo robots.txt.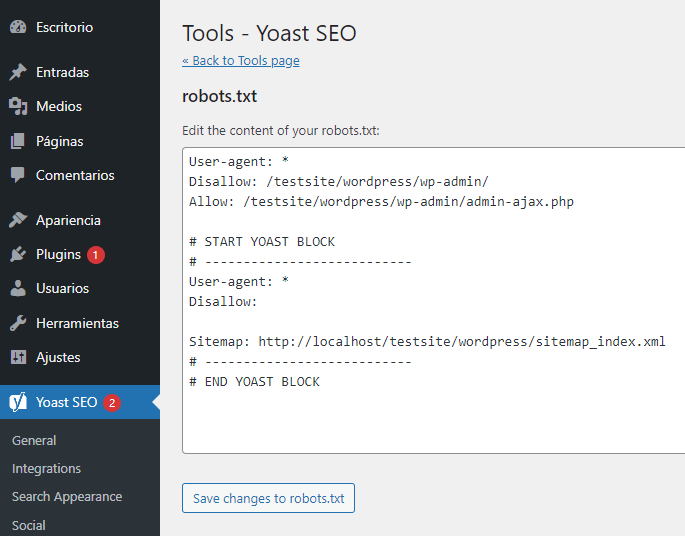
Páginas que no deben indexarse
Existen varias razones por las que las páginas no deben indexarse si se indexan, como por ejemplo:
Instrucciones robots.txt que ‘dicen’ que una página no debe ser indexada. Ten en cuenta que debes permitir que la página con una instrucción 'noindex' sea rastreada para que los robots del motor de búsqueda 'sepan' que no debe ser indexada.
En el archivo robots.txt, asegúrate de que:
- La línea ‘disallow’ no sigue inmediatamente a la línea ‘user-agent’.
- No hay más de un bloque ‘user-agent’.
- Caracteres Unicode invisibles: debes ejecutar tu archivo robots.txt usando un editor de texto que convierta las codificaciones. Esto eliminará cualquier carácter especial.
Las páginas están vinculadas desde otros sitios. Las páginas pueden indexarse si están vinculadas desde otros sitios, incluso si no están permitidas en robots.txt. En este caso, solo la URL y el texto de anclaje aparecen en los resultados del motor de búsqueda. Así es como se muestran estas URL en la página de los resultados del motor de búsqueda (SERP):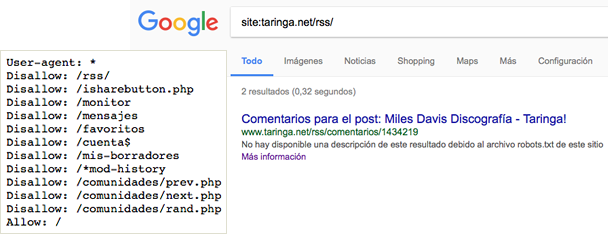
Una manera de resolver el problema del bloqueo robots.txt consiste en proteger con contraseña los archivos en tu servidor.
Otra opción consiste en eliminar las páginas de robots.txt o usar la siguiente metaetiqueta para bloquearlos:
<meta name="robots" content="noindex">
URL antiguas
Si has creado un contenido nuevo o un sitio nuevo y has utilizado una instrucción 'noindex' en robots.txt para asegurarte de que no se indexe, o hace poco que te has registrado en GSC, hay dos opciones para solucionar el problema del bloqueo de robots.txt:
- Dale tiempo a Google para que eventualmente elimine las URL antiguas de tu índice.
- 301 redirecciona las URL antiguas a las actuales.
En el primer caso, Google acaba eliminando las URL de tu índice si lo que hacen es provocar 404 (lo que significa que las páginas no existen). No es recomendable utilizar plugins para redirigir tus 404s. Los plugins podrían provocar problemas que pueden hacer que GSC te envíe la advertencia ‘bloqueado por robots.txt’.
Archivos virtuales robots.txt
Existe la posibilidad de recibir notificaciones, incluso si no tienes un archivo robots.txt. Esto se debe a que los sitios basados en CMS (Customer Management Systems), como por ejemplo WordPress, tienen archivos virtuales robots.txt. Los plugins también pueden contener archivos robots.txt. Estos podrían ser los que causan los problemas en tu sitio.
Estos archivos virtuales robots.txt deben ser sobrescritos por tu propio archivo robots.txt. Asegúrate de que tu robots.txt incluya una instrucción que permita que todos los robots de los motores de búsqueda rastreen tu sitio. Esta es la única manera en que pueden decirle a las URL que indexen o no.
Esta es la instrucción que permite a todos los bots rastrear tu sitio:
User-agent: *
Disallow: /
Significa ‘no permitir nada’.
Conclusión
Hemos analizado la advertencia ‘Se ha indexado aunque un archivo robots.txt la ha bloqueado’, lo que significa, cómo identificar las páginas o URL afectadas, así como la razón detrás de la advertencia. También hemos visto cómo solucionarlo. Ten en cuenta que la advertencia no equivale a un error en tu sitio. Sin embargo, no solucionarlo puede hacer que tus páginas más importantes no se indexen, lo que no es bueno para la experiencia de los usuarios.