Je weet wel wanneer je Google gebruikt om naar een dienst te zoeken, of informatie te vinden? En zodra de pagina is geladen, is er altijd één website helemaal bovenaan.
Sites in positie 1 op de Google zoekmachine resultatenpagina (SERP) krijgen het merendeel van alle klikken. Dus het hoeft geen betoog dat het belangrijk is om "SEO best practices" te volgen om te proberen de positie van je site in de SERP te maximaliseren.
Maar weet je hoe Google je site überhaupt in de eerste plaats "vindt"?
Het antwoord is Google’s crawlers. Google’s crawlers zijn als kleine digitale robots die websites bezoeken en informatie over die sites verzamelen.
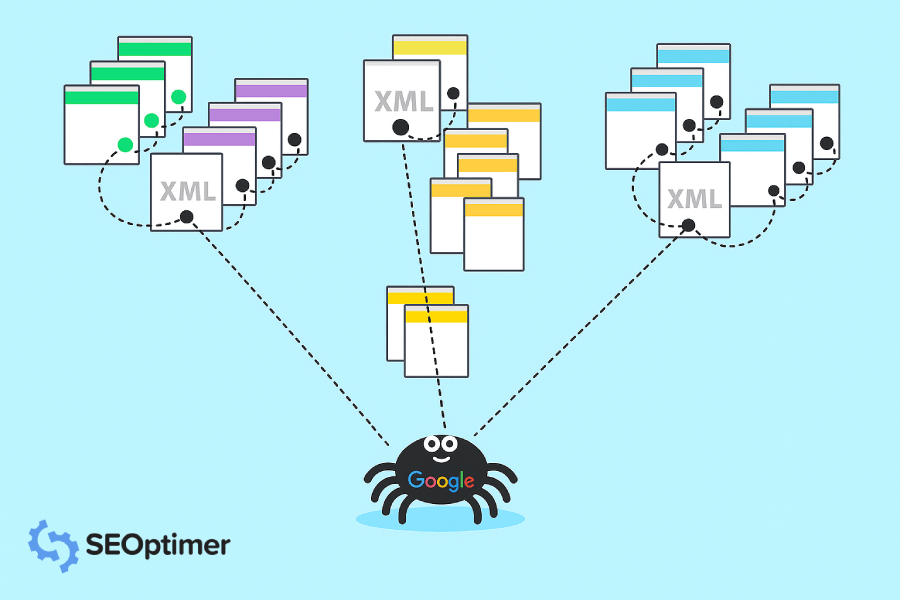
Daarna indexeert Google al die informatie en gebruikt het om zijn zoekalgoritme te verbeteren. Wanneer iemand een [zoekopdracht] in Google typt, bekijkt het zoekalgoritme alle geïndexeerde informatie om de beste resultaten voor de [zoekopdracht] van de persoon te vinden.
En dat is hoe Google in staat is om je de beste resultaten te brengen wanneer je naar iets op het internet [zoekt]!
Wat is een Google Crawler?
Een Google Crawler staat ook bekend als een “robot” of “spider,” (begrijp je het, omdat ze kruipen) en ze gaan van website naar website op zoek naar nieuwe [informatie] om op te slaan in hun databases. Er zijn 15 soorten crawlers die door Google worden gebruikt, maar de belangrijkste is Googlebot.

Hoewel Google krachtig is, kan het niet alles doen, elke keer dat een nieuwe webpagina wordt gemaakt, weet Google er niets van totdat die pagina is gecrawld.
Google gebruikt de Googlebot om constant de nieuwste informatie te verkrijgen en in zijn database op te slaan.
Google indexeren vs Google crawlen
Indexeren gebeurt alleen nadat de website is gecrawld door GoogleBot. Wanneer het wordt gecrawld, wordt het gescand en de informatie die van die site of pagina is gescand, wordt opgeslagen in de Google-index.
