
Googleを使ってサービスを検索したり、情報を見つけたりする時のことを知っていますか?ページが読み込まれると、常に一番上にあるウェブサイトがあります。
Google検索エンジンの結果ページ(SERP)で1位に位置するサイトは、すべてのクリックの大部分を獲得します。したがって、SEOのベストプラクティスに従って、サイトのSERPでの位置を最大化しようとすることが重要です。
しかし、Googleが最初にあなたのサイトをどのように見つけるか知っていますか?
答えはGoogleのクローラーです。Googleのクローラーは、ウェブサイトを訪問し、そのサイトに関する情報を収集する小さなデジタルロボットのようなものです。
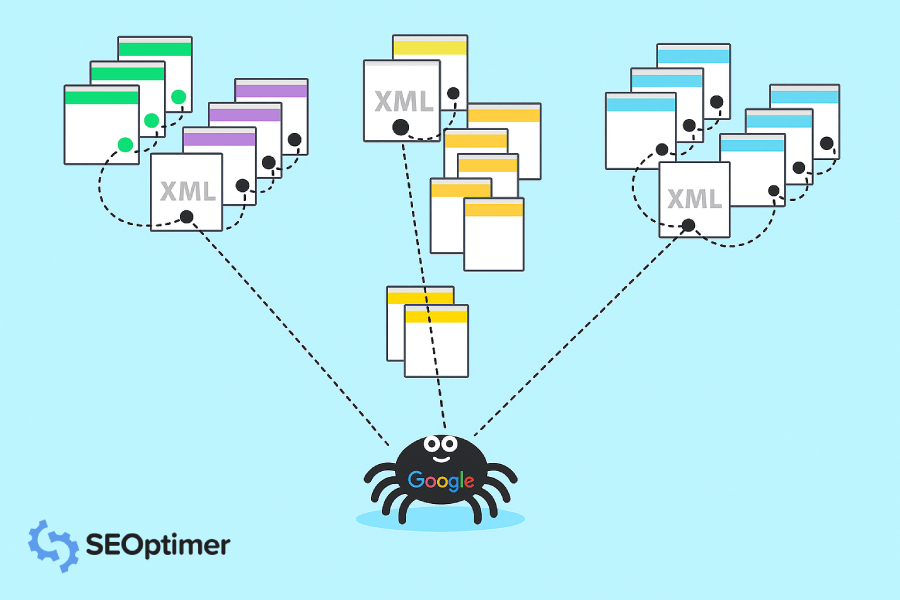
その後、Googleはそれらすべての情報をインデックスし、それを使用して検索アルゴリズムを改善します。誰かがGoogleにクエリを入力すると、検索アルゴリズムはインデックスされたすべての情報を調べ、その人のクエリに対する最良の結果を見つけます。
そして、それがGoogleがインターネットで何かを検索したときに最高の結果を提供できる方法です!
Google クローラーとは何ですか?
Google Crawler は “ロボット” または “スパイダー”(わかりますよね、クロールするから)とも呼ばれ、データベースに保存する新しい情報を探してウェブサイトからウェブサイトへと移動します。Google が使用している15種類のクローラーがありますが、最も重要なのは Googlebot です。

Googleは強力ですが、すべてを行うことはできません。新しいウェブページが作成されるたびに、そのページがクロールされるまでGoogleはそのページについて知りません。
Googleは、Googlebotを使用して常に最新の情報を取得し、そのデータベースに保存しています。
Google [インデックス] vs Google [クロール]
インデックス作成は、GoogleBotによってウェブサイトがクロールされた後にのみ行われます。クロールされると、そのサイトまたはページからスキャンされた情報がスキャンされ、Googleインデックスに保存されます。
インデックスは、検索結果でページを[適切に]分類し、ランク付けします。
なぜGoogleクローラーが重要なのか?
では、なぜこれがすべて重要なのでしょうか?
