Was ist Robots.txt?
Robots.txt ist eine Datei in Textform, die Bot-Crawler anweist, bestimmte Seiten zu indizieren oder nicht zu indizieren. Sie ist auch bekannt als der Türsteher für Ihre gesamte Website. Das erste Ziel von Bot-Crawlern ist es, die robots.txt-Datei zu finden und zu lesen, bevor sie auf Ihre Sitemap oder irgendwelche Seiten oder Ordner zugreifen.
Mit robots.txt können Sie genauer:
- Regeln Sie, wie Suchmaschinen-Bots Ihre Seite durchsuchen
- Gewähren Sie bestimmten Zugriff
- Helfen Sie Suchmaschinen-Spidern beim Indizieren des Seiteninhalts
- Zeigen Sie, wie Inhalte den Benutzern bereitgestellt werden sollen
Robots.txt ist ein Teil des Robots Exclusion Protocol (R.E.P), das aus den Direktiven auf Website-/Seiten-/URL-Ebene besteht. Obwohl Suchmaschinen-Bots immer noch deine gesamte Website durchsuchen können, liegt es an dir, ihnen zu helfen zu entscheiden, ob bestimmte Seiten die Zeit und Mühe wert sind.
Warum Sie eine Robots.txt benötigen
Ihre Website benötigt keine robots.txt-Datei, damit sie ordnungsgemäß funktioniert. Die Hauptgründe, warum Sie eine robots.txt-Datei benötigen, sind, dass Bots beim Crawlen Ihrer Seite um Erlaubnis bitten, um zu versuchen, Informationen über die Seite zum Indizieren abzurufen. Zusätzlich bittet eine Website ohne robots.txt-Datei im Grunde Bot-Crawler darum, die Seite nach eigenem Ermessen zu indizieren. Es ist wichtig zu verstehen, dass Bots Ihre Seite auch ohne die robots.txt-Datei crawlen werden.
Der Standort Ihrer robots.txt-Datei ist ebenfalls wichtig, da alle Bots nach www.123.com/robots.txt suchen werden. Wenn sie dort nichts finden, werden sie davon ausgehen, dass die Website keine robots.txt-Datei hat und alles indizieren. Die Datei muss eine ASCII- oder UTF-8-Textdatei sein. Es ist auch wichtig zu beachten, dass Regeln groß- und kleinschreibungsempfindlich sind.
Hier sind einige Dinge, die robots.txt tun wird und nicht tun wird:
- Die Datei kann den Zugriff von Crawlern auf bestimmte Bereiche Ihrer Website steuern. Sie müssen beim Einrichten von robots.txt sehr vorsichtig sein, da es möglich ist, die gesamte Website vom Indexieren zu blockieren.
- Es verhindert, dass doppelter Inhalt indexiert wird und in den Suchergebnissen erscheint.
- Die Datei gibt die Crawl-Verzögerung an, um zu verhindern, dass Server überlastet werden, wenn die Crawler gleichzeitig mehrere Inhalte laden.
Hier sind einige Googlebots, die von Zeit zu Zeit auf Ihrer Website krabbeln könnten:
| Webcrawler | User-Agent-String |
| Googlebot Nachrichten | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (Mobiltelefon mit Basisfunktionen) | SAMSUNG-SGH-E250/1.0 Profil/MIDP-2.0 Konfiguration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (kompatibel; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (kompatibel; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (PPC-Landingpage-Qualität) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google App Crawler (Ressourcen für Mobilgeräte abrufen) | AdsBot-Google-Mobile-Apps |
Sie können eine Liste zusätzlicher Bots hier finden.
- Die Dateien helfen bei der Spezifikation des Standorts der Sitemaps.
- Es verhindert auch, dass Suchmaschinen-Bots verschiedene Dateien auf der Website wie Bilder und PDFs indizieren.
Wenn ein Bot deine Webseite besuchen möchte (zum Beispiel www.123.com), überprüft er zunächst www.123.com/robots.txt und findet:
User-agent: *
Disallow: /
Dieses Beispiel weist alle (User-agents*) Suchmaschinen-Bots an, die Website nicht zu indizieren (Disallow: /).
Wenn Sie den Schrägstrich aus Disallow entfernen, wie im folgenden Beispiel,
User-agent: *
Disallow:
die Bots könnten alles auf der Website durchsuchen und indizieren. Deshalb ist es wichtig, die Syntax von robots.txt zu verstehen.
Verständnis der robots.txt-Syntax
Die Syntax von Robots.txt kann als die „Sprache“ von Robots.txt-Dateien angesehen werden. Es gibt 5 gängige Begriffe, auf die Sie in einer Robots.txt-Datei wahrscheinlich stoßen werden. Sie sind:
- User-agent: Der spezifische Webcrawler, dem Sie Crawling-Anweisungen geben (normalerweise eine Suchmaschine). Eine Liste der meisten User-Agents finden Sie hier.
- Disallow: Der Befehl, der einem User-Agent mitteilt, eine bestimmte URL nicht zu crawlen. Nur eine "Disallow:"-Zeile ist für jede URL erlaubt.
- Erlauben (Nur anwendbar für Googlebot): Der Befehl teilt Googlebot mit, dass er auf eine Seite oder einen Unterordner zugreifen kann, auch wenn die übergeordnete Seite oder der übergeordnete Unterordner möglicherweise nicht erlaubt ist.