De index zal de pagina's dienovereenkomstig categoriseren en rangschikken in de zoekresultaten.
Waarom zijn Google Crawlers belangrijk?
Dus waarom is dit allemaal belangrijk?
Nou, laten we zeggen dat je een bedrijf runt en een website hebt. Je wilt dat je website zo dicht mogelijk bij de top staat. Als je website niet wordt [gecrawld] en [gescand], zal deze niet laden op de zoekpagina.
Zonder enige internetaanwezigheid zult u uw publiek of consumenten niet kunnen bereiken. Crawlen en indexeren maken het iets gemakkelijker voor websites om enige aandacht te krijgen.
Hoe een Google Crawler Werkt
Dus, je weet wat het is maar hoe werkt het? Hoewel Google krachtig is, kan het niet alles doen, elke keer dat een nieuwe webpagina wordt gemaakt weet Google er niets van totdat die pagina is gecrawld. Google gebruikt de Googlebot om constant extra informatie te verkrijgen en op te slaan in zijn database.
Zodra die webpagina is gecrawld of gescand. De pagina wordt gerenderd en krijgt een HTML-, CSS-, JavaScript- en third-party code, die allemaal nodig zijn voor de Googlebot om websites te indexeren en te rangschikken. Googlebot, de grootste crawler, kan alle webpagina's en websites zien en renderen met Chromium.
De Chromium wordt altijd bijgewerkt zodat het stabiel kan blijven en zijn taak nauwkeurig kan uitvoeren. Dit is beschikbaar voor iedereen en kan ook worden gebruikt voor het testen van nieuwe [functies] en het maken van nieuwe browsers.
Hoe je jouw site gemakkelijker kunt laten "crawlen"
Nu we weten waarmee we werken, laten we werken aan het [makkelijk] [doorzoekbaar] maken van je website.
Hier zijn enkele tips en trucs om van je website een crawler-magneet te maken en naar de top van de zoekresultatenpagina te stijgen.
Interne Links
Interne links kunnen je beste vriend zijn voor [crawlen]. Je site is mogelijk al eerder gecrawld door Google, maar onlangs heb je misschien meer pagina's toegevoegd. Als de [crawler] je website al kent, zal deze zich alleen op de hoofdpagina's richten.
Vergeet niet dat Google niet wordt gewaarschuwd elke keer als er een nieuwe pagina wordt gemaakt, het kruipt om die pagina's te vinden.
Het gebruik van interne links op hoofdpagina's leidt de crawler naar waar hij moet gaan. De beste plaats voor deze interne links is je homepage, het is de pagina die de meeste [verkeer] ontvangt en waar de crawler als eerste zal scannen.
Backlinks
Backlinks zijn een andere geweldige manier om je site te laten [crawlen]. Deze methode kan worden gebruikt om je website aan de crawler te “promoten”.
Linken naar een meer populaire website zal je kansen vergroten om ontdekt te worden door de "crawler".