さて、あなたがビジネスを運営していてウェブサイトを持っているとしましょう。あなたのウェブサイトをできるだけ上位にしたいと思うでしょう。もしあなたのウェブサイトがクロールされずにスキャンされなければ、検索ページに表示されません。
インターネット上に何の存在感もないと、[あなたの]オーディエンスや消費者にリーチすることはできません。クロールとインデックス作成によって、ウェブサイトが多少注目を集めるのが少し簡単になります。
Googleクローラーの[仕組み]
つまり、それが何であるかは知っているが、どのように機能するのだろうか?Googleは強力ではあるが、すべてを行うことはできない。新しいウェブページが作成されるたびに、そのページがクロールされるまでGoogleはそれについて知らない。GoogleはGooglebotを使用して常に追加情報を取得し、自社のデータベースに保存している。
ウェブページがクロールまたはスキャンされると、そのページはレンダリングされ、HTML、CSS、JavaScript、およびサードパーティコードが提供されます。これらはすべてGooglebotがウェブサイトをインデックスしランク付けするために必要です。最大のクローラーであるGooglebotは、Chromiumを使用してすべてのウェブページやウェブサイトを表示およびレンダリングすることができます。
Chromiumは常に更新されており、安定性を保ち、その機能を正確に果たすことができます。これは誰でも利用可能で、新しい機能のテストや新しいブラウザの作成にも使用できます。
あなたのサイトをクロールしやすくする方法
何を扱っているかがわかったので、あなたのウェブサイトがクロールされやすくするために取り組みましょう。
あなたのウェブサイトをクローラーマグネットにし、検索結果ページのトップに上昇させるためのいくつかの「ヒント」と「コツ」を紹介します。
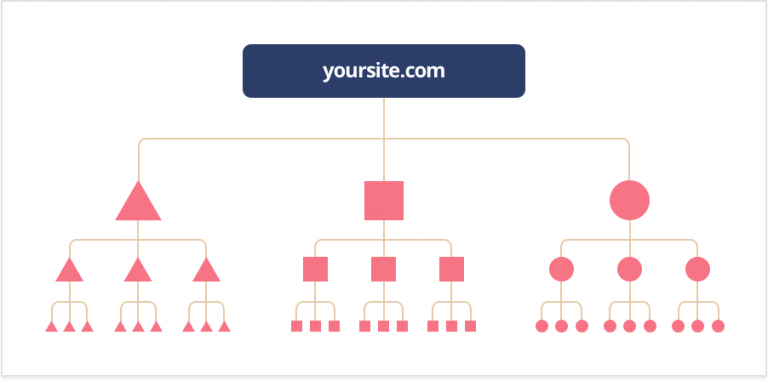
内部リンク
内部リンクはクロールにおいて最良の味方となる可能性があります。あなたのサイトは過去にGoogleによってすでにクロールされているかもしれませんが、最近より多くのページを追加したかもしれません。クローラーがすでにあなたのウェブサイトを知っている場合、主要なページのみに焦点を当てます。
覚えておいてください、Googleは新しいページが作成されるたびに通知されるわけではなく、それらのページを見つけるためにクロールします。
メインページで内部リンクを使用することで、クローラーがどこに行くべきかを指示します。これらの内部リンクに最適な場所はホームページです。それは最も多くのトラフィックを受け取るページであり、クローラーが最初にスキャンする場所です。
バックリンク
バックリンクは、サイトをクロールしてもらうためのもう一つの優れた方法です。この方法はクローラーにあなたのウェブサイトを「宣伝」するために使用できます。
より人気のあるウェブサイトへのリンクは、クローラーに発見される可能性を高めます。
[注意]: 競合他社を含む任意のサイトのバックリンクプロファイルを簡単にチェックすることができます、SEOptimer の無料 [Backlink Research] ツールを使用して。
画像
画像はクロールされることがあり、実際には画像専用のクローラーがあります。このクローラーはGooglebot Imageとして知られており、データベースのために画像を収集します。
サイトマップ
Googleにクロールしてほしいページをより直接的に伝える方法があります。Googleにクロールしてほしいページの詳細なリストを含むサイトマップを送信することができます。
私たちのXMLサイトマップジェネレーターを使用して、ウェブサイト全体のサイトマップを作成してください。作成し、名前を付けてください。そして、それをコンピュータにダウンロードしてGoogle Search Consoleにアップロードしてください。
クリック深度
"クリックの深さ"(クロールの深さとしても知られています)は、クローラーがあなたのページに到達してスキャンするためにどれだけの作業をしなければならないかを示します。クローラーにあまりにも多くの作業をさせたくはありません。あなたのページやウェブサイトは可能な限りクローラーフレンドリーであるべきです。
それは約3クリック以内であるべきです、それにかかるほどクローラーが遅くなります。
良い構造は、新しいページを追加してもクリック深度に影響を与えないようにする必要があります。クローラーもこれらのページに簡単に到達できる必要があります。
FYI: 良い経験則として、サイト内のページから他のページに3クリック以内で移動できることを確認することが挙げられます。これにより、Googleはすべてのページを効率的に見つけてインデックス化することができます。さらに、ユーザーエクスペリエンスにも優れています。
索引の指示
Googleがクロールしてアイデアページを処理する際に従う指示があります。Robots.txt、noindexタグ、robotsメタタグ、およびX-Robots-Tagです。心配しないでください、これを分かりやすく説明します。
Robots.txtは、特定のページやコンテンツをGoogleから除外するルートディレクトリファイルです。クローラーがページをスキャンしているとき、この情報を確認します。もしクローラーがこの情報を見つけられない場合、クロールを停止し、そのページは検索結果に含まれません。
noindexタグは、すべての種類のクローラーがページをスキャンおよびインデックスすることを防ぎます。
ロボットメタタグは、ページが検索結果でウェブサーファーにどのようにインデックスされ読み込まれるべきかを制御するのに役立ちます。
X-Robots-Tagは、HTTPヘッダーの一部であり、クローラーの動作を制御するのに役立ちます。これは、ページ全体がどのようにインデックスされるかを監督します。この方法を使用して、ページ上の画像や動画をブロックできます。また、クローラーのタイプを個別にターゲットにすることもできますが、それは指定されている場合のみです。
クローラーのタイプが指定されていない場合、指示はすべてのGoogleクローラーに対するものとなります。
URL構造
これは以前に聞いたことがあるかもしれませんが、"ユーザーフレンドリーなURL"を持っていることを確認してください。

URLは「簡単」で、消費者とアルゴリズムの両方に愛されるものです。URLをできるだけ「短く」そして「魅力的」に保つようにしてください。
長いURLがある場合、人間の目だけでなく、Googleボットにとっても混乱を招く可能性があります。
Googlebotが「より混乱」すると、それだけクロールリソースを消耗し、「それは間違いなく望ましくないことです」。
Google クロールに関する一般的な問題(および解決策)
つまり、あなたはページを持っていますが、それが期待通りに機能していません。これは、クローラーがサイトをスキャンおよびインデックス化するのに苦労しているためかもしれません。
こちらは、Google Crawlingで人々が直面した一般的な問題のいくつかです。
1. Googleはあなたのウェブサイトをクロールしていない
ページまたはサイトがクローラーに優しいかどうかを確認することを忘れないでください。これは、良いURLを持ち、必要に応じて内部リンクとバックリンクを組み込むか、Googlebotがクロールする場所を示すサイトマップを作成する時間を取ることを意味します。
また、Googleがあなたのウェブサイトをクロールしてインデックスするには時間がかかる場合があることに注意してください。それはあなたを見つけに来なければならないからです!
