El SEO Crawler de SEOptimer te ayuda a escanear y auditar las páginas de tu sitio web para identificar problemas técnicos de SEO a gran escala.
En lugar de revisar las páginas una por una, el rastreador revisa la estructura de su sitio, analiza elementos de SEO a través de múltiples URLs y destaca problemas que pueden afectar el [indexado], la usabilidad o la visibilidad en búsquedas.
En esta guía, usted:
- Ejecuta tu primer "crawl"
- Revisa el informe de "crawl"
- Aprende cómo configurar reglas personalizadas de "crawl"
- Programa y exporta los "crawls" del sitio web
¿Qué es el rastreador SEO de SEOptimer?
El SEO Crawler de SEOptimer es una herramienta de rastreo de sitios web que escanea las páginas de tu sitio e identifica problemas relacionados con el SEO en múltiples URLs.
Funciona visitando páginas en tu sitio web y recopilando datos técnicos y de SEO en la página, como títulos de página, descripciones meta, encabezados, códigos de estado, indexabilidad, redireccionamientos y enlaces rotos.
Después de que se complete el rastreo, la herramienta genera un informe de rastreo que resume los "problemas" encontrados en tu sitio y los agrupa por tipo y "gravedad".
Esto hace que sea más fácil detectar problemas recurrentes y priorizar las soluciones, especialmente en sitios web más grandes donde las comprobaciones manuales de páginas no son prácticas.
El "SEO Crawler" es útil para realizar auditorías técnicas de SEO, monitorear la salud del sitio a lo largo del tiempo y verificar si las páginas clave siguen las mejores prácticas de SEO.
Cómo ejecutar tu primer "Crawl"
Para ejecutar su primer rastreo, haga clic en la opción “Website Crawls” bajo “Auditing” en su panel de control de SEOptimer.
Luego, añade la URL de tu sitio web en el campo abierto y haz clic en “Añadir Rastreo.”
¡Eso es, has comenzado el rastreo de tu primer sitio SEOptimer!
Nuestro "SEO Crawler" ahora revisará todas las páginas de su sitio para detectar cualquier problema que puedan tener.
Los "crawls" se ejecutan en tiempo real, pero el tiempo total de rastreo variará dependiendo del tamaño de su sitio web y del número de páginas que necesitan ser escaneadas.
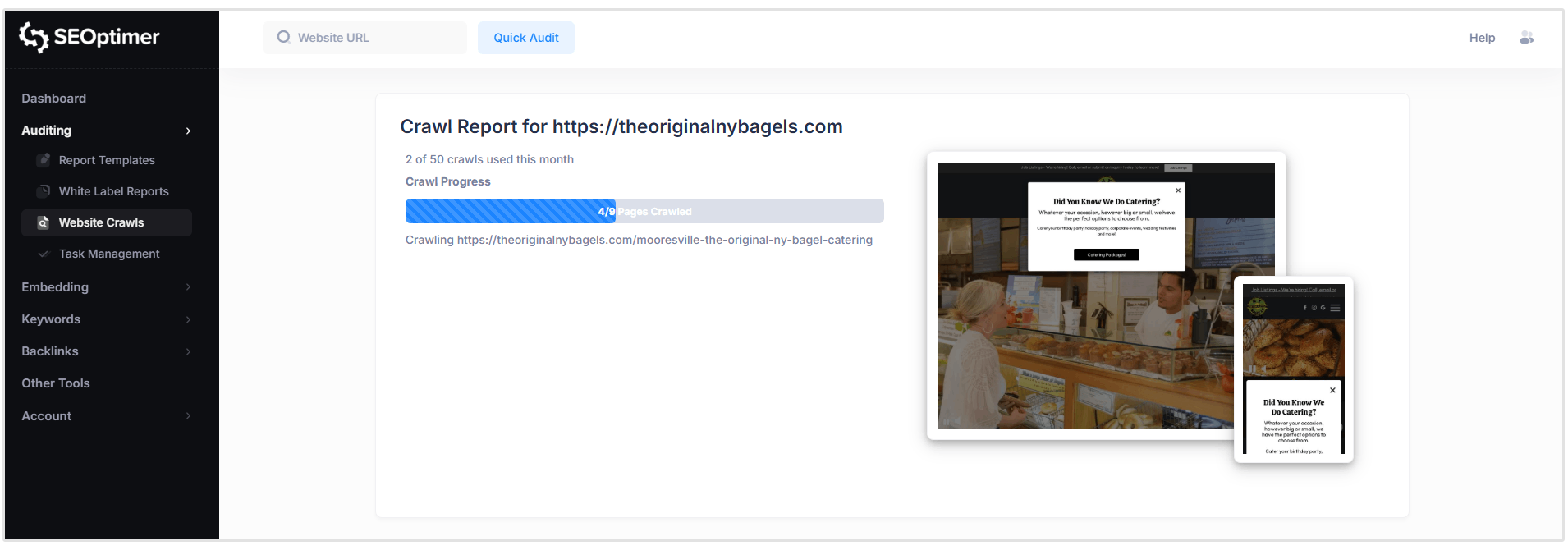
Mientras el "crawl" aún se está ejecutando, puedes comenzar a revisar los problemas a medida que se detectan abriendo el informe del "crawl".
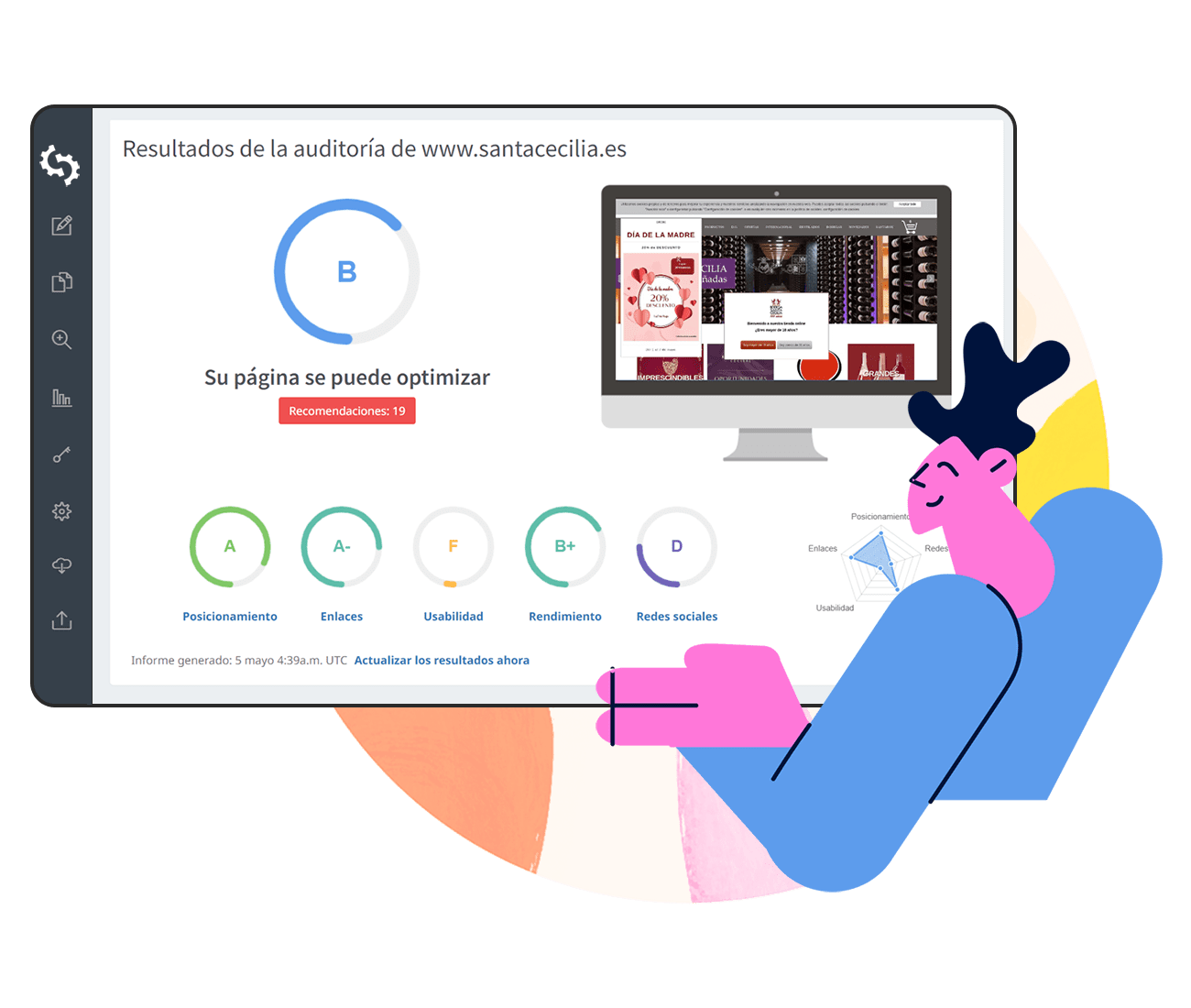
¿Qué puedes "ver" en cada [informe] de rastreo?