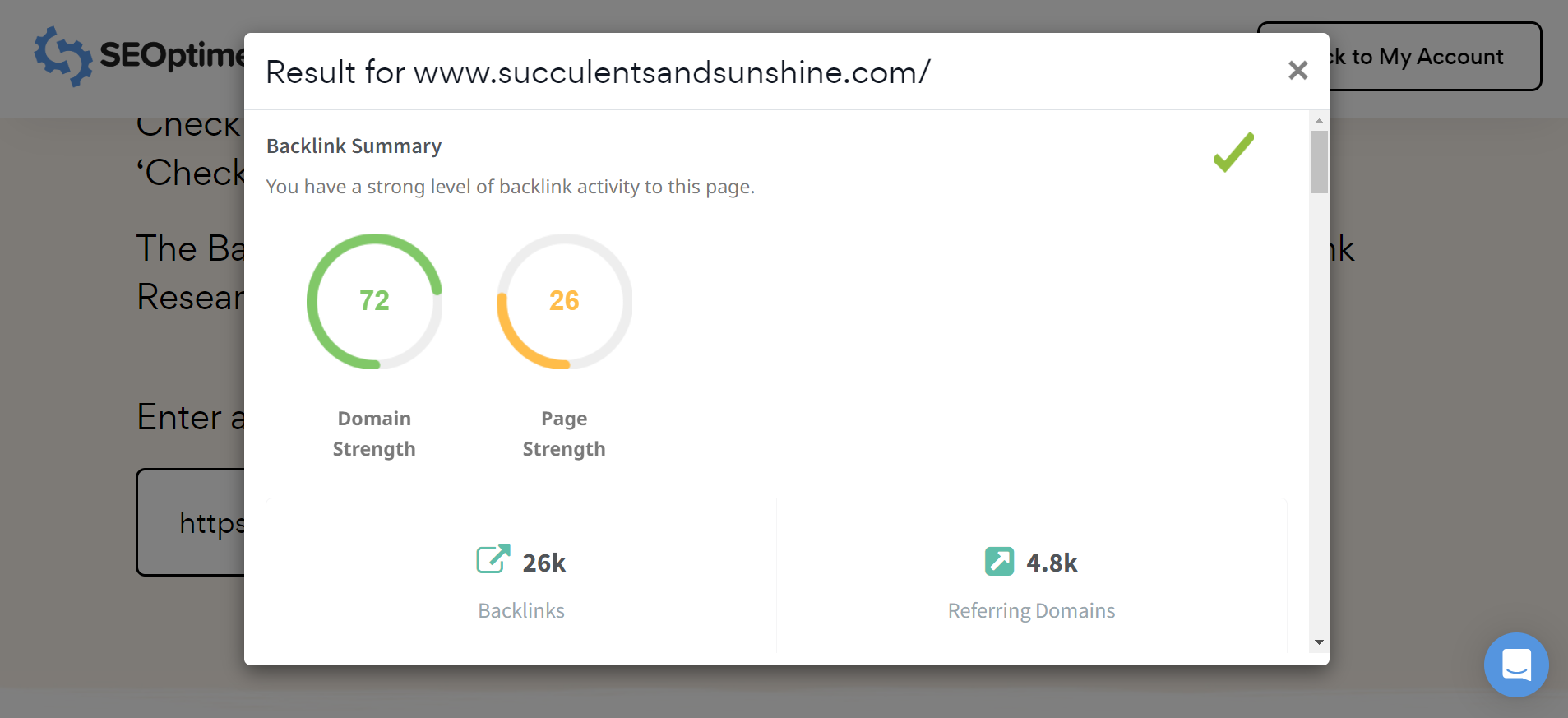
Opmerking: Je kunt eenvoudig het backlinkprofiel van elke site, inclusief dat van je concurrenten, controleren met behulp van SEOptimer's gratis [hulpmiddel] voor [backlinkonderzoek].
Afbeeldingen
Afbeeldingen kunnen worden gecrawld, in feite is er een specifieke crawler alleen voor afbeeldingen. Deze crawler staat bekend als Googlebot Image, en hij verzamelt afbeeldingen voor de database.
Sitemaps
Er is een manier om Google te vertellen welke pagina's je wilt dat ze directer crawlen. Je kunt een sitemap indienen met een gedetailleerde lijst van de pagina's die je door Google wilt laten crawlen.
Gebruik onze XML Sitemap Generator om een [sitemap] van uw gehele website te maken. Maak het, benoem het. En download het naar uw computer om het te uploaden naar Google Search Console.
Klikdiepte
Klikdiepte (ook bekend als crawldiepte) laat zien hoeveel werk een crawler zou moeten doen om je pagina te bereiken en te scannen. Je wilt nooit dat de crawler te veel werk moet doen, je wilt dat je pagina of website zo vriendelijk mogelijk is voor crawlers.
Het zou ongeveer drie klikken of minder moeten kosten, hoe meer het kost, hoe meer het de crawler vertraagt.
