Sie wissen, wenn Sie Google verwenden, um nach einem [Dienst] zu suchen oder Informationen zu finden? Und sobald die Seite geladen ist, gibt es immer eine [Website] ganz oben.
Websites auf Position 1 in der Google-Suchergebnisseite (SERP) erhalten den Großteil aller Klicks. Es versteht sich also von selbst, dass es wichtig ist, den "SEO-Best-Practices" zu folgen, um zu versuchen, die Position Ihrer Website in der SERP zu maximieren.
Aber wissen Sie, wie Google Ihre Website überhaupt [findet]?
Die Antwort lautet Google’s Crawler. Google’s Crawler sind wie kleine digitale Roboter, die Websites besuchen und Informationen über diese Seiten sammeln.
![Google-Spinne [crawlt] eine Website](/storage/images/2025/06/7019-Google spider crawling website.png)
Dann indexiert Google all diese Informationen und nutzt sie, um seinen Suchalgorithmus zu verbessern. Wenn jemand eine Anfrage in Google eingibt, durchsucht der Suchalgorithmus alle indexierten Informationen, um die besten Ergebnisse für die [Anfrage] der Person zu finden.
Und so ist Google in der Lage, Ihnen die besten Ergebnisse zu liefern, wenn Sie im Internet nach etwas suchen!
Was ist ein Google Crawler?
Ein Google Crawler ist auch als “Roboter” oder “Spider” bekannt (verstehen Sie, weil sie kriechen) und sie gehen von Website zu Website auf der Suche nach neuen Informationen, um diese in ihren Datenbanken zu speichern. Es gibt 15 Arten von Crawlern, die von Google verwendet werden, aber der wichtigste ist Googlebot.

Obwohl Google mächtig ist, kann es nicht alles tun, jedes Mal, wenn eine neue Webseite erstellt wird, weiß Google nichts davon, bis diese Seite gecrawlt wurde.
Google verwendet den Googlebot, um ständig die neuesten Informationen zu gewinnen und in seiner Datenbank zu speichern.
Google Indexierung vs Google Crawling
Die "Indexierung" erfolgt erst, nachdem die Website von GoogleBot gecrawlt wurde. Wenn sie gecrawlt wird, wird sie gescannt, und die von dieser Seite oder Webseite gescannten Informationen werden im Google-Index gespeichert.
Der Index wird die Seiten entsprechend in den Suchergebnissen kategorisieren und bewerten.
Warum sind Google-Crawler wichtig?
Warum ist das alles wichtig?
Nun, nehmen wir an, Sie führen ein Unternehmen und haben eine Website. Sie möchten, dass Ihre Website so nah wie möglich an der Spitze ist. Wenn Ihre Website nicht gecrawlt und gescannt wird, wird sie nicht auf der Suchseite geladen.
Ohne jegliche Internetpräsenz werden Sie Ihre "Zielgruppe" oder "Konsumenten" nicht erreichen können. "Crawling" und "Indexierung" machen es etwas einfacher für Websites, etwas Aufmerksamkeit zu erlangen.
Wie ein Google-Crawler funktioniert
Also, Sie wissen, was es ist, aber wie funktioniert es? Während Google mächtig ist, kann es nicht alles tun. Jedes Mal, wenn eine neue Webseite erstellt wird, weiß Google nichts darüber, bis diese Seite "gecrawlt" wurde. Google verwendet den Googlebot, um ständig zusätzliche Informationen zu sammeln und in seiner Datenbank zu speichern.
Sobald diese Webseite gecrawlt oder gescannt wird. Die Seite wird gerendert und erhält einen HTML-, CSS-, JavaScript- und Drittanbieter-Code, die alle benötigt werden, damit der Googlebot Websites [indizieren] und [ranken] kann. Googlebot, der größte Crawler, ist in der Lage, alle Webseiten und Websites mit Chromium zu sehen und zu rendern.
Der Chromium wird ständig aktualisiert, damit er stabil bleibt und seine Aufgabe genau ausführt. Dies ist für jeden verfügbar und kann auch zum Testen neuer "Funktionen" und zum Erstellen neuer "Browser" verwendet werden.