Una vez que nuestra herramienta haya terminado de rastrear tu sitio, verás tres secciones principales:
- Encabezado del informe
- Páginas identificadas
- Resumen de problemas
Vamos a recorrer cada una de estas secciones.
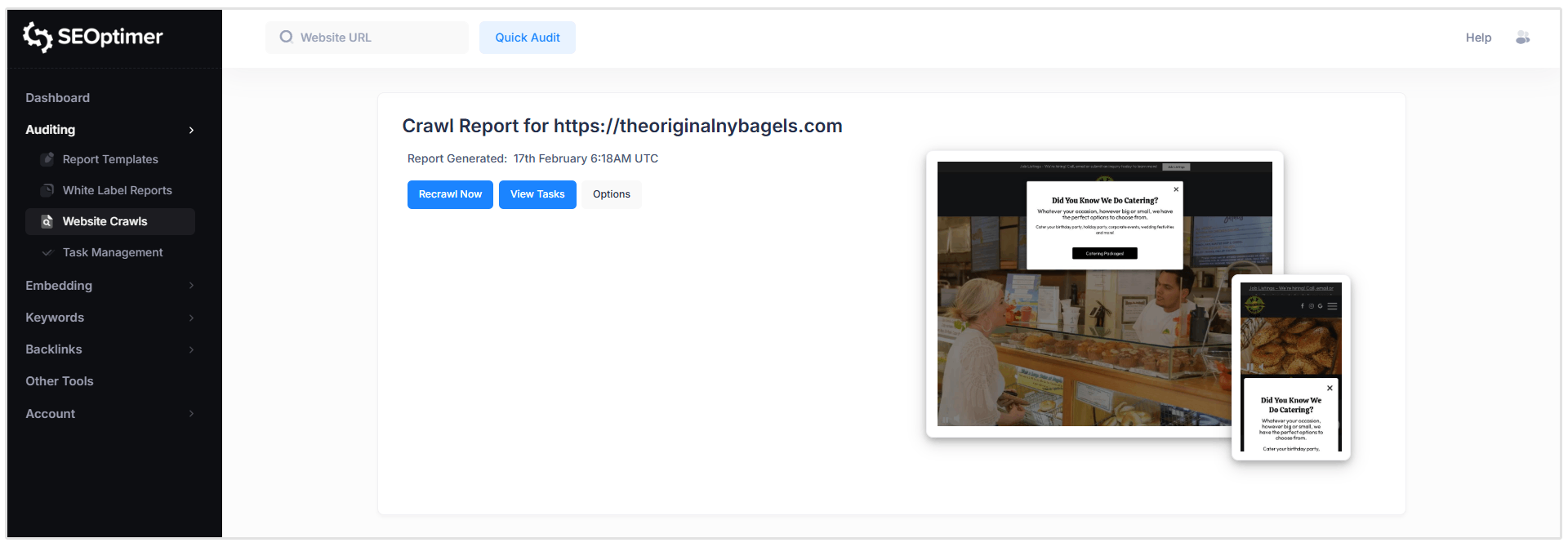
Encabezado del [informe]
Aquí puedes ver cuándo se generó el informe, solicitar un nuevo rastreo, ver tareas y personalizar las reglas de rastreo. (más sobre estas características más adelante)
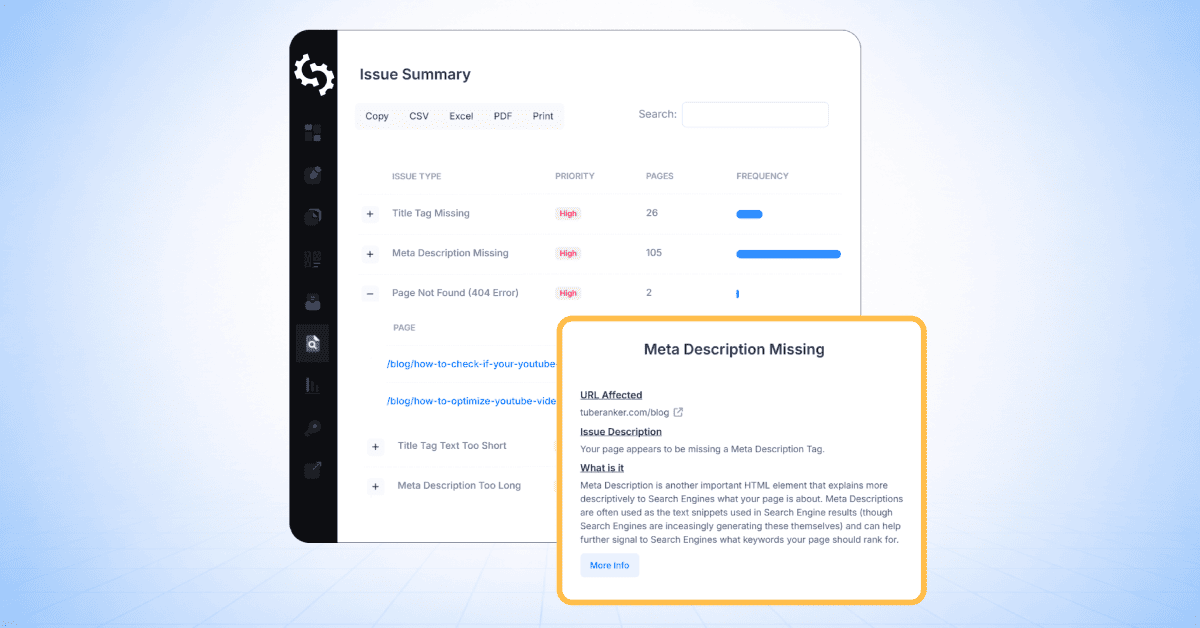
Páginas Identificadas
Esta sección muestra una tabla de todas las páginas descubiertas durante el rastreo, junto con los problemas de SEO detectados para cada página.