Een goede structuur moet je in staat stellen om nieuwe pagina's toe te voegen zonder je klikdiepte te beïnvloeden. De crawler moet ook gemakkelijk deze pagina's kunnen bereiken.
FYI: Een goede vuistregel is om ervoor te zorgen dat je vanaf een pagina op je site naar elke andere pagina op je site kunt navigeren met niet meer dan 3 klikken. Dit zorgt ervoor dat Google al je pagina's efficiënt kan vinden en indexeren. Bovendien is het geweldig voor de [gebruikerservaring].
Indexeringsinstructies
Er zijn instructies die Google volgt bij het crawlen en ideatiepagina's. Robots.txt, noindex-tag, robots-metatag en X-Robots-Tag. Maak je geen zorgen, we [zullen] dit voor je [opdelen].
Robots.txt. is een rootdirectorybestand dat bepaalde pagina's en inhoud van Google [weert]. Wanneer de crawler een pagina aan het [scannen] is, zal deze hiernaar kijken voor informatie. Als de crawler deze informatie niet kan vinden, zal het [crawlen] stoppen en zal de pagina geen deel uitmaken van de [zoekresultaten].
De noindex-tag voorkomt dat alle soorten crawlers een pagina kunnen scannen en indexeren.
Robots meta tag, kan helpen bij het controleren van de manier waarop een pagina verondersteld wordt geïndexeerd en geladen te worden voor websurfers in de zoekresultaten.
X-Robots-Tag, is een onderdeel van de HTTP-header en zal helpen het gedrag van de crawler te controleren. Het houdt toezicht op hoe de gehele pagina wordt geïndexeerd. Je kunt afbeeldingen en video's op een pagina blokkeren met deze methode. Je kunt ook afzonderlijke crawlersoorten targeten, maar alleen als het is gespecificeerd.
Als het type crawler niet is gespecificeerd, dan zullen de instructies voor alle Google-crawlers zijn.
URL-structuur
Misschien heb je deze al eerder gehoord, maar zorg ervoor dat je een gebruiksvriendelijke URL hebt.

Een URL die gemakkelijk is, een die zowel je consumenten als algoritmen zullen waarderen. Probeer je URL zo kort en krachtig mogelijk te houden.
Als je een lange URL hebt, kan dit niet alleen verwarrend zijn voor het menselijk oog, maar ook voor de Google-bot.
Hoe meer verward de Googlebot, hoe meer het zijn crawlbronnen zal uitputten en dat is zeker niet wat je wilt.
Veelvoorkomende "problemen" (en "oplossingen") met "Google Crawling"
Dus, je hebt een pagina maar deze presteert niet zoals je wilt. Dit kan komen doordat de crawler problemen heeft met het [scannen] en [indexeren] van je site.
Hier zijn een paar veelvoorkomende problemen die mensen zijn tegengekomen met Google Crawling.
1. Google [crawlt] jouw [website] niet
Zorg ervoor dat je controleert of je pagina of site "crawl vriendelijk" is. Dat betekent dat je een goede URL hebt, de interne en "backlinks" opneemt indien nodig, of de tijd neemt om een "sitemap" te maken om Googlebot te laten zien waar te kruipen.
Houd er ook rekening mee dat het enige tijd kan duren voordat Google uw website crawlt en indexeert, omdat het u moet komen vinden!
2. Je bent verwijderd uit Google's index
Google zal een website verwijderen als het daar de noodzaak toe voelt, of dat nu wettelijk is, relevantie betreft of vanwege het niet naleven van de richtlijnen. Gebruik onze SEO Crawler om te controleren op alles wat de crawler van uw pagina zou kunnen blokkeren.
Zodra je dat hebt gedaan, kun je je website ter "heroverweging" aan Google "voorleggen" via reconsideration.