- Crawl-delay: Die Anzahl an Millisekunden, die ein Crawler warten sollte, bevor er Seiteninhalte lädt und durchsucht. Beachten Sie, dass Googlebot diesen Befehl nicht anerkennt, aber die Crawl-Rate kann in der Google Search Console eingestellt werden.
- Sitemap: Wird verwendet, um den Standort von XML-Sitemap(s) zu kennzeichnen, die mit einer URL verbunden sind. Beachten Sie, dass dieser Befehl nur unterstützt wird von Google, Ask, Bing und Yahoo.
Ergebnisse der Robots.txt-Anweisungen
Sie erwarten drei Ergebnisse, wenn Sie robots.txt-Anweisungen erteilen:
- Vollständig erlauben
- Vollständig verbieten
- Bedingt erlauben
Lassen Sie uns jeden unten untersuchen.
Vollzugriff
Dieses Ergebnis bedeutet, dass alle Inhalte auf Ihrer Website gecrawlt werden können. Robots.txt-Dateien sollen das Crawlen durch Suchmaschinen-Bots blockieren, daher kann dieser Befehl sehr wichtig sein.
Dieses Ergebnis könnte bedeuten, dass Sie überhaupt keine robots.txt-Datei auf Ihrer Website haben. Selbst wenn Sie sie nicht haben, werden Suchmaschinen-Bots trotzdem danach auf Ihrer Seite suchen. Wenn sie sie nicht finden, dann werden sie alle Teile Ihrer Website durchsuchen.
Die andere Option unter diesem Ergebnis ist, eine robots.txt-Datei zu erstellen, aber sie leer zu lassen. Wenn die Spinne kommt, um zu crawlen, wird sie die robots.txt-Datei erkennen und sogar lesen. Da sie dort nichts finden wird, wird sie fortfahren, den Rest der Seite zu crawlen.
Wenn Sie eine robots.txt-Datei haben und die folgenden zwei Zeilen darin stehen,
User-agent:*
Disallow:
die Suchmaschinen-Spider werden Ihre Website durchsuchen, die robots.txt-Datei identifizieren und sie lesen. Sie werden zur zweiten Zeile gelangen und dann mit dem Durchsuchen des Rests der Website fortfahren.
Vollständiges Verbot
Hier wird kein Inhalt gecrawlt und indexiert. Dieser Befehl wird durch diese Zeile ausgegeben:
User-agent:*
Disallow:/
Wenn wir von keinem Inhalt sprechen, meinen wir, dass nichts von der Website (Inhalt, Seiten usw.) gecrawlt werden kann. Das ist niemals eine gute Idee.
Bedingte Zulassung
Dies bedeutet, dass nur bestimmte Inhalte auf der Website gecrawlt werden können.
Ein bedingtes Erlauben hat dieses Format:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Erlauben:/
Sie können die vollständige robots.txt-Syntax hier finden.
Beachten Sie, dass blockierte Seiten immer noch indexiert werden können, auch wenn Sie die URL wie im Bild unten gezeigt disallowt haben:
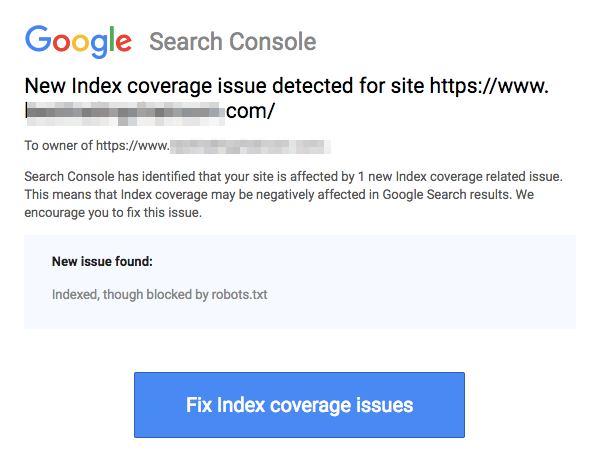
Sie könnten eine E-Mail von Suchmaschinen erhalten, dass Ihre URL wie im obigen Screenshot indexiert wurde. Wenn Ihre nicht zugelassene URL von anderen Seiten verlinkt ist, wie z.B. Ankertext in Links, wird sie indexiert. Die Lösung dafür ist, 1) Ihre Dateien auf Ihrem Server mit einem Passwort zu schützen, 2) den noindex-Meta-Tag zu verwenden oder 3) die Seite vollständig zu entfernen.
Kann ein Roboter trotzdem meine robots.txt-Datei durchsuchen und ignorieren?
Ja. es ist möglich, dass ein Roboter robots.txt umgehen kann. Dies liegt daran, dass Google andere Faktoren wie externe Informationen und eingehende Links verwendet, um zu bestimmen, ob eine Seite indexiert werden soll oder nicht. Wenn Sie nicht möchten, dass eine Seite überhaupt indexiert wird, sollten Sie den noindex-Robots-Meta-Tag verwenden. Eine andere Möglichkeit wäre die Verwendung des X-Robots-Tag-HTTP-Headers.
Kann ich nur böse Roboter blockieren?
Es ist theoretisch möglich, schlechte Roboter zu blockieren, aber es könnte in der Praxis schwierig sein, dies zu tun. Lassen Sie uns einige Möglichkeiten anschauen, wie man das machen kann:
- Sie können einen schlechten Roboter blockieren, indem Sie ihn ausschließen. Sie müssen jedoch den Namen kennen, nach dem der bestimmte Roboter im User-Agent-Feld sucht. Dann müssen Sie einen Abschnitt in Ihrer robots.txt-Datei hinzufügen, der den schlechten Roboter ausschließt.