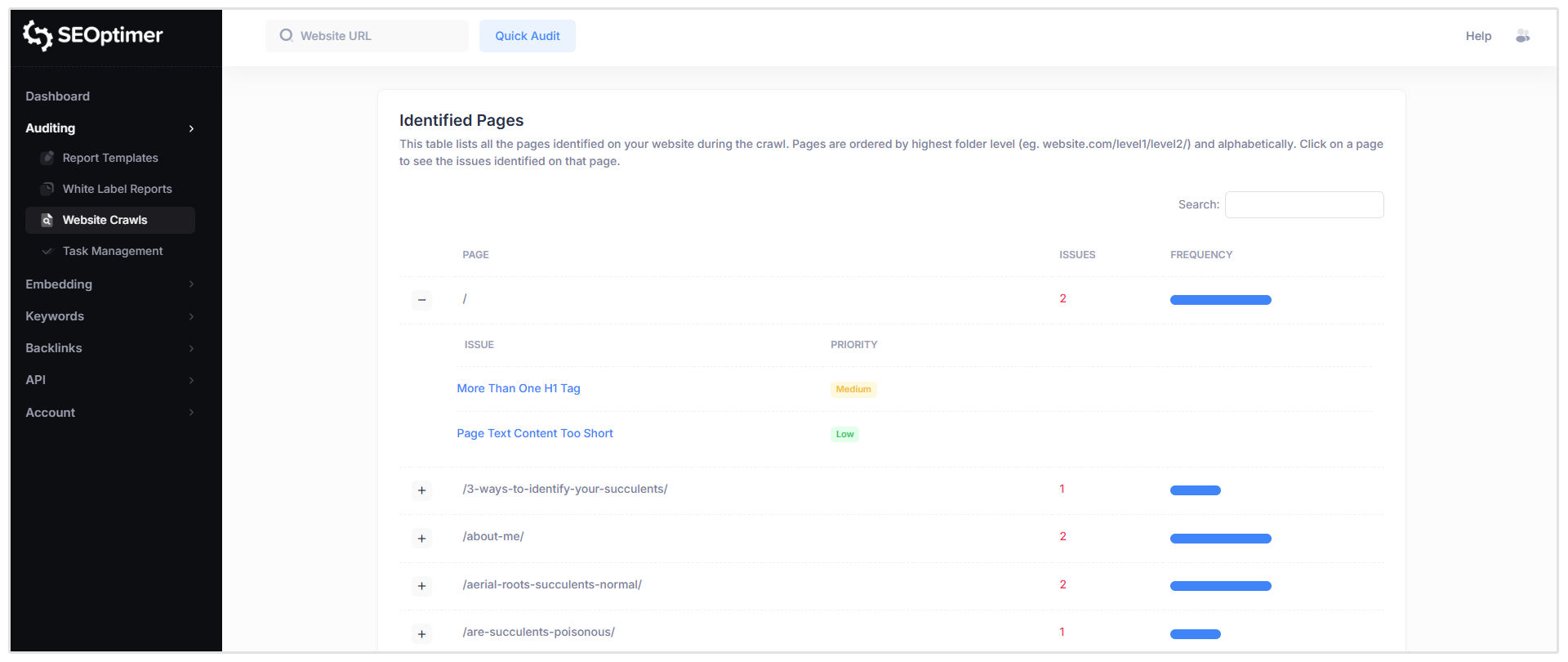
Cuando haces clic en una página específica (por ejemplo, la ruta de la página principal raíz mostrada como “/”), verás una lista de todos los problemas marcados para esa URL, incluyendo el nivel de gravedad de cada problema.
Para ver más detalles, haz clic en cualquier "issue" de la lista.
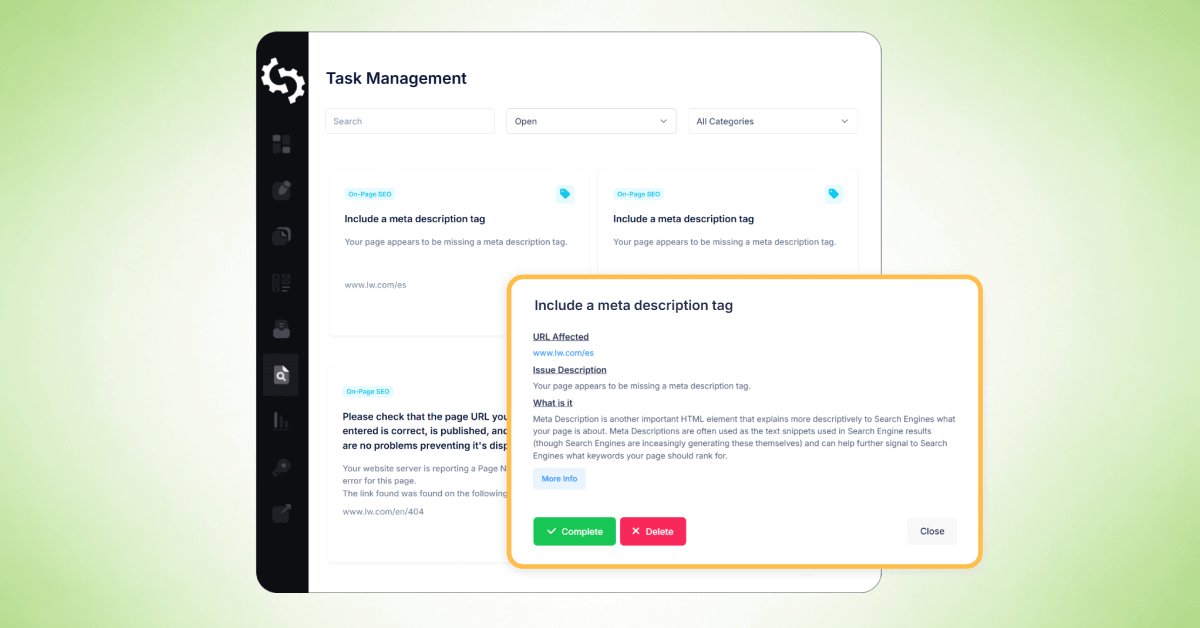
Por ejemplo, seleccionar “Más de una etiqueta H1” abrirá un desglose detallado de ese [problema] para la [página] seleccionada.