2. あなたはGoogleのインデックスから「削除されました」
Googleは、法律、関連性、またはガイドラインに従っていない場合に必要に応じてウェブサイトを削除します。SEOクローラーを使用して、クローラーがあなたのページをブロックしている可能性のあるものを確認してください。
それが完了したら、Googleにあなたのウェブサイトを再審査に提出することができます。
3. [重複]コンテンツがあります
重複コンテンツとは、別のページと類似したコンテンツを持つページや、1つのページにリンクする複数のURLのことです。

類似のコンテンツを持つページがある場合、それはデスクトップ版とモバイル版のページを持っていることを意味することもあります。しかし、多くのページで重複コンテンツの最も一般的な例です。
これらの両方を避けたり修正したりするには、正規URL、またはこれらの重複ページの代表となるURLを使用します。
Googleは、最も有用なコンテンツがあると信じるページのみを表示し、それにカノニカルのラベルを付けます。これが重複ではなくクロールされるページです。
これを避けるために、これらのページのテキストを「重複」として混同されないように書き直すことを検討してください。
4. [レンダリング]の[問題]があります
もしレンダリングの問題がある場合は、コーディングが大きすぎないことを確認してください。クローラーがすべてを適切にレンダリングできるように、コーディングはできるだけクリーンである必要があります。
クローラーがページをレンダリングできない場合、[それ]は空と見なされます。
Google クローラーに関するよくある質問
Googleがウェブサイトをクロールするのにどれくらい時間がかかりますか?
通常、Googleがクロールするには数日から数週間かかります。クロールの監視には、[Index Status Report]または[URL inspection tool]を使用できます。覚えておいてください、新しいウェブサイトやページが作成されるたびにGoogleに通知されるわけではなく、クロールして見つける必要があります。
FYI: より人気のあるサイトはより早くクロールされます。新しいサイトは通常、クロールに数週間かかりますが、NY Times、Wall Street Journal、Wikipediaのような信頼できるサイトは1日に何度もクロールされます。
Google Crawler アルゴリズムとは何ですか?
Google Crawlerアルゴリズムは、サイトがクローラーフレンドリーであるかどうかに基づいています。これには、キーワード、URL、コンテンツと情報、コーディングなどが含まれます。Googleがあなたのページを見つけてクロールを開始できるようにするためには、最良のコンテンツとガイダンスを提供することがあなたの役割です。
すべてのページはクロール可能ですか?
これは良い質問です。 短い答えはいいえです。 一部のページは、パスワードで保護されている、インデックス指示から特に除外されている、またはページにリンクがないため、クロールおよびインデックス化できません。
私のウェブサイトはいつGoogle検索に表示されますか?
これは、あなたのウェブサイトがクロールされてインデックスされるまでにどれくらい時間がかかるかによって常に異なります。これには数日しかかからない場合もあれば、数週間かかることもあります。
他にどのようなウェブクローラーがありますか?
はい!Googleの15個以外にもたくさんのウェブクローラーがあります。以下にいくつか参考として挙げます:
- Bingの検索エンジンで使用されているBingBotがあります。
- Yahoo!が使用するSlurpBot。このウェブクローラーはYahoo!とBingのミックスで、主にBingがYahoo!を支えています。
- ExaBotはフランスで最も人気のある検索エンジンおよびクローラーです。
- AppleBotは、主要なテック企業Appleによってスポットライト検索とSiriの提案に使用されます。
- 信じられないかもしれませんが、Facebookはリンクを使ってコンテンツを他のプロフィールに送信し、リンクが提供された場合にのみクロールできます。
Google クロール用にサイトを「最適化」する
今やGoogle Crawlingの基本とその仕組みを理解したので、それを活用しましょう!あなたのウェブサイトを適切にインデックスし、検索結果のホームページのトップに上り詰めましょう。それは「無料」で完全にあなたの「自由」です。