- Serverkonfiguration. Dies würde nur funktionieren, wenn der Betrieb des bösen Roboters von einer einzigen IP-Adresse aus erfolgt. Serverkonfiguration oder eine Netzwerk-Firewall wird den bösen Roboter daran hindern, auf Ihren Webserver zuzugreifen.
- Verwendung fortgeschrittener Firewall-Regelkonfigurationen. Diese werden automatisch den Zugriff auf die verschiedenen IP-Adressen blockieren, wo Kopien des bösen Roboters existieren. Ein gutes Beispiel für Bots, die auf verschiedenen IP-Adressen operieren, ist im Fall von gekaperten PCs, die sogar Teil eines größeren Botnetzes sein könnten (erfahren Sie mehr über Botnet hier).
Wenn der böse Roboter von einer einzigen IP-Adresse aus operiert, können Sie seinen Zugriff auf Ihren Webserver über die Serverkonfiguration oder mit einer Netzwerk-Firewall blockieren.
Wenn Kopien des Roboters an einer Reihe verschiedener IP-Adressen betrieben werden, wird es schwieriger, sie zu blockieren. Die beste Option in diesem Fall ist die Verwendung von fortgeschrittenen Firewall-Regelkonfigurationen, die automatisch den Zugriff auf IP-Adressen blockieren, die viele Verbindungen herstellen; leider kann dies auch den Zugriff von guten Bots beeinträchtigen.
Was sind einige der besten SEO-Praktiken beim Einsatz von robots.txt?
An dieser Stelle fragen Sie sich vielleicht, wie man durch die sehr kniffligen Gewässer von robots.txt navigiert. Lassen Sie uns dies genauer betrachten:
- Stellen Sie sicher, dass Sie keine Inhalte oder Bereiche Ihrer Website blockieren, die Sie gecrawlt haben möchten.
- Verwenden Sie einen anderen Sperrmechanismus als robots.txt, wenn Sie möchten, dass Link-Equity von einer Seite mit robots.txt (was bedeutet, dass sie praktisch blockiert ist) zum Linkziel weitergegeben wird.
- Verwenden Sie nicht robots.txt, um zu verhindern, dass sensible Daten wie private Benutzerinformationen in den Suchmaschinenergebnissen erscheinen. Dies könnte anderen Seiten erlauben, auf Seiten zu verlinken, die private Benutzerinformationen enthalten, was dazu führen kann, dass die Seite indiziert wird. In diesem Fall wurde robots.txt umgangen. Andere Optionen, die Sie hier erkunden können, sind Passwortschutz oder die noindex Meta-Direktive.
- Es ist nicht notwendig, Direktiven für jeden einzelnen Crawler einer Suchmaschine anzugeben, da die meisten User-Agents, wenn sie zur gleichen Suchmaschine gehören, denselben Regeln folgen. Google verwendet Googlebot für Suchmaschinen und Googlebot Image für Bildersuchen. Der einzige Vorteil, wenn man weiß, wie man jeden Crawler spezifiziert, ist, dass man genau einstellen kann, wie Inhalte auf Ihrer Website gecrawlt werden.
- Wenn Sie die Datei robots.txt geändert haben und möchten, dass Google sie schneller aktualisiert, reichen Sie sie direkt bei Google ein. Anweisungen dazu finden Sie, wenn Sie hier klicken. Es ist wichtig zu beachten, dass Suchmaschinen den Inhalt von robots.txt zwischenspeichern und den zwischengespeicherten Inhalt mindestens einmal pro Tag aktualisieren.
Grundlegende Richtlinien für robots.txt
Nun, da Sie ein grundlegendes Verständnis von SEO in Bezug auf robots.txt haben, welche Dinge sollten Sie beachten, wenn Sie robots.txt verwenden? In diesem Abschnitt betrachten wir einige Richtlinien, die Sie beim Einsatz von robots.txt befolgen sollten, obwohl es wichtig ist, die gesamte Syntax tatsächlich zu lesen.
Format und Standort
Der Texteditor, den Sie wählen, um eine robots.txt-Datei zu erstellen, muss in der Lage sein, Standard ASCII- oder UTF-8-Textdateien zu erstellen. Die Verwendung einer Textverarbeitung ist keine gute Idee, da einige Zeichen, die das Crawling beeinflussen können, hinzugefügt werden könnten.
Während fast jeder Texteditor verwendet werden kann, um Ihre robots.txt-Datei zu erstellen, wird dieses Tool sehr empfohlen, da es das Testen gegenüber Ihrer Website ermöglicht.
Hier sind weitere Richtlinien zu Format und Ort:
- Sie müssen die von Ihnen erstellte Datei „robots.txt“ nennen, da der Dateiname groß- und kleinschreibungsempfindlich ist. Es werden keine Großbuchstaben verwendet.
- Sie können nur eine robots.txt-Datei auf der gesamten Website haben.
- Die robots.txt-Datei befindet sich nur an einem Ort: im Stammverzeichnis des Website-Hosts, auf den sie anwendbar ist. Beachten Sie, dass sie nicht in einem Unterverzeichnis platziert werden kann. Wenn Ihre Websitehttp://www.123.com/, dann befindet sich die robots.txt an der Stellehttp://www.123.com/robots.txt, nicht http://www.123.com/pages/robots.txtBeachten Sie, dass die robots.txt-Datei auf Subdomains angewendet werden kann (http://website.123.com/robots.txt) und sogar nicht-standard Ports, wiehttp://www.123.com: 8181/robots.txt.