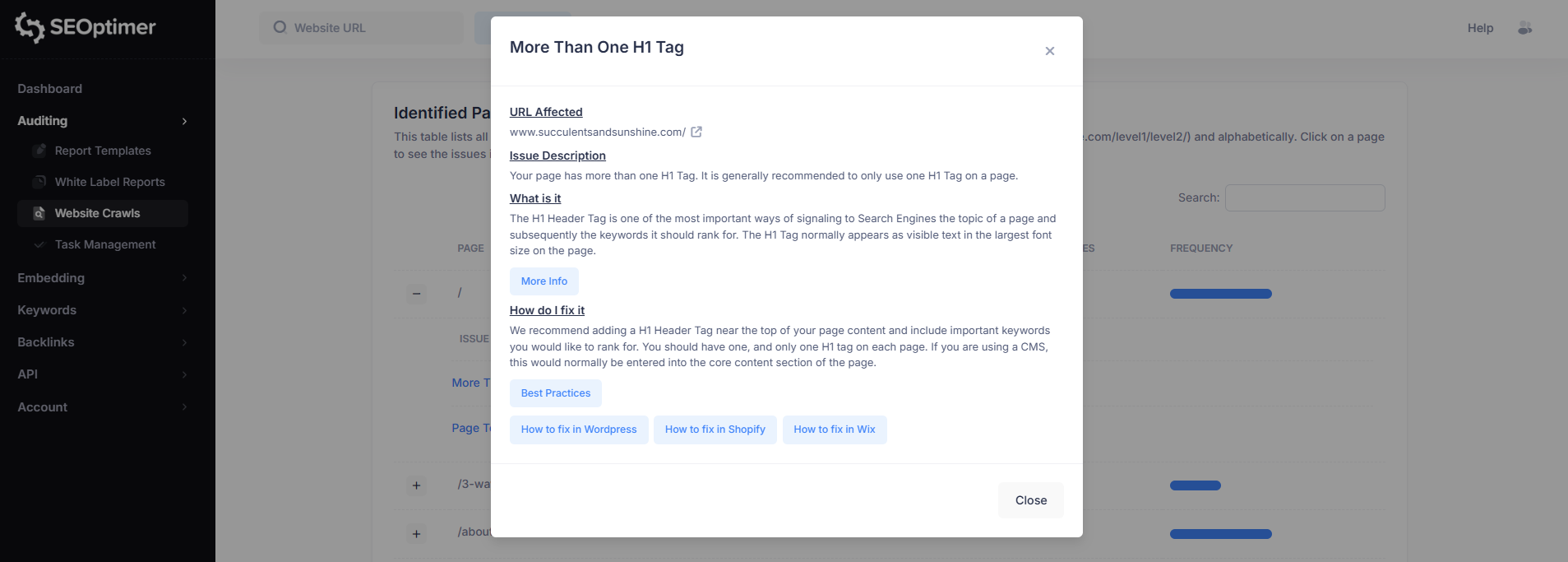
Esta vista de [problema] incluye:
- URL afectada
- Descripción del problema
- Qué significa el problema
- Cómo solucionarlo
Cada "pop-up" de problema también incluirá enlaces a guías de apoyo para ayudarte a resolver el problema en tu sitio web.
Resumen del problema
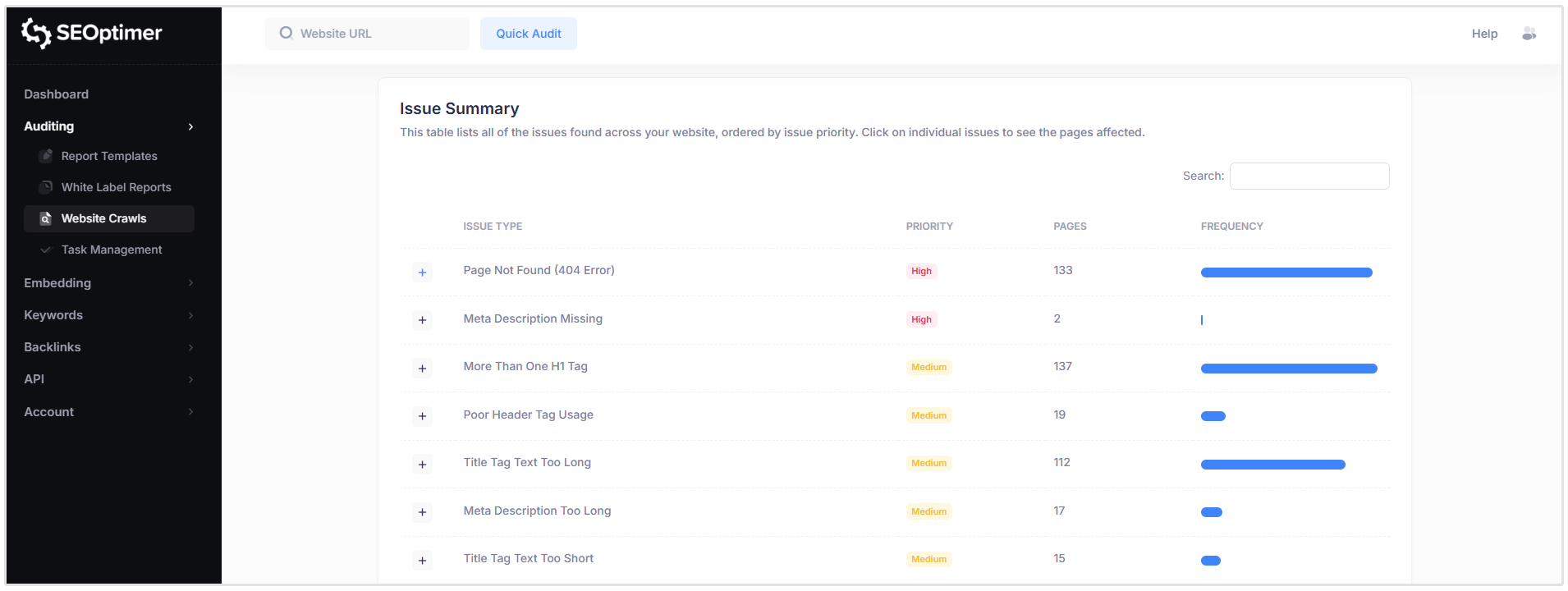
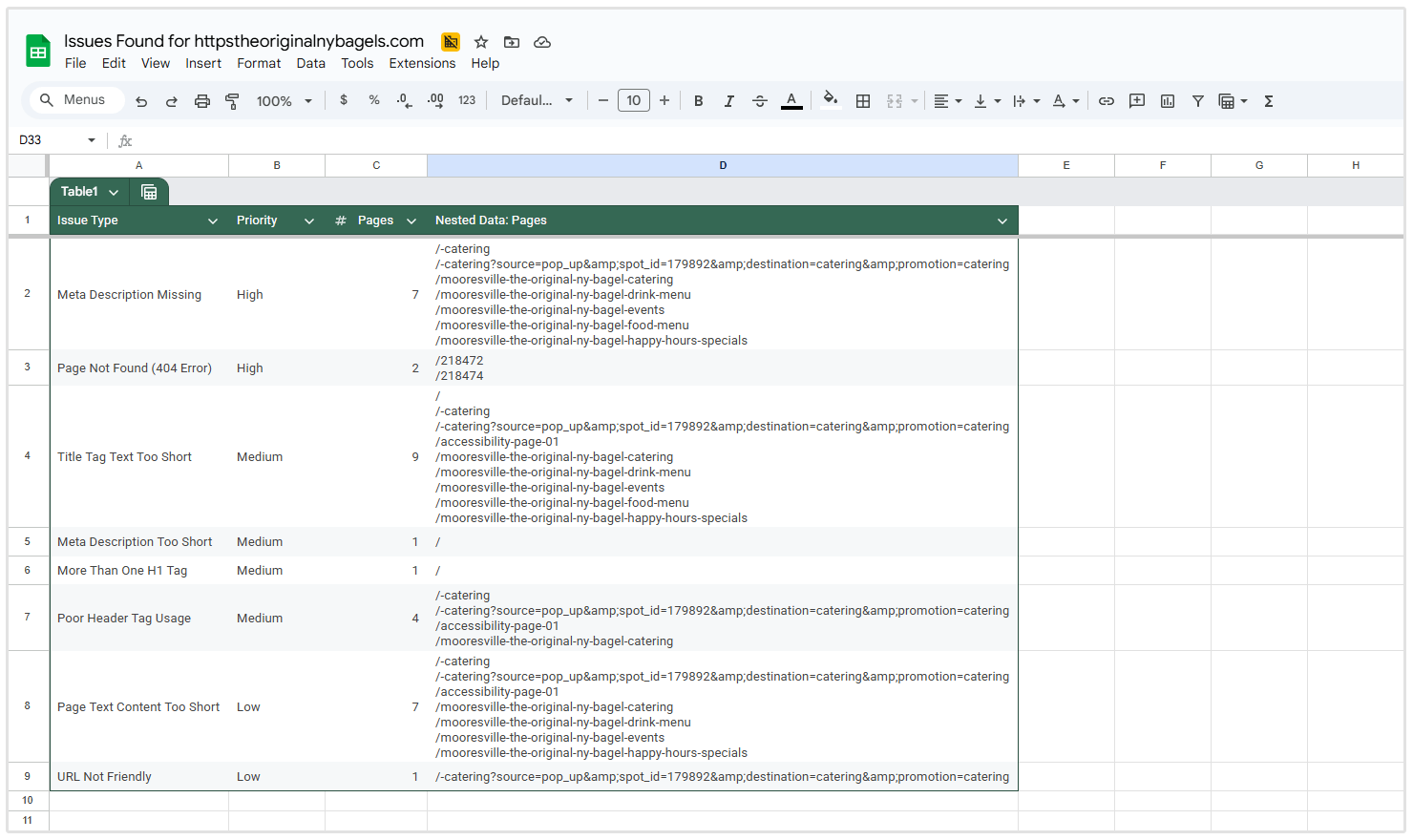
La sección de Resumen de Problemas proporciona una visión general de todos los problemas de SEO detectados en su sitio web, agrupados por tipo de problema y ordenados por prioridad.
Para cada "issue", la tabla muestra:
- Tipo de "issue"
- Nivel de prioridad
- Número de páginas afectadas
Así que en la captura de pantalla a continuación de un sitio que rastreé, puedes ver que hay 137 páginas que tienen más de una etiqueta H1, 133 páginas que tienen errores 404 y 2 páginas que no tienen una meta descripción.
Una vez que hayas revisado el resumen del problema, puedes pasar a configurar los ajustes de rastreo y explorar opciones adicionales del SEO Crawler.