Wie Sie Ihre Website [einfacher] crawlen lassen können
Jetzt, da wir wissen, womit wir es zu tun haben, lassen Sie uns daran arbeiten, Ihre Website [leicht] durchsuchbar zu machen.
Hier sind einige Tipps und Tricks, um Ihre Website zu einem Crawler-Magneten zu machen und an die Spitze der Suchergebnisseite zu gelangen.
Interne Links
Interne Links können Ihr bester Freund für das Crawling sein. Ihre Seite wurde möglicherweise bereits in der Vergangenheit von Google gecrawlt, aber kürzlich haben Sie möglicherweise weitere Seiten hinzugefügt. Wenn der Crawler Ihre Website bereits kennt, wird er sich nur auf die Hauptseiten konzentrieren.
Denken Sie daran, dass Google nicht jedes Mal benachrichtigt wird, wenn eine neue Seite erstellt wird, es durchsucht das Internet, um diese Seiten zu finden.
Die Verwendung von internen Links auf Hauptseiten [führt] den Crawler dorthin, wo er hin muss. Der beste Ort für diese internen Links ist Ihre Homepage, es ist die Seite, die den meisten Verkehr erhält und die der Crawler zuerst [scannen] wird.
Backlinks
Backlinks sind eine weitere großartige Möglichkeit, um Ihre Seite durchsuchen zu lassen. Diese Methode kann verwendet werden, um Ihre Website dem Crawler zu “promoten”.
Das Verlinken auf eine populärere Website wird Ihre Chancen erhöhen, vom Crawler entdeckt zu werden.
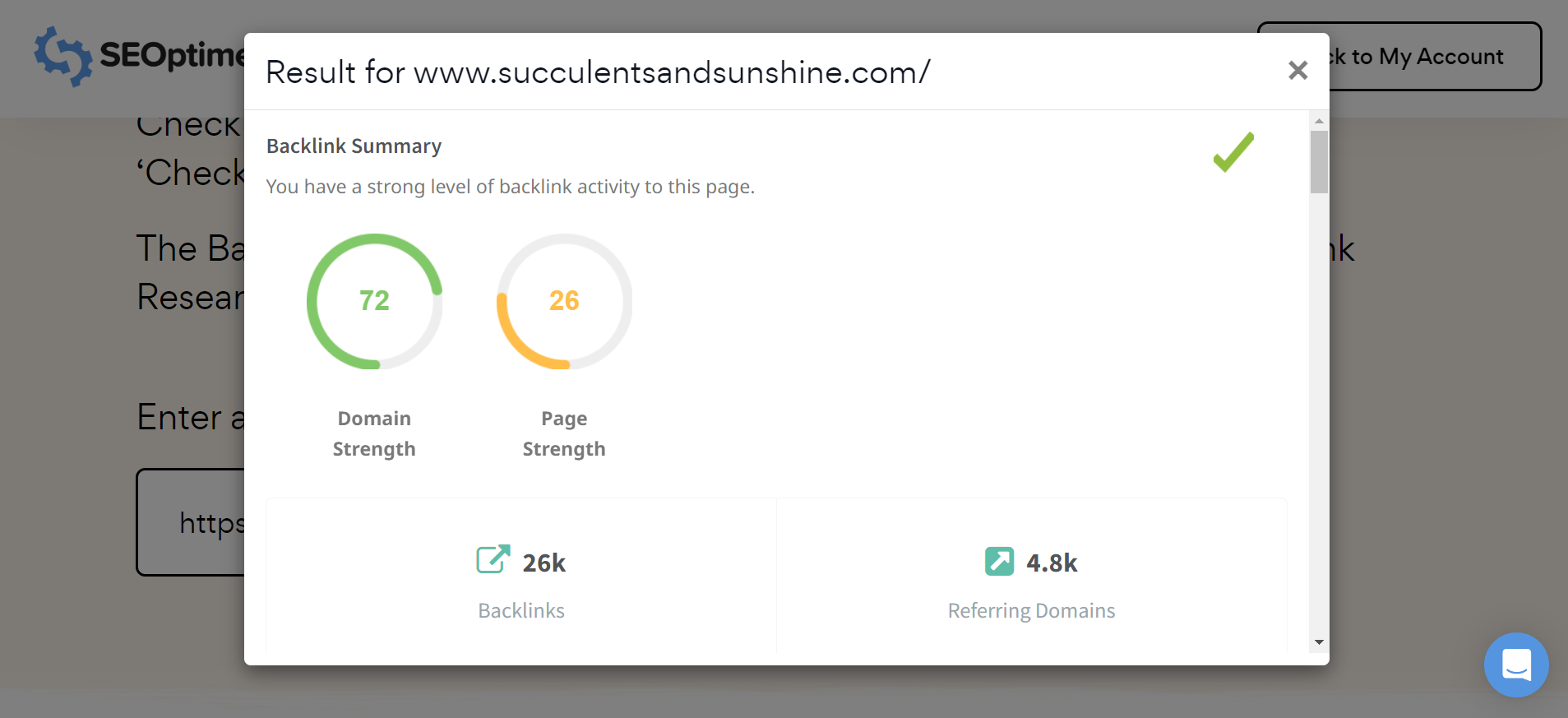
Hinweis: Sie können das Backlink-Profil jeder Website, einschließlich Ihrer Wettbewerber, ganz einfach mit dem kostenlosen Backlink-Forschungstool von SEOptimer überprüfen.