Wie bereits erwähnt, ist robots.txt nicht der beste Weg, um zu verhindern, dass sensible persönliche Informationen indexiert werden. Dies ist ein berechtigtes Anliegen, besonders jetzt mit der kürzlich implementierten DSGVO. Datenschutz sollte nicht kompromittiert werden. Punkt.
Wie stellen Sie dann sicher, dass robots.txt keine sensiblen Daten in den Suchergebnissen anzeigt?
Die Verwendung eines separaten Unterverzeichnisses, das im Web „nicht auflistbar“ ist, verhindert die Verbreitung sensibler Materialien. Sie können sicherstellen, dass es „nicht auflistbar“ ist, indem Sie die Serverkonfiguration verwenden. Speichern Sie einfach alle Dateien, die Sie nicht möchten, dass robots.txt sie besucht und indiziert, in diesem Unterverzeichnis.
Führt das Auflisten von Seiten oder Verzeichnissen in der robots.txt-Datei zu unbeabsichtigtem Zugriff?
Wie bereits erwähnt, sollte das Ablegen aller Dateien, die Sie nicht indiziert haben möchten, in einem separaten Unterverzeichnis und das anschließende Unzugänglichmachen über Serverkonfigurationen sicherstellen, dass sie nicht in den Suchergebnissen erscheinen. Die einzige Auflistung, die Sie dann in der Datei robots.txt vornehmen, ist der Verzeichnisname. Der einzige Weg, auf diese Dateien zuzugreifen, ist über einen direkten Link zu einer der Dateien.
Hier ist ein Beispiel:
Statt
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Verwenden
User-Agent:*
Disallow:/norobots/
Sie müssen dann ein Verzeichnis „norobots“ erstellen, das foo.html und bar.html enthält. Beachten Sie, dass Ihre Serverkonfigurationen klarstellen müssen, dass kein Verzeichnislisting für das Verzeichnis „norobots“ generiert wird.
Dies ist möglicherweise kein sehr sicherer Ansatz, da die Person oder der Bot, der Ihre Website angreift, immer noch sehen kann, dass Sie ein Verzeichnis „norobots“ haben, auch wenn sie möglicherweise nicht in der Lage sind, die Dateien innerhalb des Verzeichnisses anzusehen. Es könnte jedoch jemand einen Link zu diesen Dateien auf seiner Website veröffentlichen oder, noch schlimmer, der Link könnte in einer öffentlich zugänglichen Protokolldatei erscheinen (z. B. ein Webserver-Protokoll als Referrer). Auch eine Fehlkonfiguration des Servers ist möglich, was zu einer Verzeichnisauflistung führen könnte.
Was bedeutet das? Robots.txt kann Ihnen nicht dabei helfen, den Zugriff zu kontrollieren, aus dem einfachen Grund, dass es nicht dafür gedacht ist. Ein gutes Beispiel ist ein „Eintritt verboten-Schild.“ Es gibt Menschen, die trotzdem die Anweisung missachten werden.
Wenn es Dateien gibt, die nur von autorisierten Personen zugänglich sein sollen, helfen Serverkonfigurationen bei der Authentifizierung. Wenn Sie ein CMS (Content Management System) verwenden, haben Sie Zugriffskontrollen auf einzelnen Seiten und Ressourcensammlungen.
Können Sie robots.txt für SEO optimieren?
Absolut. Der beste Leitfaden zur Optimierung von robots.txt ist der Inhalt der Website. Eine kurze Erinnerung: Robots.txt sollte niemals verwendet werden, um Seiten daran zu hindern, von Suchmaschinen-Bots gecrawlt zu werden. Verwenden Sie es nur, um die Bereiche Ihrer Website zu blockieren, die nicht öffentlich zugänglich sind, zum Beispiel Anmeldeseiten wie wp-admin.
Dies ist die Disallow-Zeile für die Anmeldeseite von Neil Patel auf einer seiner Websites:
User-agent:*
Disallow:/wp-admin/
Erlauben:/wp-admin/admin-ajax.php
Sie können diese Disallow-Zeile verwenden, um zu verhindern, dass Ihr Login indexiert wird.
Wenn es bestimmte Seiten gibt, die Sie nicht indexiert haben möchten, verwenden Sie denselben Befehl wie oben. Ein Beispiel:
User-agent:*
Disallow:/page/
Geben Sie die Seite an, die Sie nach dem Schrägstrich nicht indiziert haben möchten, und schließen Sie mit einem weiteren Schrägstrich. Zum Beispiel:
User-agent:*
Disallow:/page/thank-you/
Welche Seiten möchten Sie möglicherweise vom Indexieren ausschließen?
- Doppelter Inhalt, der absichtlich ist. Was bedeutet das? Manchmal erstellen Sie absichtlich doppelten Inhalt, um einen bestimmten Zweck zu erreichen. Ein gutes Beispiel ist eine druckerfreundliche Version einer bestimmten Webseite. Sie können robots.txt verwenden, um die Indizierung der druckerfreundlichen Version des identischen Inhalts zu blockieren.