Ver [Tareas]
Después de completar un "website crawl", puedes utilizar la función de Gestión de Tareas de SEOptimer para organizar y realizar un seguimiento de los problemas identificados en tu informe de rastreo.
La herramienta de [gestión de tareas] convierte los problemas de rastreo en una [lista de tareas] que puedes trabajar en un solo espacio de trabajo, facilitando la priorización de soluciones y el seguimiento del progreso a lo largo del tiempo.
Cómo Acceder a la Lista de Tareas
Puede abrir su lista de tareas de dos maneras:
- Haz clic en el botón azul “Ver Tareas” en el encabezado del Informe de Rastreo.
- O selecciona Gestión de Tareas desde el menú de navegación a la izquierda en tu panel de control.
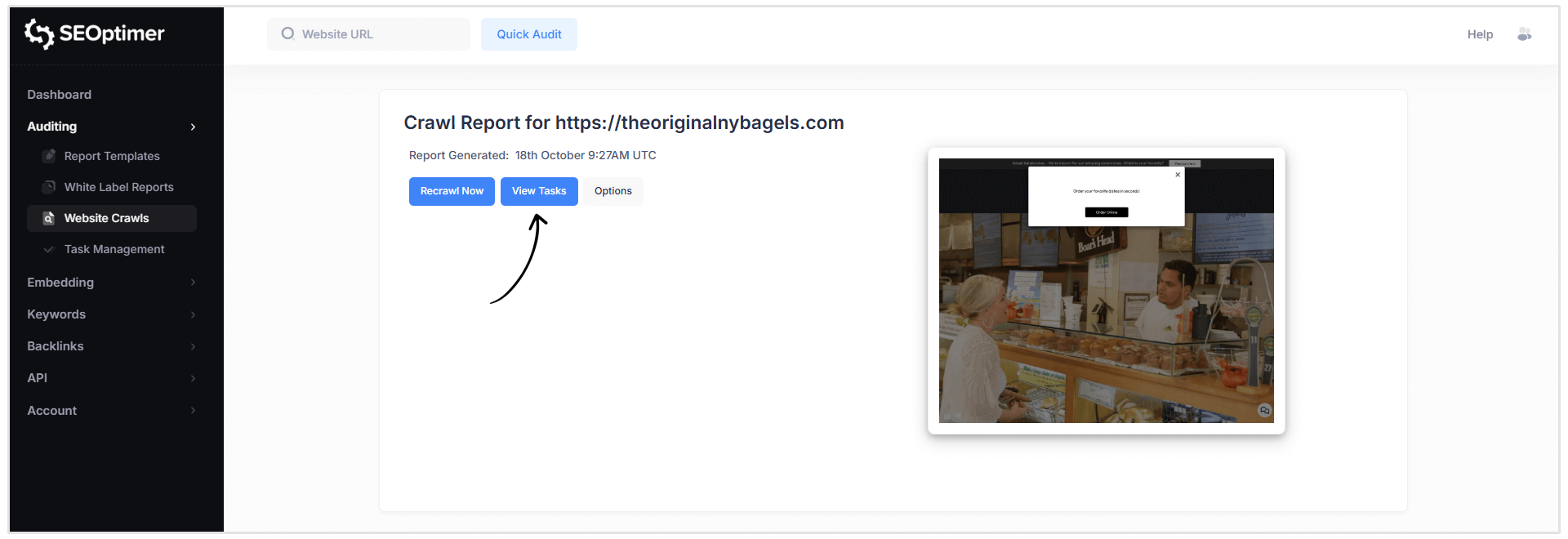
Nota: Si has rastreado varios sitios web, puedes cambiar entre las listas de tareas usando el menú desplegable en la parte superior de la página de [Gestión] de Tareas.