3. Je hebt [dubbele] [inhoud]
"Duplicate content" is een pagina die [vergelijkbare] inhoud heeft als een andere pagina of meerdere URL's die naar één pagina linken.

In het geval van pagina's met vergelijkbare inhoud, wat ook kan betekenen dat je een desktop- en mobiele versie van één pagina hebt. Echter, het meest voorkomende voorbeeld van dubbele inhoud op een aantal pagina's.
Deze kunnen zowel worden vermeden als opgelost met een canonieke URL, of URL die dient als vertegenwoordiger voor deze dubbele pagina's.
Google zal alleen de pagina tonen waarvan zij geloven dat deze de meest nuttige inhoud bevat en zullen deze als canoniek labelen. Dit is de pagina die gecrawld zal worden in plaats van de duplicaten.
Om dit te voorkomen, overweeg om de tekst op deze pagina's [te herschrijven] zodat ze niet worden verward als duplicaten.
4. Er zijn "weergaveproblemen"
Als je weergaveproblemen hebt, zorg ervoor dat je codering niet te groot is. Je codering moet zo schoon mogelijk zijn zodat de crawler alles goed kan weergeven.
Als de crawler de pagina niet kan weergeven, wordt deze als leeg beschouwd.
Google Crawler Veelgestelde Vragen
Hoe lang duurt het voordat Google een website crawlt?
Normaal gesproken duurt het voor Google enkele dagen tot weken om te crawlen. U kunt het crawlen monitoren met behulp van het "Index Status Report" of de "URL inspection tool". Vergeet niet, Google wordt niet op de hoogte gebracht wanneer een nieuwe website of pagina is gemaakt, het moet deze crawlen en vinden.
FYI: Meer populaire sites worden sneller gecrawld. Gloednieuwe sites hebben meestal weken nodig om te crawlen, terwijl gerenommeerde sites zoals NY Times, Wall Street Journal en Wikipedia meerdere keren per dag worden gecrawld.
Wat is het Google Crawler-algoritme?
Het Google Crawler-algoritme is gebaseerd op hoe crawler-vriendelijk uw site is. Dit omvat "trefwoorden", URL's, [inhoud] en informatie, codering, en nog veel meer. Het is aan u om Google de beste [inhoud] en begeleiding te bieden zodat het uw pagina kan vinden en beginnen met crawlen.
[Zijn] alle pagina's beschikbaar voor crawling?
Dit is een goede vraag. Het korte antwoord is nee. Sommige pagina's kunnen niet worden gecrawld en geïndexeerd omdat ze met een wachtwoord zijn beveiligd, specifiek van de indexinstructies zijn uitgesloten, of geen links op hun pagina's hebben.
Wanneer zal mijn website in Google zoekresultaten verschijnen?
Dit zal altijd variëren afhankelijk van hoe lang het duurt voordat je website wordt gecrawld en geïndexeerd. Dit kan slechts een paar dagen duren of zo lang als een paar weken.
Welke andere "web crawlers" zijn er?
Ja! Er zijn tal van webcrawlers buiten de vijftien van Google. Hier zijn er een paar ter referentie:
- Er is BingBot die gebruikt wordt door de zoekmachine Bing.
- SlurpBot, gebruikt door Yahoo! Deze webcrawler is een mix tussen Yahoo! en Bing, omdat Bing voornamelijk Yahoo! aandrijft.
- ExaBot is de meest populaire zoekmachine en crawler in Frankrijk.
- AppleBot wordt gebruikt door de grote tech Apple voor [spotlight search] en [Siri suggestions].
- Facebook, geloof het of niet, gebruikt links om inhoud naar andere profielen te sturen en kan alleen crawlen als er een link wordt gegeven.
Optimaliseer Uw Site voor Google Crawling
Nu je de basis van Google Crawling begrijpt en weet hoe het werkt, gebruik het in je voordeel! Laat je website correct indexeren en klim naar de top van de [zoekresultaten] [homepage]. Het is gratis en volledig tot je beschikking.