- Dankeseiten. Der Grund, warum Sie diese Seite vom Indexieren blockieren möchten, ist einfach: Sie soll der letzte Schritt im Verkaufstrichter sein. Wenn Ihre Besucher auf dieser Seite ankommen, sollten sie den gesamten Verkaufstrichter durchlaufen haben. Wenn diese Seite indexiert wird, bedeutet das, dass Sie möglicherweise Leads verpassen oder dass Sie falsche Leads erhalten.
Der Befehl, um eine solche Seite zu blockieren, lautet:
Disallow:/thank-you/
Noindex und NoFollow
Wie wir in diesem Artikel bereits gesagt haben, ist die Verwendung von robots.txt keine 100%ige Garantie dafür, dass Ihre Seite nicht indexiert wird. Lassen Sie uns zwei Möglichkeiten anschauen, um sicherzustellen, dass Ihre blockierte Seite tatsächlich nicht indexiert wird.
Die noindex-Direktive
Dies funktioniert in Verbindung mit dem Disallow-Befehl. Verwenden Sie beide in Ihrer Direktive, wie folgt:
Disallow:/thank-you/
Die nofollow-Direktive
Dies funktioniert, um Google-Bots speziell anzuweisen, die Links auf einer Seite nicht zu crawlen. Dies ist nicht Teil der robots.txt-Datei. Um den nofollow-Befehl zu verwenden, um zu verhindern, dass Seiten gecrawlt und indiziert werden, müssen Sie den Quellcode der spezifischen Seite finden, die Sie nicht indiziert haben möchten.
Fügen Sie dies zwischen den öffnenden und schließenden Head-Tags ein:
<meta name = „robots“ content=„nofollow“>
Sie können sowohl „nofollow“ als auch „noindex“ gleichzeitig verwenden. Verwenden Sie diese Zeile Code:
<meta name = „robots“ content=„noindex,nofollow“>
Erstellen von robots.txt
Wenn Sie es schwierig finden, robots.txt unter Verwendung aller notwendigen Formate und Syntax zu schreiben, die Sie verstehen und befolgen müssen, können Sie Werkzeuge verwenden, die den Prozess vereinfachen. Ein gutes Beispiel ist unser kostenloser robots.txt Generator.
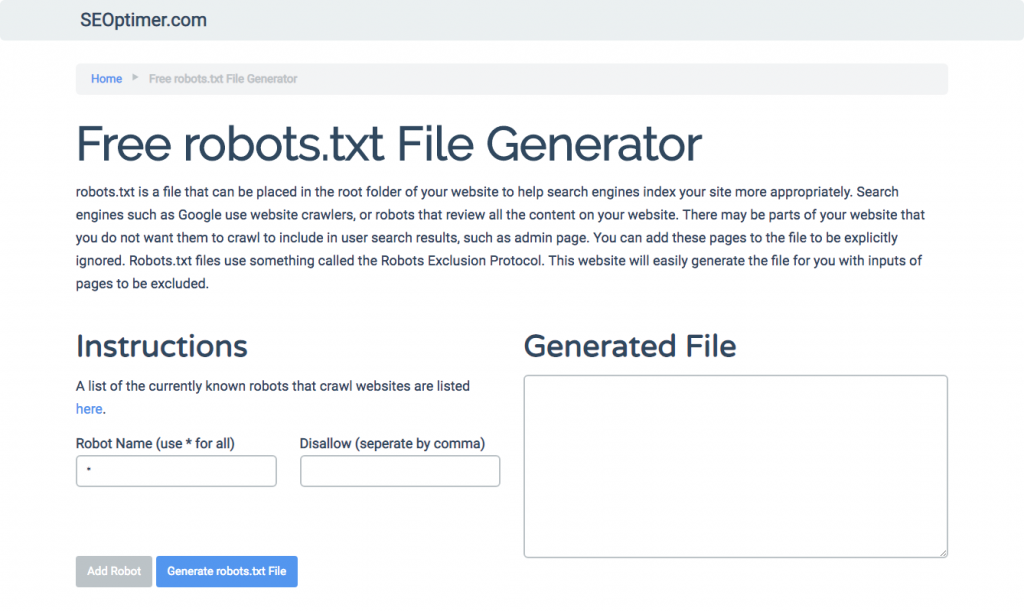
Dieses Tool ermöglicht es Ihnen, den Typ des Ergebnisses auszuwählen, den Sie auf Ihrer Website benötigen, und die Datei oder Verzeichnisse hinzuzufügen, die Sie hinzufügen möchten. Sie können sogar Ihre Datei testen und sehen, wie Ihre Konkurrenz abschneidet.
Testen Ihrer robots.txt-Datei
Sie müssen Ihre robots.txt-Datei testen, um sicherzustellen, dass sie wie erwartet funktioniert.
Verwenden Sie Googles robots.txt Tester.
Um dies zu tun, melden Sie sich bei Ihrem Webmaster-Konto an.
- Als Nächstes wählen Sie Ihre Eigenschaft aus. In diesem Fall ist es Ihre Website.
- Klicken Sie in der linken Seitenleiste auf „crawl“.
- Klicken Sie auf „robots.txt Tester“.
- Ersetzen Sie jeglichen bestehenden Code durch Ihre neue robots.txt-Datei.
- Klicken Sie auf „testen“.