Bilder
Bilder können gecrawlt werden, tatsächlich gibt es einen speziellen Crawler nur für Bilder. Dieser Crawler ist bekannt als Googlebot Image, und er sammelt Bilder für die Datenbank.
Sitemaps
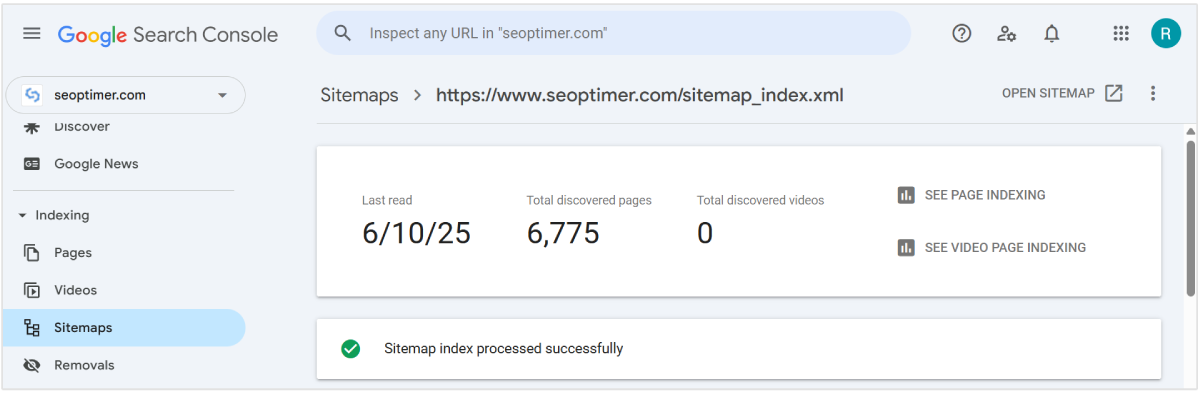
Es gibt eine Möglichkeit, Google direkter mitzuteilen, welche Seiten Sie crawlen lassen möchten. Sie können eine Sitemap mit einer detaillierten Liste der Seiten einreichen, die von Google gecrawlt werden sollen.
Verwenden Sie unseren XML-Sitemap-Generator, um eine Sitemap für Ihre gesamte Website zu erstellen. Erstellen Sie sie, benennen Sie sie. Und laden Sie sie auf Ihren Computer herunter, um sie in die Google Search Console hochzuladen.
Klicktiefe
Die "Klicktiefe" (auch bekannt als "Crawltiefe") zeigt Ihnen, wie viel Arbeit ein Crawler leisten müsste, um Ihre Seite zu erreichen und zu scannen. Sie möchten niemals, dass der Crawler zu viel Arbeit leisten muss, Sie möchten, dass Ihre Seite oder Website so crawlerfreundlich wie möglich ist.
Es sollte ungefähr drei Klicks oder weniger dauern, je mehr es dauert, desto mehr verlangsamt es den "Crawler".
Eine gute Struktur sollte es Ihnen ermöglichen, neue Seiten hinzuzufügen, ohne die "Klicktiefe" zu beeinflussen. Der "Crawler" sollte diese Seiten ebenfalls leicht erreichen können.