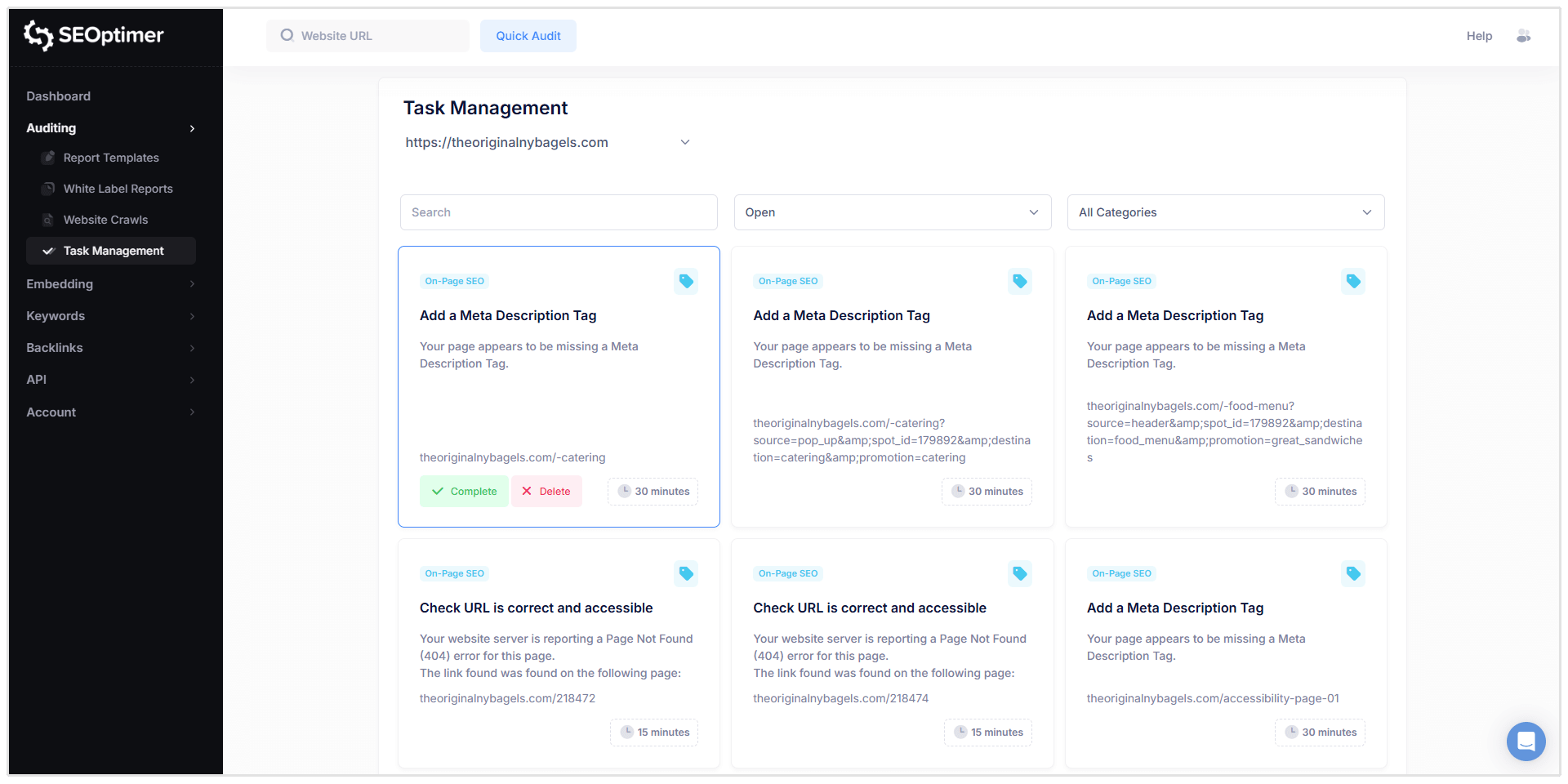
Filtrando y Gestionando Tareas
Las "tareas" pueden ser filtradas por:
- Estado (Abierto, Completado, Eliminado)
- Categoría (p. ej. SEO en Página, Enlaces, etc.)
Cuando haces clic en una tarea, verás información detallada similar al informe de rastreo, incluyendo:
- URL afectada
- Descripción del problema
- Qué significa el problema
- Cómo solucionarlo
- Opciones para completar la tarea o eliminarla de la lista de tareas
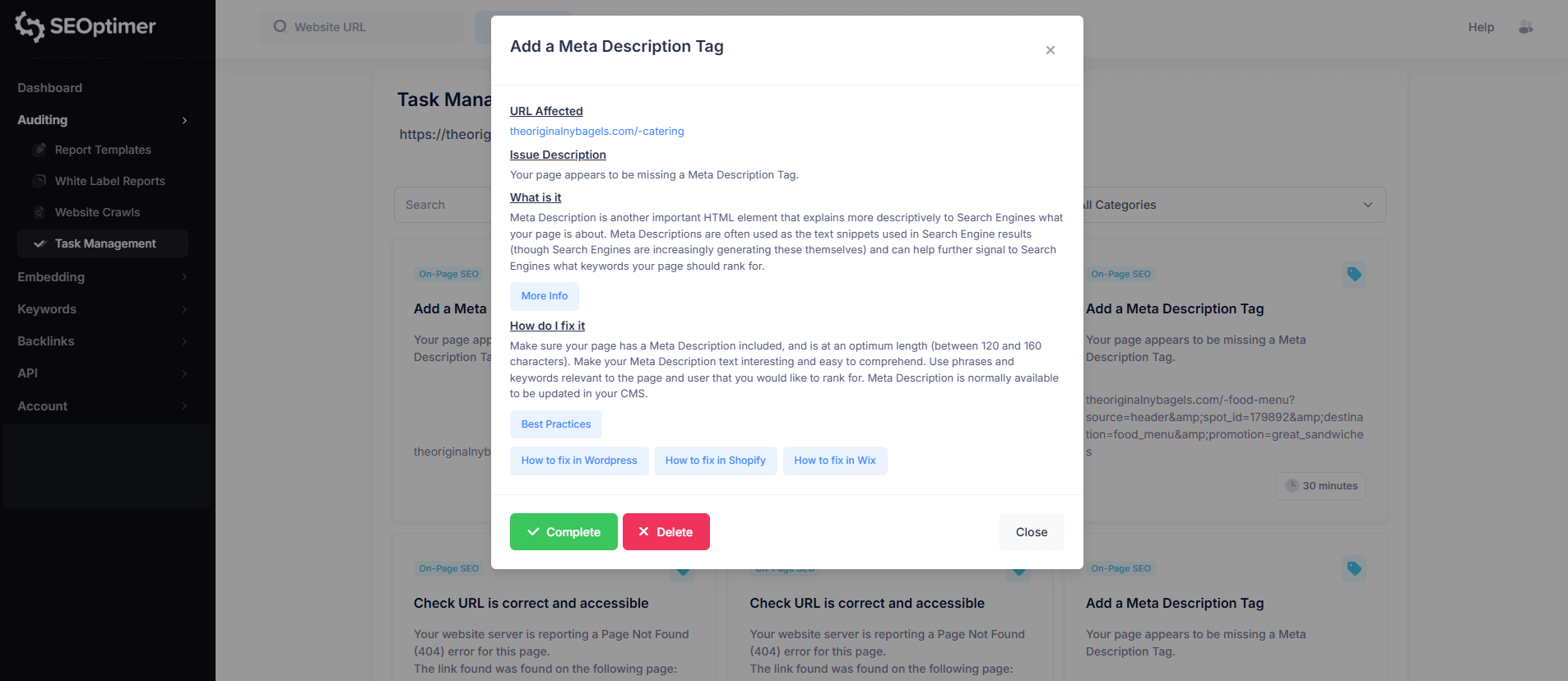
Cómo Programar "Crawls"
También tienes la opción de programar rastreos para que se ejecuten de manera "semanal" o "mensual". Esta función es especialmente útil para agencias que gestionan múltiples sitios web de clientes.
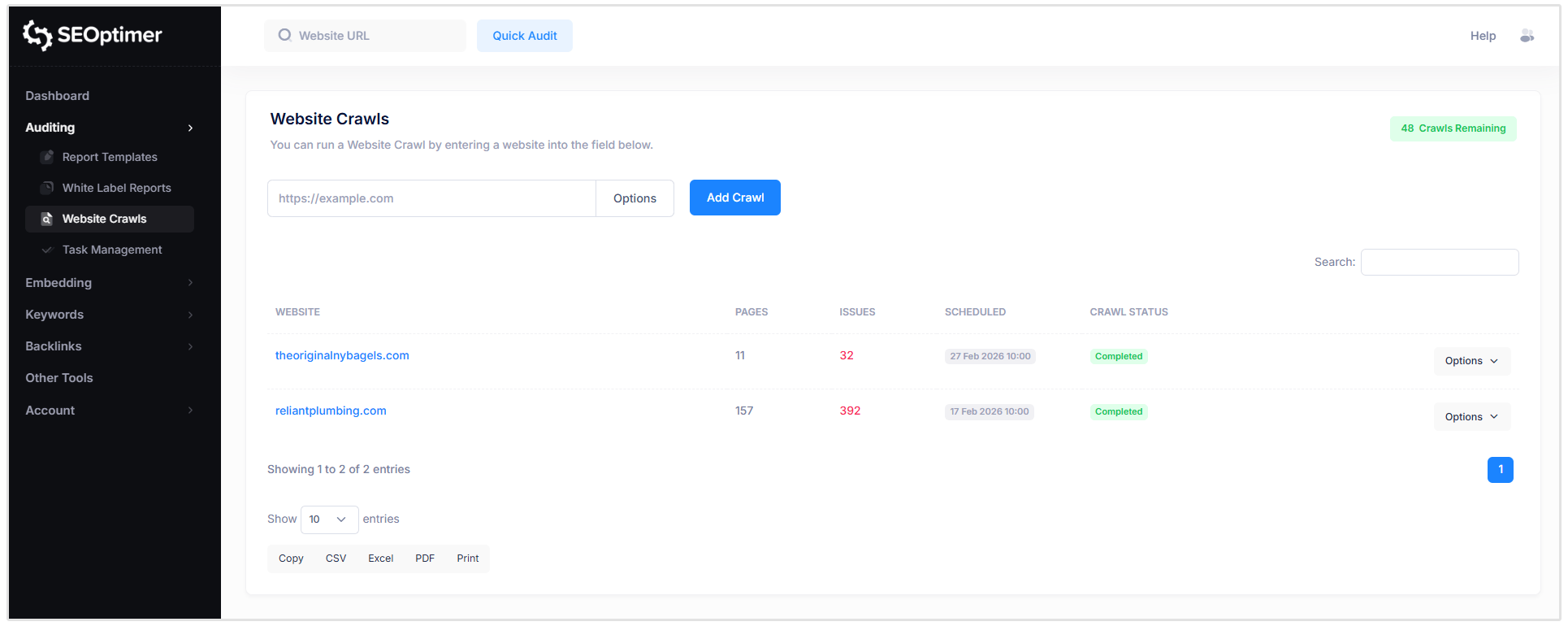
Para configurar un horario de rastreo, simplemente haz clic en el botón “Opciones” a la derecha del sitio web para el que deseas programar un rastreo.
Luego, haz clic en la opción “Programar” y personaliza el [programa] de rastreo según tu preferencia.
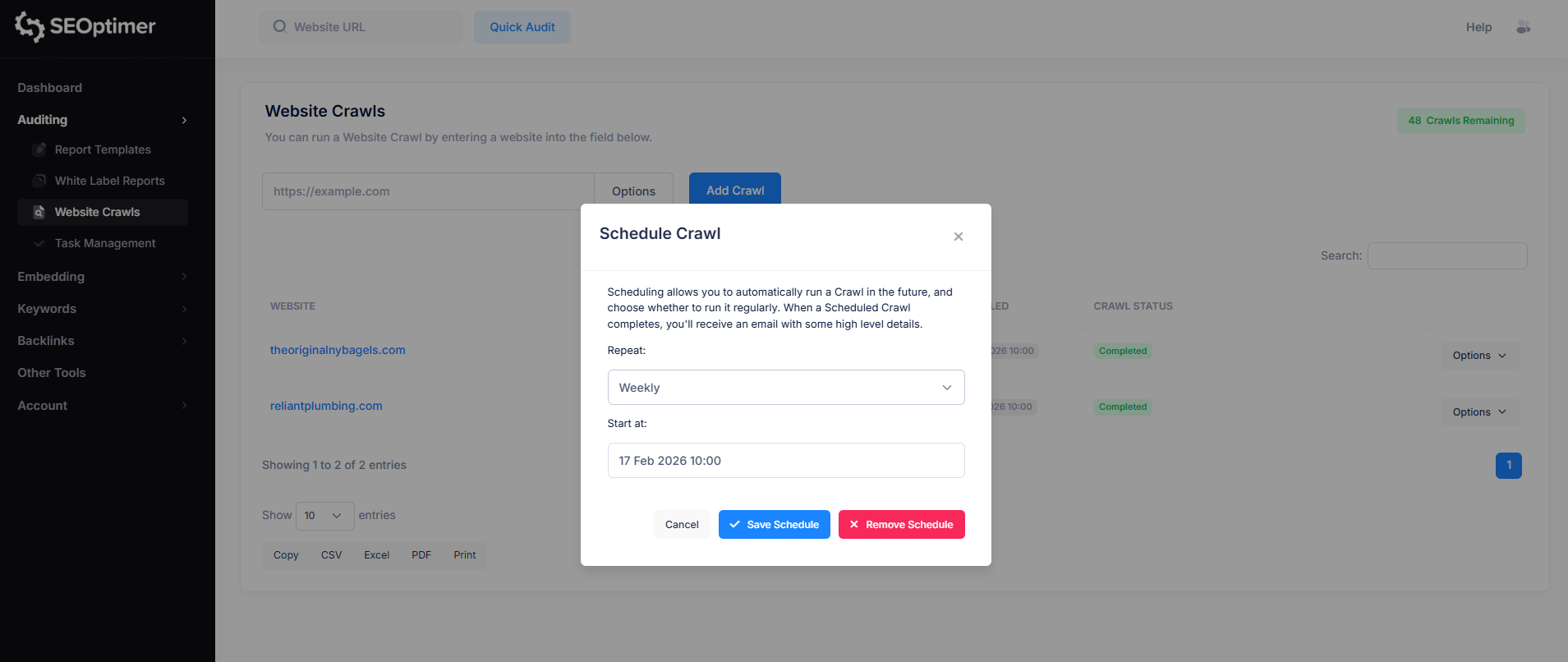
Cuando se complete un rastreo programado, recibirás un correo electrónico con algunos detalles [importantes].
Estableciendo tus propias "Crawl Rules"
El "SEO Crawler" incluye opciones de configuración de rastreo que te permiten controlar qué páginas se incluyen en un rastreo.
Estas "configuraciones" son útiles si deseas limitar [resultados], evitar URLs duplicadas, o asegurar que el rastreador se comporte de acuerdo con las reglas de indexación de tu sitio.
Obedecer las exclusiones de Robots.txt
De forma predeterminada, el "crawler" puede seguir las reglas definidas en el archivo robots.txt de su sitio. Esto determina si el "crawler" debe evitar escanear páginas que están marcadas como no permitidas.
- Habilitado (recomendado): El rastreador respetará las exclusiones de robots.txt y omitirá las páginas bloqueadas.
- Deshabilitado: El rastreador ignorará las reglas de robots.txt e intentará rastrear todas las páginas a las que pueda acceder.
En la mayoría de los casos, se recomienda obedecer robots.txt, especialmente cuando se realizan rastreos en sitios de producción en vivo.
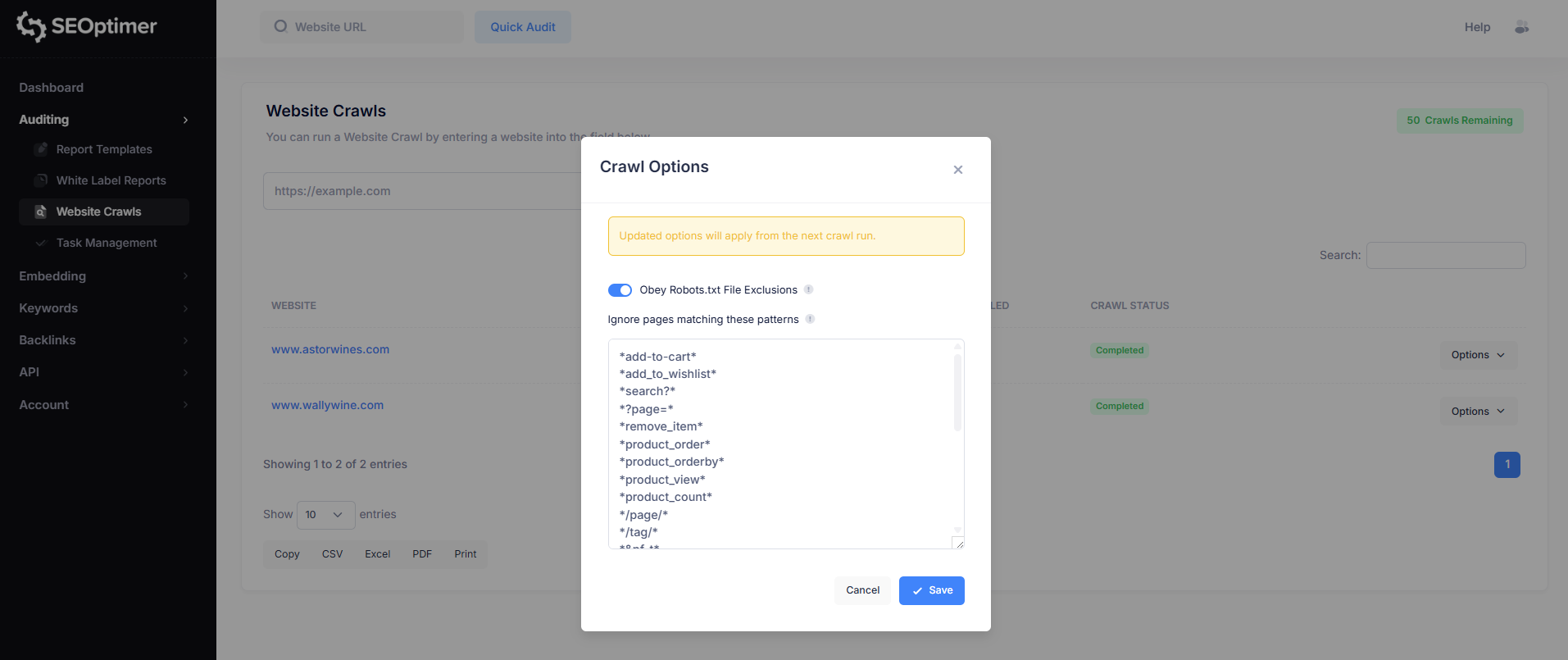
Ignorar las páginas que coincidan con estos patrones
Algunos sitios web generan múltiples versiones de la misma página utilizando parámetros de URL (por ejemplo, "ordenación", "filtrado", "paginación" o "códigos de seguimiento").
Esto es especialmente común en sitios web de comercio electrónico.
La opción “Ignorar páginas que coincidan con estos patrones” te permite excluir estas URLs duplicadas o de bajo valor de ser rastreadas. Esto ayuda a mantener los resultados de rastreo más limpios y facilita la revisión de los informes de problemas.
Esta es una función más avanzada y es principalmente útil para sitios web con un gran número de URLs basadas en parámetros.
SEOptimer incluye un conjunto predeterminado de patrones de exclusión para filtrar los "duplicados" comunes basados en parámetros, pero puedes agregar tus propias reglas si es necesario.
Estos patrones siguen la sintaxis estándar de coincidencia de robots.txt.
Si no estás familiarizado con las reglas de robots.txt o el [patrón] de coincidencia de URL, se recomienda revisar los [conceptos básicos] antes de agregar exclusiones personalizadas de rastreo. Los [patrones] incorrectos pueden impedir que se rastreen páginas importantes.
Aquí tienes algunas referencias útiles:
- Robots.txt - La "Guía" Definitiva
- Introducción y Guía de Robots.txt | Google Search Central
- Cómo Google interpreta la especificación de robots.txt
- Sintaxis de Robots.txt
Cómo exportar "datos" de rastreo
Cada tabla en el informe del SEO Crawler incluye opciones de exportación integradas, lo que le permite descargar o compartir los resultados del rastreo fuera de la plataforma.

En la parte inferior de cada tabla, verás botones de exportación que te permiten sacar los datos en diferentes formatos:
- CSV: Descarga la tabla como un archivo .csv (útil para hojas de cálculo y procesamiento de datos).
- Excel: Exporta la tabla como un archivo de Excel para "reporting" o análisis adicional.
- PDF: Genera una versión en PDF de la tabla para compartir o documentación.
- Print: Abre una versión de la tabla "print-friendly".
Las "exportaciones" se aplican a la tabla específica que estás viendo, lo que facilita descargar "listas de problemas", "informes de páginas" o "resultados filtrados" según sea necesario.
Conclusión
El SEO Crawler de SEOptimer hace que sea fácil identificar problemas técnicos y de SEO en la página en todo tu sitio web en un solo rastreo.
Al revisar el informe de rastreo y utilizar la lista de tareas incorporada, puedes convertir rápidamente los hallazgos del rastreo en mejoras [accionables].
Para obtener [mejores] resultados, considere programar rastreos regulares para [monitorizar] cambios a lo largo del tiempo y detectar nuevos problemas a medida que su sitio web crece.
¿Necesitas ayuda?
Chat en Vivo: Haz clic en Chat en Vivo (abajo a la derecha)
"Email": [email protected]
Tiempo de respuesta: Dentro de 24 horas