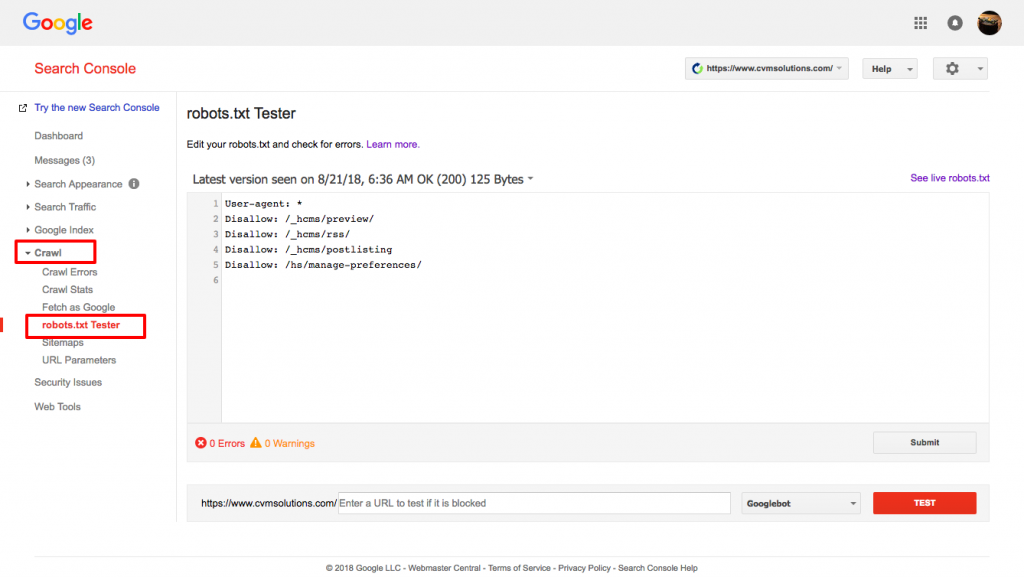
Sie sollten in der Lage sein, ein Textfeld „erlaubt“ zu sehen, wenn die Datei gültig ist. Für weitere Informationen schauen Sie sich diesen ausführlichen Leitfaden zum Google robots.txt Tester an.
Wenn Ihre Datei gültig ist, ist es jetzt an der Zeit, sie in Ihr Stammverzeichnis hochzuladen oder sie dort zu speichern, falls bereits eine andere robots.txt-Datei vorhanden ist.
Wie man robots.txt zu Ihrer WordPress-Seite hinzufügt
Um eine robots.txt-Datei zu Ihrer WordPress-Datei hinzuzufügen, werden wir Plugin- und FTP-Optionen behandeln.
Für die Plugin-Option können Sie ein Plugin wie All in One SEO Pack verwenden
Um dies zu tun, loggen Sie sich in Ihr WordPress-Dashboard ein
Scrollen Sie nach unten, bis Sie zu „plugins“ gelangen
Klicken Sie auf „neu hinzufügen“
Gehen Sie zu „Such-Plugins“
Tippe „All in One SEO Pack“
Installieren Sie es und aktivieren Sie es
Im Abschnitt Allgemeine Einstellungen des All in One SEO-Plugins können Sie die noindex- und nofollow-Regeln konfigurieren, die in Ihre robots.txt-Datei aufgenommen werden sollen.
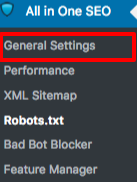
Sie können festlegen, welche URLs NOINDEX, NOFOLLOW sein sollen. Wenn diese nicht markiert werden, werden sie standardmäßig indexiert:
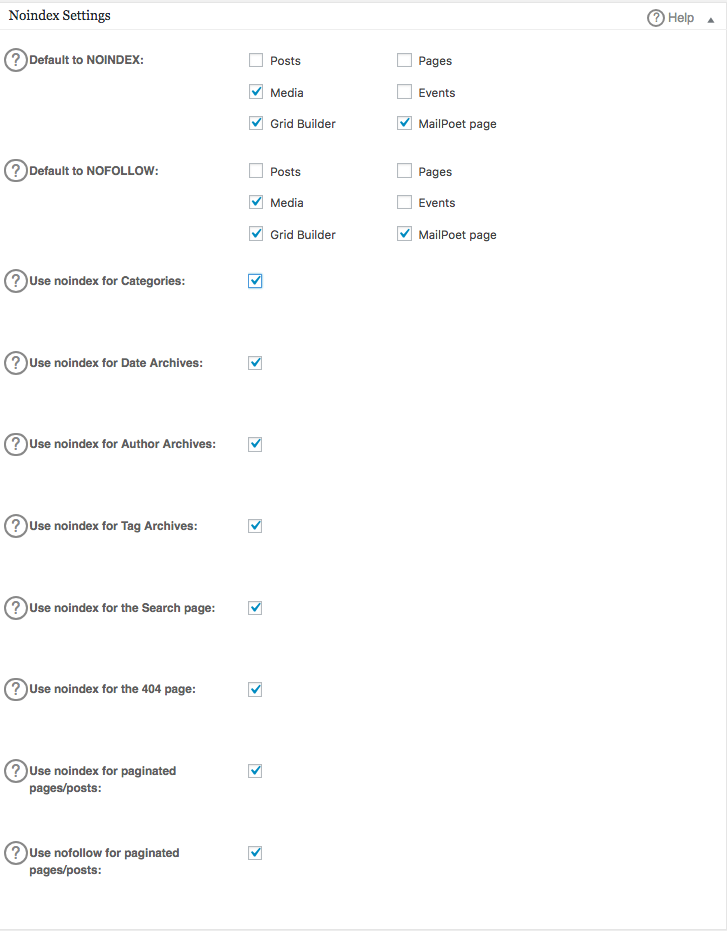
Um fortgeschrittene Regeln in Ihrer robots.txt-Datei zu erstellen, klicken Sie auf den Feature-Manager und dann auf den Aktivieren-Button direkt unterhalb von robots.txt.