Zur Info: Eine gute Faustregel ist sicherzustellen, dass Sie von einer Seite Ihrer Website zu jeder anderen Seite Ihrer Website mit nicht mehr als 3 Klicks navigieren können. Dies stellt sicher, dass Google alle Ihre Seiten effizient finden und indexieren kann. Außerdem ist es großartig für die Benutzererfahrung.
Indizierungsanweisungen
Es gibt Anweisungen, denen Google beim Crawlen und bei der Ideenfindung von Seiten folgt. Robots.txt, noindex-Tag, robots-Meta-Tag und X-Robots-Tag. Keine Sorge, wir werden dies für Sie aufschlüsseln.
Robots.txt ist eine Root-Verzeichnisdatei, die bestimmte Seiten und Inhalte vor Google "zurückhält". Wenn der Crawler eine Seite scannt, wird er diese auf Informationen überprüfen. Wenn der Crawler diese Informationen nicht finden kann, wird er sein Crawlen "einstellen" und die Seite wird kein Teil der Suchergebnisse sein.
Das "noindex"-Tag verhindert, dass alle Arten von Crawlern eine Seite scannen und indizieren können.
Das "Robots meta tag" kann helfen, zu steuern, wie eine Seite indiziert und für Websurfer in den Suchergebnissen geladen werden soll.
X-Robots-Tag, ist ein Teil des HTTP-Headers und hilft dabei, das Verhalten des Crawlers zu kontrollieren. Es überwacht, wie die gesamte Seite indexiert wird. Sie können Bilder und Videos auf einer Seite mit dieser Methode blockieren. Sie sind auch in der Lage, Crawler-Typen individuell anzusprechen, aber nur, wenn es spezifiziert ist.
Wenn der Typ des Crawlers nicht angegeben ist, dann sind die "Anweisungen" für alle Google-Crawler.
URL-Struktur
Sie haben das vielleicht schon einmal gehört, aber stellen Sie sicher, dass Sie eine benutzerfreundliche URL haben.

Eine URL, die einfach ist, eine, die sowohl Ihre Verbraucher als auch Algorithmen lieben werden. Versuchen Sie, Ihre URL so kurz und [sweet] wie möglich zu halten.
Wenn Sie eine lange URL haben, kann dies nicht nur für das menschliche Auge, sondern auch für den Google-Bot verwirrend sein.
Je mehr der Googlebot verwirrt ist, desto mehr wird er seine Crawling-Ressourcen erschöpfen und das ist definitiv nicht das, was Sie wollen.
Häufige Probleme (und Lösungen) mit der Google-Crawling
Also, Sie haben eine Seite, aber sie funktioniert nicht so, wie Sie es möchten. Das könnte daran liegen, dass der Crawler Schwierigkeiten hat, Ihre Website zu scannen und zu indexieren.
Hier sind einige häufige [issues], auf die [people] bei Google Crawling gestoßen sind.
1. Google durchsucht Ihre Website nicht
Stellen Sie sicher, dass Sie überprüfen, ob Ihre Seite oder Website crawl-freundlich ist. Das bedeutet, eine gute URL zu haben, die internen Links und Backlinks einzubauen, wenn nötig, oder sich die Zeit zu nehmen, eine Sitemap zu erstellen, um Googlebot zu zeigen, wo gecrawlt werden soll.
Außerdem sollten Sie bedenken, dass es einige Zeit dauern kann, bis Google Ihre Website crawlt und indiziert, da es Sie erst finden muss!
2. Sie wurden aus dem Index von Google entfernt
Google wird eine Website entfernen, wenn es notwendig erscheint, sei es durch Gesetz, Relevanz oder weil die Richtlinien nicht eingehalten werden. Verwenden Sie unseren SEO-Crawler, um zu überprüfen, ob etwas den Crawler von Ihrer Seite blockieren könnte.
Nachdem Sie das getan haben, können Sie Ihre Website bei Google zur "Neubewertung" einreichen einreichen.
3. Sie haben "doppelte Inhalte"
Duplizierter Inhalt ist eine Seite, die "ähnlichen" Inhalt wie eine andere Seite hat oder mehrere URLs, die auf eine Seite verlinken.

Im Fall von Seiten mit ähnlichem Inhalt, was auch bedeuten könnte, dass Sie eine Desktop- und eine mobile Version einer Seite haben. "Allerdings" das häufigste Beispiel für "doppelten" Inhalt auf einer Anzahl von Seiten.
Diese können sowohl vermieden als auch behoben werden mit einer kanonischen URL, oder URL, die als Repräsentant für diese doppelten Seiten dient.
Google zeigt nur die Seite an, von der sie glauben, dass sie den "nützlichsten" Inhalt hat und bezeichnet sie als "kanonisch". Dies ist die Seite, die anstelle der Duplikate gecrawlt wird.
Um dies zu vermeiden, ziehen Sie in Betracht, den Text auf diesen Seiten umzuschreiben, damit sie nicht als Duplikate [verwechselt] werden.
4. Es gibt "Rendering-Probleme"
Wenn Sie Rendering-Probleme haben, stellen Sie sicher, dass Ihr Code nicht zu groß ist. Ihr Code muss so sauber wie möglich sein, damit der Crawler alles ordnungsgemäß "rendern" kann.
Wenn der Crawler die Seite nicht rendern kann, wird sie als leer betrachtet.
Google Crawler [FAQs]
Wie lange dauert es, bis Google eine Website "crawlt"?
Normalerweise benötigt Google einige Tage bis Wochen, um zu "crawlen". Sie können das Crawling mithilfe des Index-Statusberichts oder des URL-Inspektionstools überwachen. Denken Sie daran, dass Google nicht benachrichtigt wird, wenn eine neue Website oder Seite erstellt wird, es muss diese "crawlen" und finden.
Zur Info: Beliebtere Seiten werden schneller durchsucht. Brandneue Seiten benötigen in der Regel Wochen, um durchsucht zu werden, während angesehene Seiten wie NY Times, Wall Street Journal und Wikipedia mehrmals täglich durchsucht werden.
Was ist der Google Crawler-Algorithmus?
Der Google Crawler-Algorithmus basiert darauf, wie crawlerfreundlich Ihre Seite ist. Dies umfasst "Schlüsselwörter", URLs, "Inhalt" und Informationen, "Codierung" und vieles mehr. Es liegt an Ihnen, Google den besten Inhalt und die beste Anleitung bereitzustellen, damit es Ihre Seite finden und mit dem Crawlen beginnen kann.
Sind alle Seiten zum "Crawling" verfügbar?
Dies ist eine gute Frage. Die kurze Antwort ist nein. Einige Seiten können nicht gecrawlt und indexiert werden, weil sie passwortgeschützt sind, speziell von den Indexanweisungen ausgeschlossen wurden oder keine Links auf ihren Seiten haben.
Wann wird meine Website in der Google-Suche erscheinen?
Dies wird immer davon abhängen, wie lange es dauert, bis Ihre Website gecrawlt und indexiert wird. Dies könnte nur ein paar Tage oder so lange wie ein paar Wochen [dauern].
Welche anderen "Webcrawler" gibt es?
Ja! Es gibt jede Menge Webcrawler außerhalb von Googles fünfzehn. Hier sind einige zur Referenz:
- Es gibt "BingBot", der von der Suchmaschine Bing verwendet wird.
- "SlurpBot", verwendet von Yahoo! Dieser Webcrawler ist eine Mischung aus Yahoo! und Bing, weil Bing hauptsächlich Yahoo! antreibt.
- "ExaBot" ist die beliebteste Suchmaschine und der beliebteste Crawler in Frankreich.
- "AppleBot" wird von dem großen Technologieunternehmen Apple für "Spotlight"-Suche und Siri-Vorschläge verwendet.
- Facebook, glauben Sie es oder nicht, verwendet Links, um Inhalte an andere Profile zu senden und kann nur crawlen, wenn ein Link bereitgestellt wird.
Optimieren Sie Ihre Website für das Google-Crawling
Jetzt, da Sie die Grundlagen des Google Crawling und dessen Funktionsweise verstehen, nutzen Sie es zu Ihrem Vorteil! Lassen Sie Ihre Website korrekt indizieren und steigen Sie an die Spitze der Suchergebnisseite. Es ist "kostenlos" und steht Ihnen vollständig zur Verfügung.