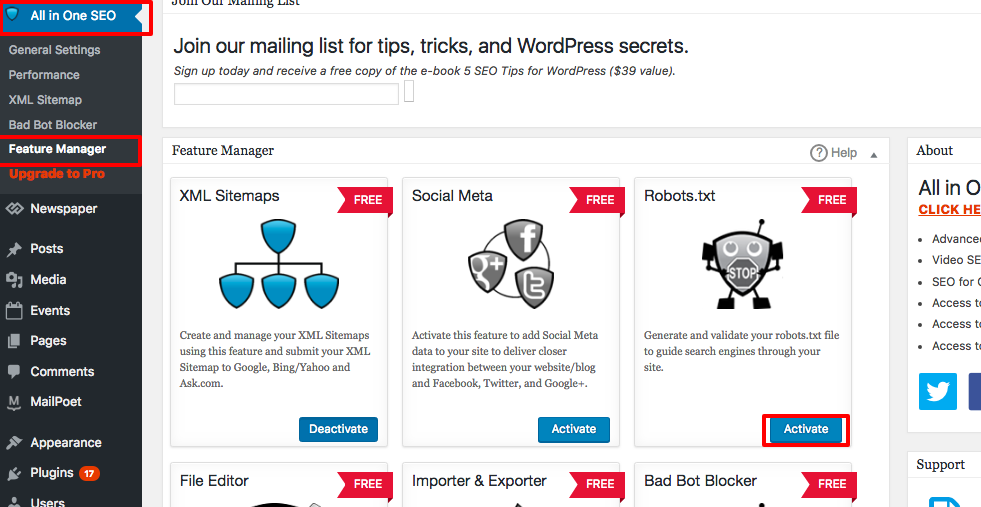
Robots.txt erscheint jetzt direkt unter dem Feature-Manager. Klicken Sie darauf. Sie werden einen Abschnitt sehen, der „Erstellen Sie eine robots.txt-Datei“ genannt wird.
Es gibt einen Bereich für den Regel-Builder, der es Ihnen ermöglicht, die Regeln auszuwählen und auszufüllen, die Sie für Ihre Website möchten, abhängig davon, was Sie indexiert haben möchten und was nicht.
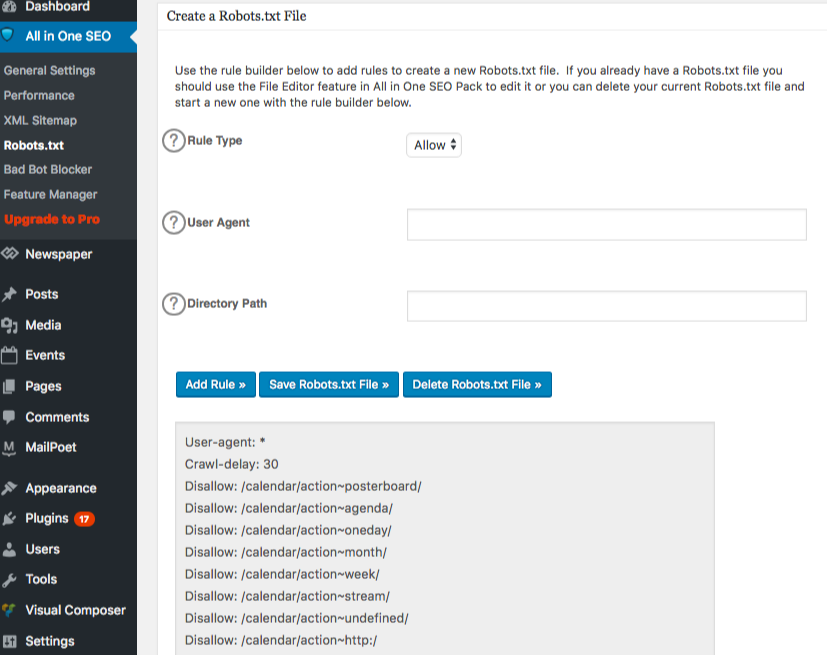
Sobald Sie die Regel erstellt haben, klicken Sie auf „Regel hinzufügen“.
Die Regel wird dann im erstellten robots.txt-Ordner aufgelistet.
Sie werden eine Nachricht sehen, die anzeigt, dass „All in One Options“ aktualisiert wurden.
Ein weiterer Weg, den Sie nutzen können, ist das direkte Hochladen Ihrer robots.txt-Datei über Ihren FTP (File Transfer Protocol)-Client wie FileZilla.
Sobald Sie Ihre robots.txt-Datei generiert haben, können Sie sie finden und ersetzen. Ihre robots.txt-Datei befindet sich in: „/applications/[ORDNERNAME]/public_html.“
So bearbeiten Sie die robots.txt-Datei auf Ihrem Wix
Wix generiert eine robots.txt-Datei für Websites, die die Web-Building-Plattform verwenden. Um sie anzusehen, fügen Sie „/robots.txt“ zu Ihrer Domain hinzu. Die Dateien, die zu robots.txt hinzugefügt werden, haben mit der Struktur von Wix-Websites zu tun, zum Beispiel noflashhtml-Links, die nicht zum SEO-Wert Ihrer Wix-betriebenen Website beitragen.
Sie können Ihre robots.txt-Datei nicht bearbeiten, wenn Ihre Website von Wix betrieben wird. Sie können nur andere Optionen verwenden, wie das Hinzufügen eines „noindex tag“ zu den Seiten, die Sie nicht indiziert haben möchten.
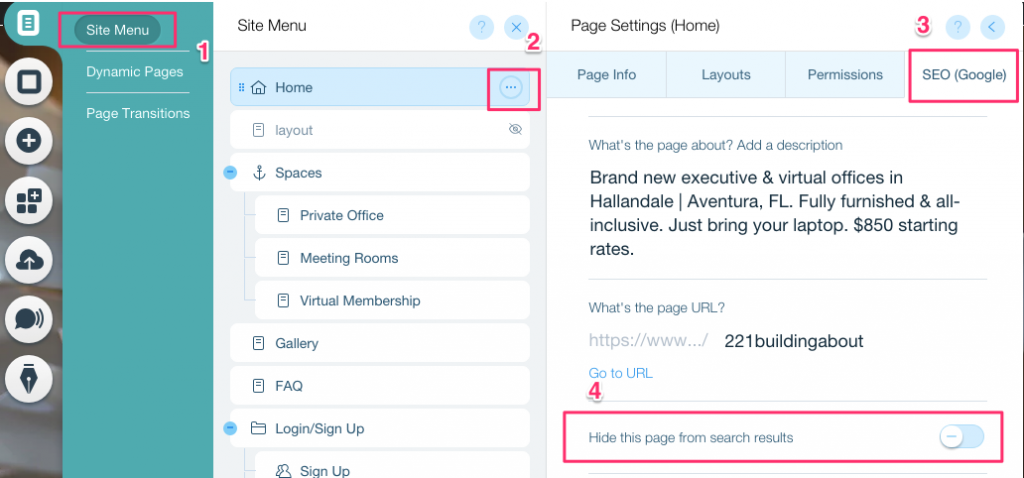
Um einen noindex-Tag für eine bestimmte Seite zu erstellen:
- Klicken Sie auf Seitenmenü
- Klicken Sie auf die Option Einstellungen für die spezifische Seite
- Wählen Sie SEO (Google) Tag
- Aktivieren Sie Diese Seite in Suchergebnissen verbergen
So bearbeiten Sie die robots.txt-Datei auf Ihrem Shopify
Genau wie bei Wix fügt Shopify automatisch eine nicht editierbare robots.txt-Datei zu Ihrer Website hinzu. Wenn Sie nicht möchten, dass einige Seiten indiziert werden, müssen Sie den „noindex tag“ hinzufügen oder die Seite nicht veröffentlichen. Sie können auch Meta-Tags im Header-Bereich der Seiten hinzufügen, die nicht indiziert werden sollen. Dies sollten Sie Ihrem Header hinzufügen:
<meta name= „robots“ content = „noindex“>
Shopify hat eine umfassende Anleitung erstellt, wie man Seiten vor Suchmaschinen verbergen kann, der Sie folgen können.
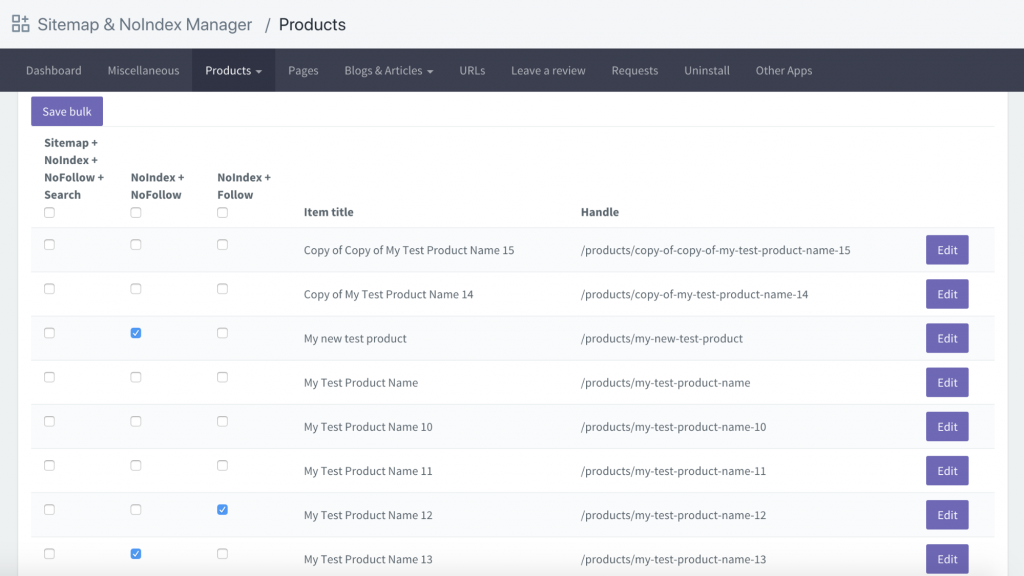
Eine weitere Option ist das Herunterladen einer App namens Sitemap & NoIndex Manager von Orbis Labs. Sie können einfach die Optionen noindex oder nofollow für jede Seite auf Ihrer Shopify-Website auswählen: