SEOptimerのSEOクローラーは、ウェブサイト上のページをスキャンして監査し、大規模な技術的SEOの問題を特定するのに役立ちます。
ページを一つずつ確認する代わりに、クローラーはサイトの構造をレビューし、複数のURLにわたるSEO要素を分析し、インデックス化、ユーザビリティ、または検索可視性に影響を及ぼす可能性のある問題をハイライトします。
このガイドでは、あなたは:
- [最初の]クロールを実行する
- クロール[レポートを]確認する
- [カスタムクロールルールの設定方法を]学ぶ
- ウェブサイトクロールを[スケジュールし、エクスポートする]
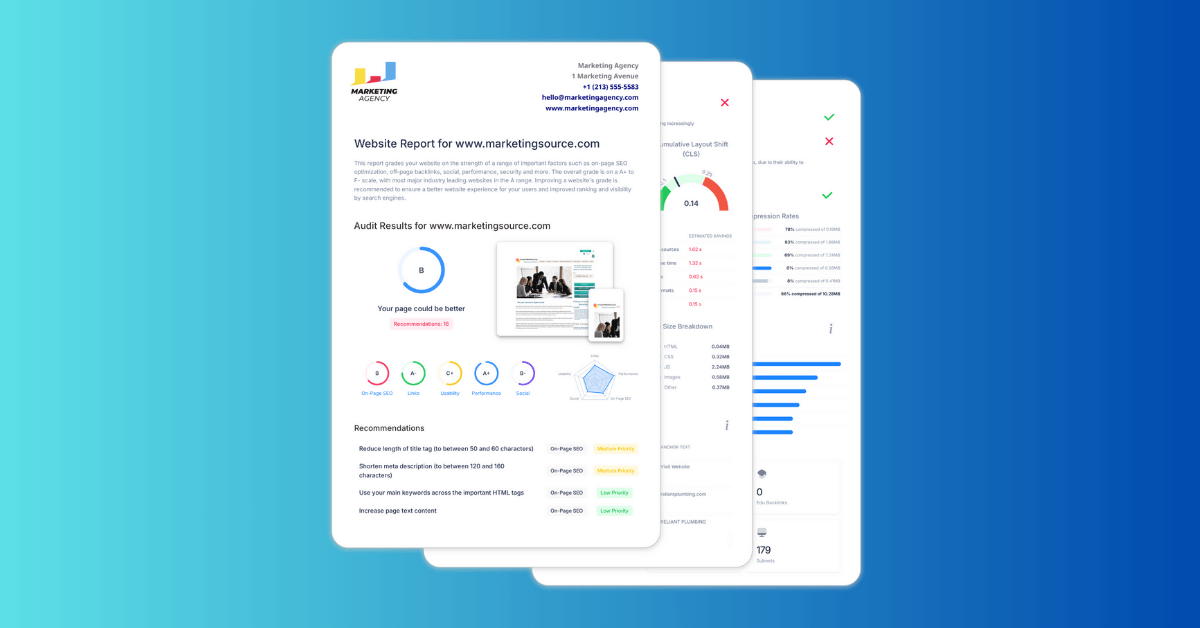
SEOptimerのSEOクローラーとは何ですか?
SEOptimerのSEOクローラーは、あなたのサイトのページをクロールし、複数のURLにわたるSEO関連の問題を特定するウェブサイトクロールツールです。
それはあなたのウェブサイトのページを訪問し、ページタイトル、メタディスクリプション、見出し、ステータスコード、インデックス可能性、リダイレクト、壊れたリンクなどの技術的およびオンページSEOデータを収集することによって機能します。
クロールが完了すると、ツールはサイト全体で見つかった問題を要約し、それらをタイプと重大度ごとにグループ化したクロールレポートを生成します。
これは、繰り返し発生する問題を見つけやすくし、特に手動でのページチェックが現実的でない大規模なウェブサイトにおいて修正の優先順位を決めるのに役立ちます。
SEO Crawlerは、技術的なSEO監査を実施し、サイトの健康状態を時間とともに監視し、主要なページがSEOのベストプラクティスに従っているかどうかを確認するのに役立ちます。
最初のクロールを実行する方法
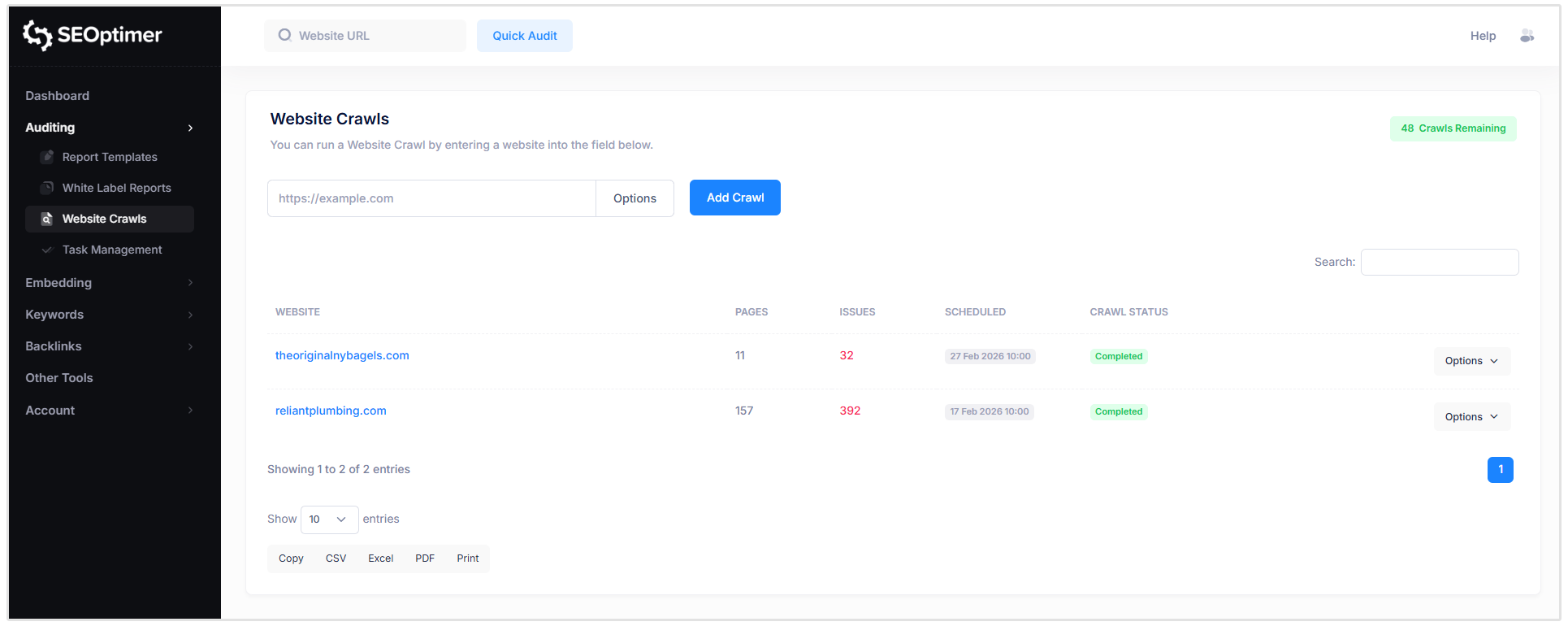
最初のクロールを実行するには、SEOptimerダッシュボードの“Auditing”の下にある“Website Crawls”オプションをクリックします。
次に、オープンフィールドにあなたのウェブサイトのURLを追加し、“[Add Crawl]をクリックします。
それで、あなたは最初のSEOptimerサイトクロールを開始しました!
私たちのSEOクローラーは、あなたのサイト上のすべてのページを「通過し」、「それらが持っているかもしれない問題」を見つけます。
クロールはリアルタイムで実行されますが、[total crawl time] は [the size of your website] とスキャンする必要のあるページ数によって異なります。
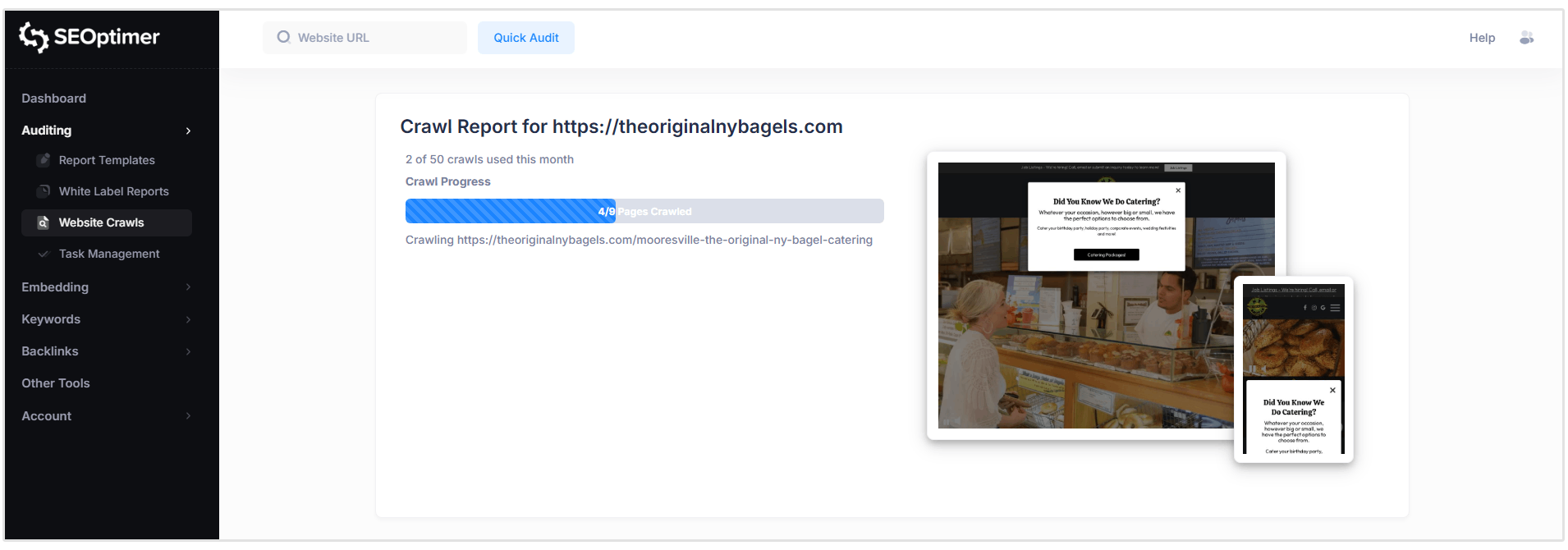
クロールがまだ実行中の間に、検出された問題をクロールレポートを開いてレビューすることができます。
各クロールレポートで[見ることができる]内容は何ですか?
私たちのツールがあなたのサイトをクロールし終えると、3つの主要なセクションが表示されます:
- レポートヘッダー
- [特定された]ページ
- [問題]概要
これらの各セクションを通して歩いてみましょう。
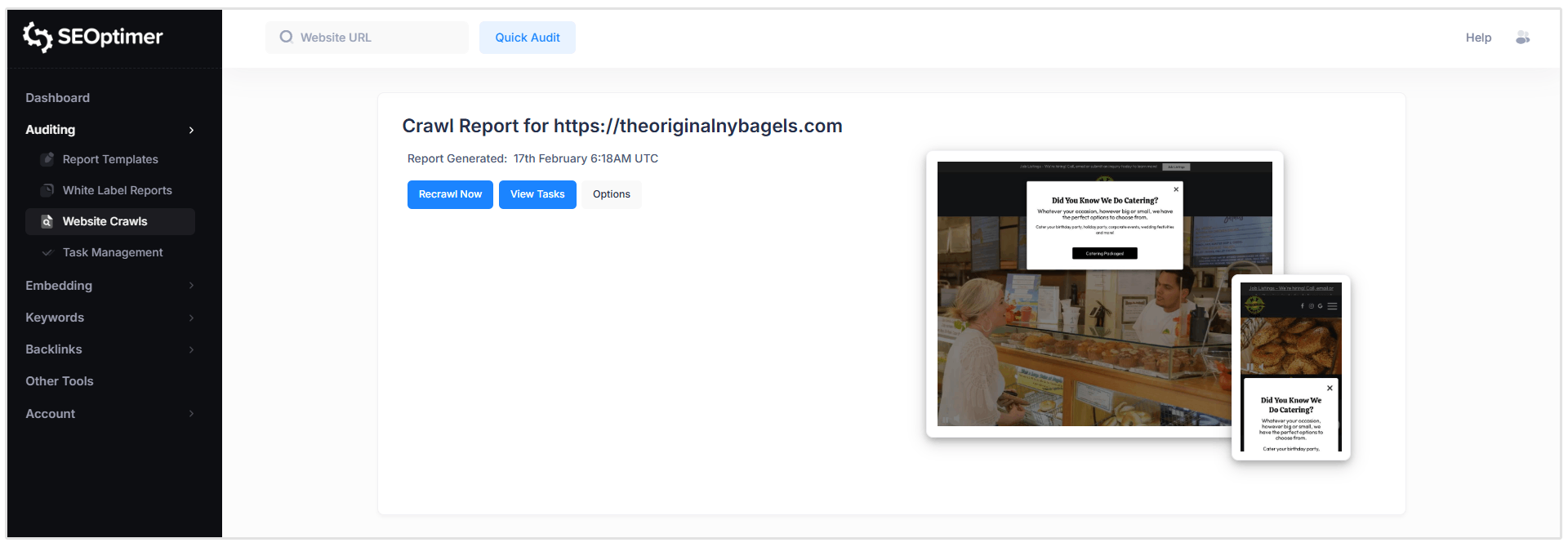
レポートヘッダー
ここでレポートが生成された日時を確認し、再クロールを要求し、タスクを表示し、クロールルールをカスタマイズできます。 (これらの機能については後ほど詳しく説明します)
識別されたページ
このセクションには、クロール中に発見されたすべてのページと、それぞれのページで検出されたSEOの[問題]を示す[表]が表示されます。
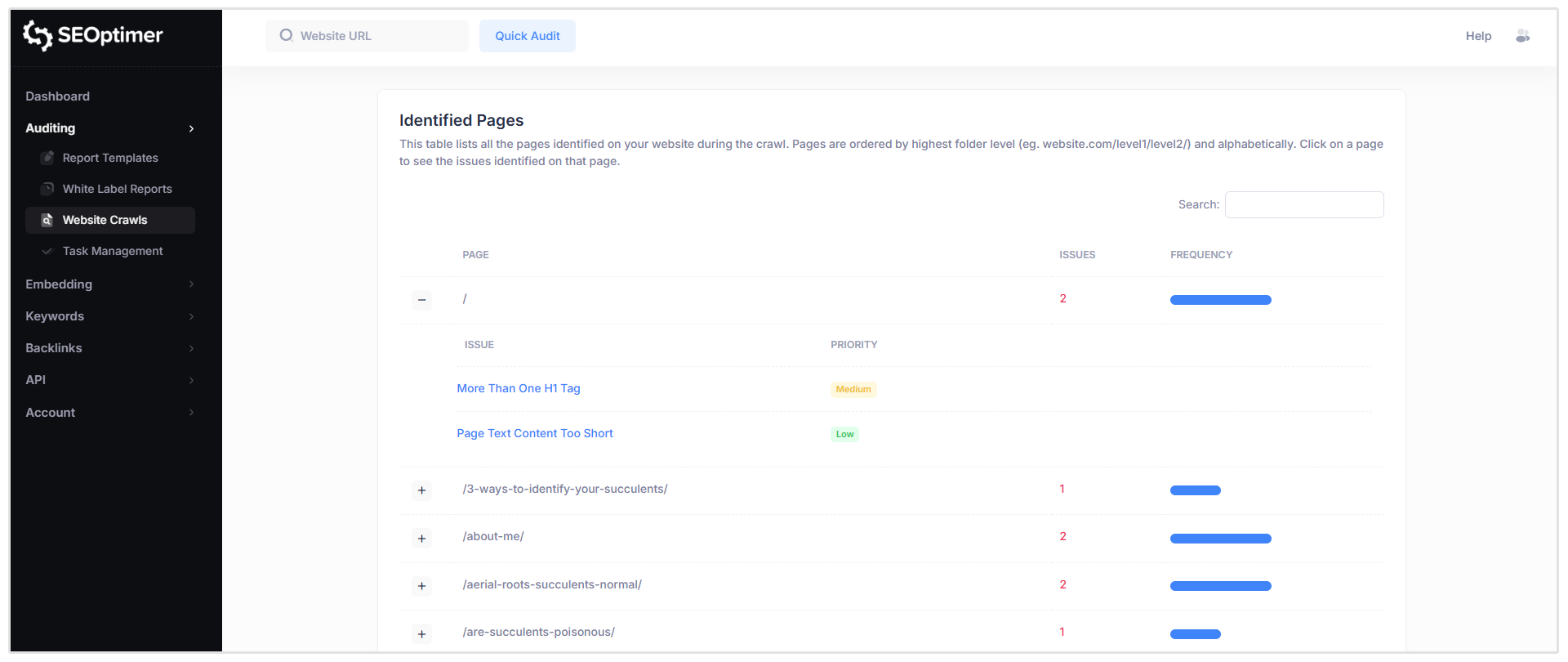
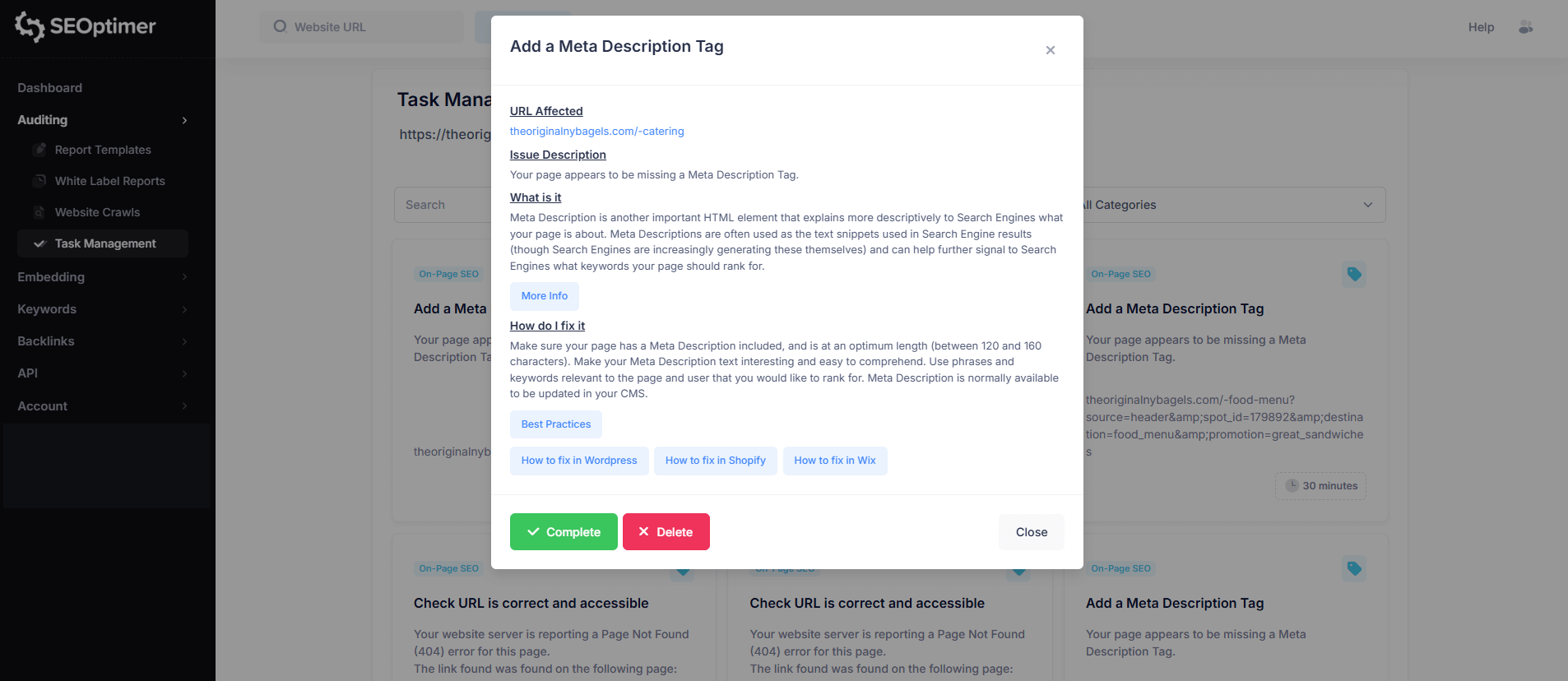
特定のページ(例えば、“/”と表示されるルートホームページパス)をクリックすると、そのURLに対してフラグが立てられたすべての[問題]のリストが表示され、それぞれの[問題]の[重大度レベル]も含まれています。
[詳細]を表示するには、リスト内の任意の[問題]をクリックしてください。
例えば、「H1タグが複数ある」を選択すると、そのページに関するその問題の詳細な内訳が表示されます。
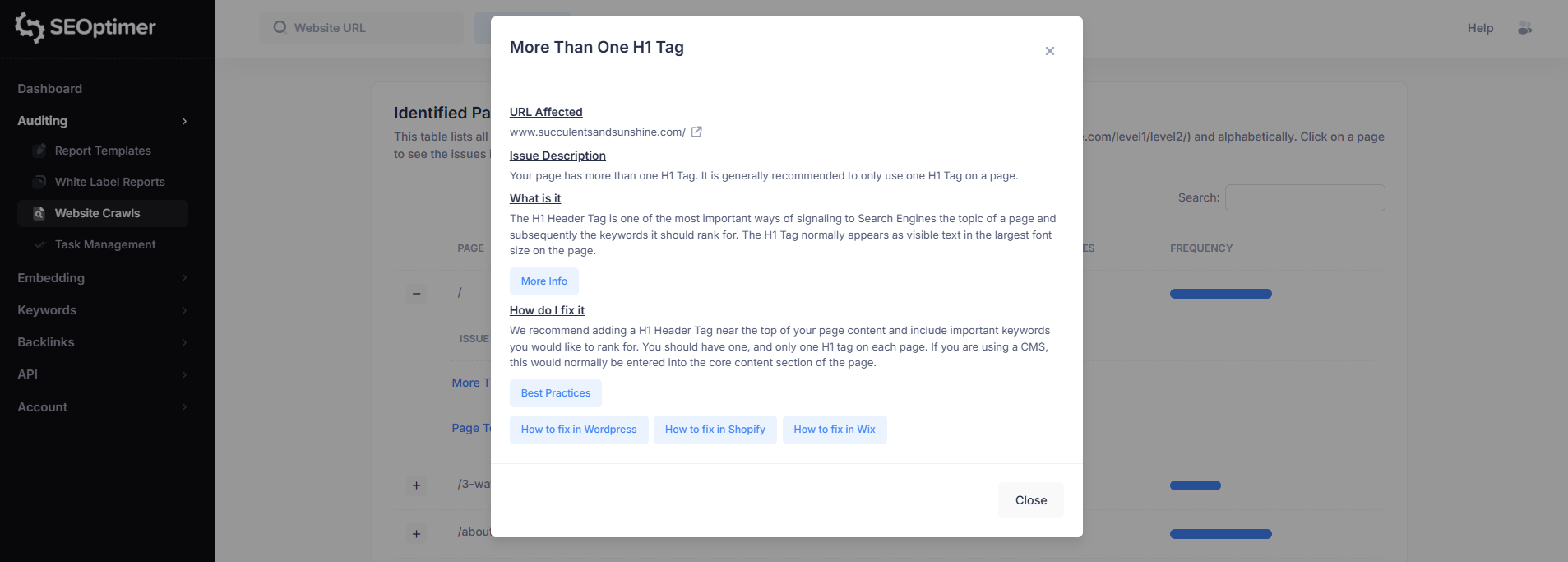
この問題ビューには以下が含まれます:
- 影響を受けたURL
- 問題の説明
- 問題の意味
- 修正方法
各問題のポップアップには、あなたのウェブサイトの問題を解決するためのサポートガイドへのリンクも含まれます。
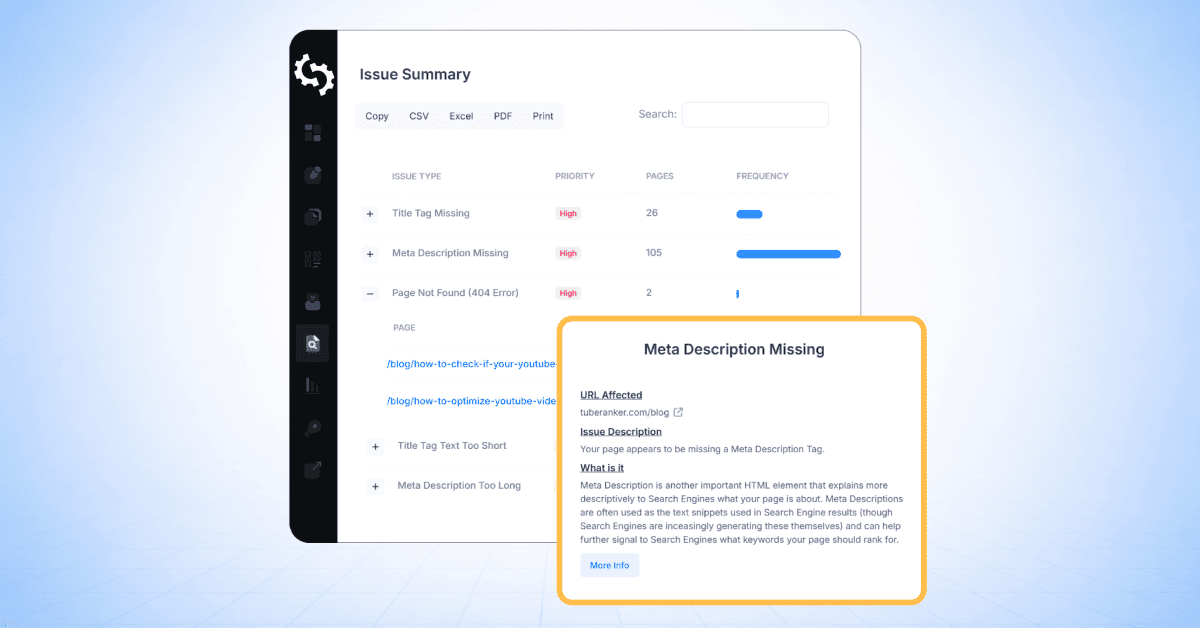
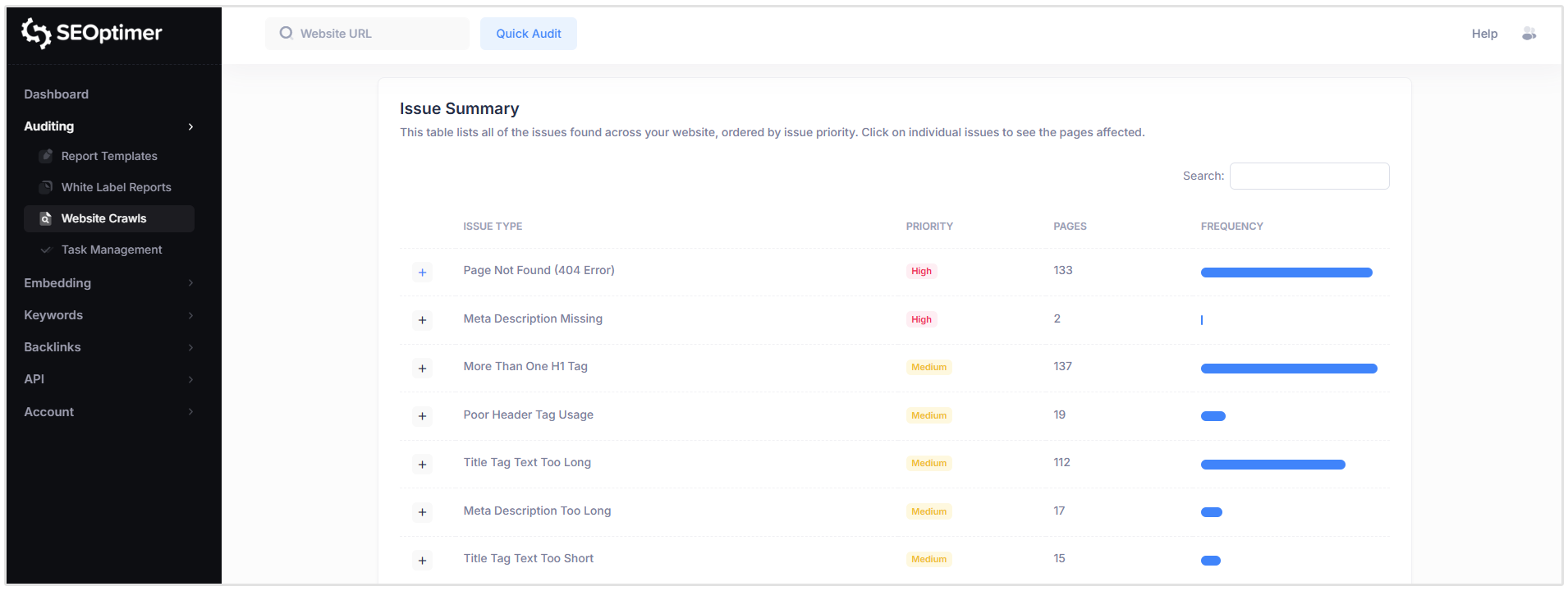
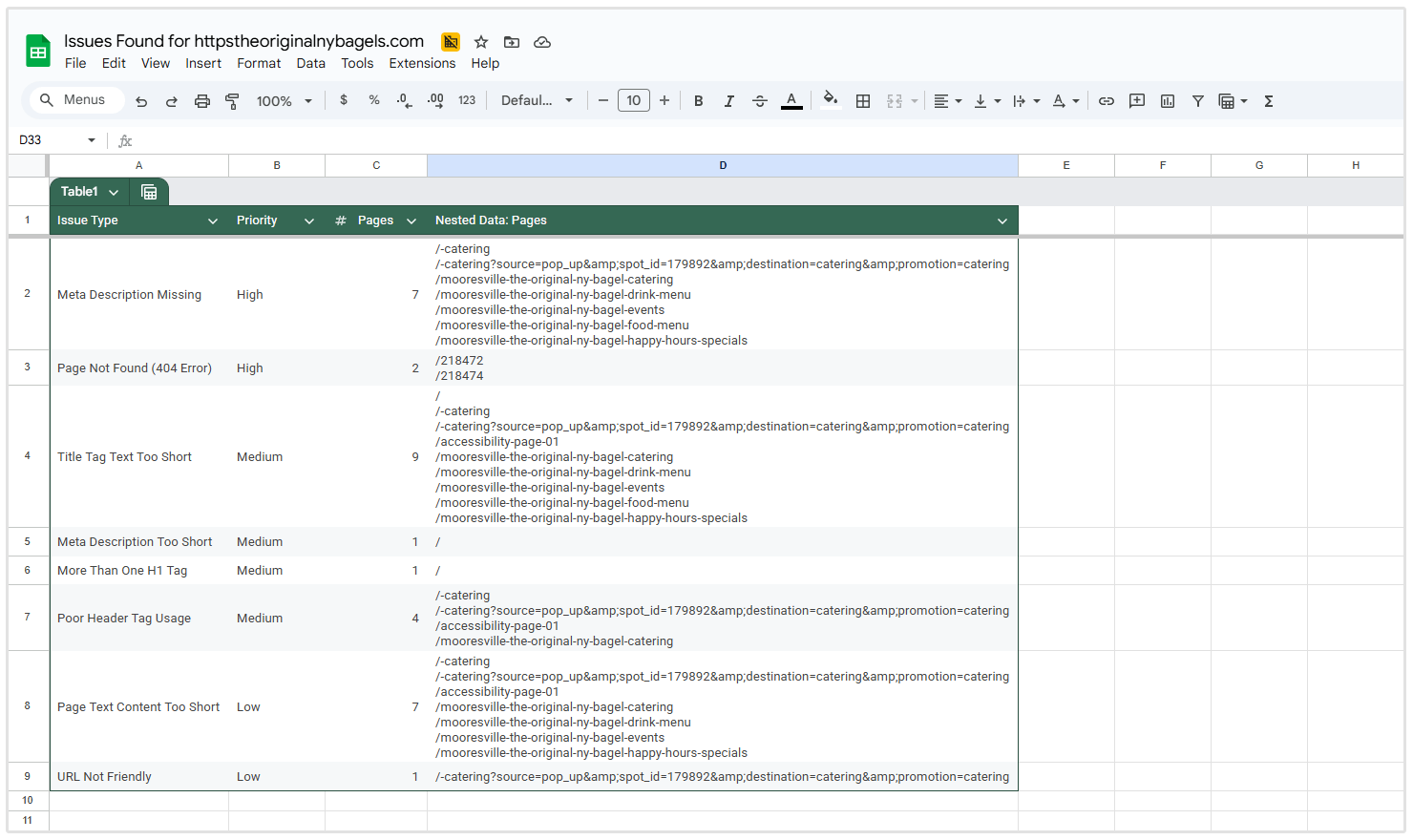
問題の概要
「問題の概要」セクションは、優先順位順に並べられた問題タイプごとにグループ化された、あなたのウェブサイト全体で検出されたすべてのSEO問題の概要を提供します。
各問題について、表には以下が示されています:
- 問題の種類
- 優先度レベル
- 影響を受けたページ数
したがって、クロールしたサイトの以下のスクリーンショットでは、H1タグが複数あるページが137ページ、404エラーがあるページが133ページ、メタディスクリプションがないページが2ページあることがわかります。
問題の概要を確認したら、クロール設定の構成と追加のSEO Crawlerオプションの検討に進むことができます。
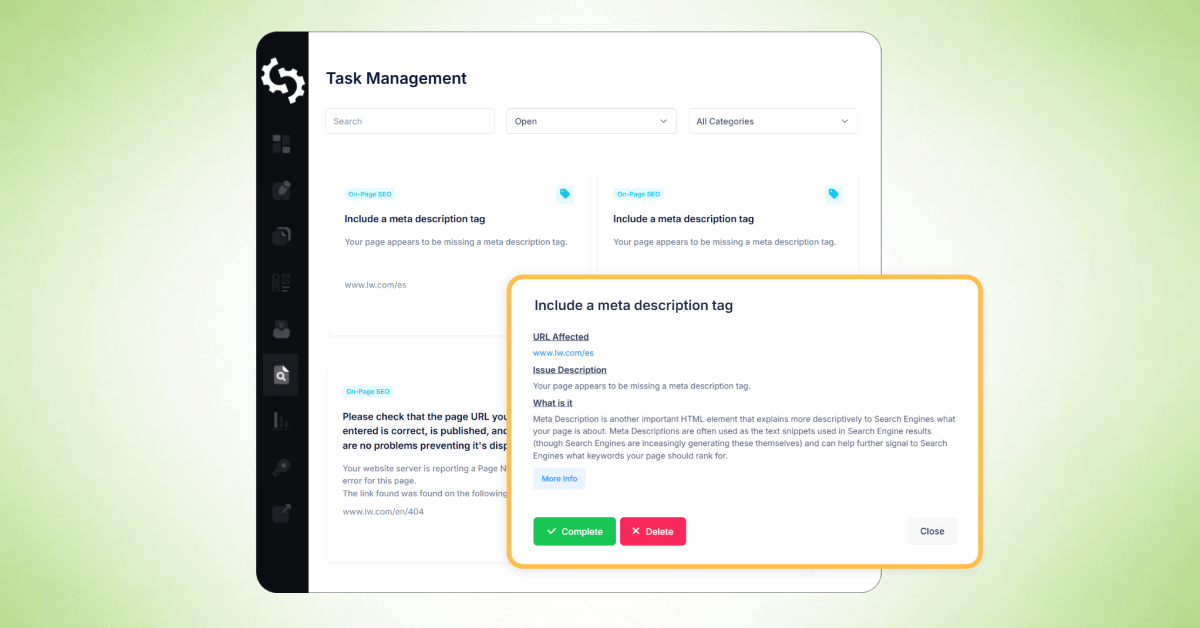
タスクを表示
ウェブサイトのクロールを完了した後、SEOptimer の「タスク管理」機能を使用して、クロールレポートで特定された問題を整理し追跡することができます。
タスク管理ツールはクロールの問題を「タスクリスト」に変換し、単一のワークスペースで作業できるようにすることで、修正の優先順位を付けたり、時間をかけて進捗状況を追跡したりすることを容易にします。
タスクリストにアクセスする方法
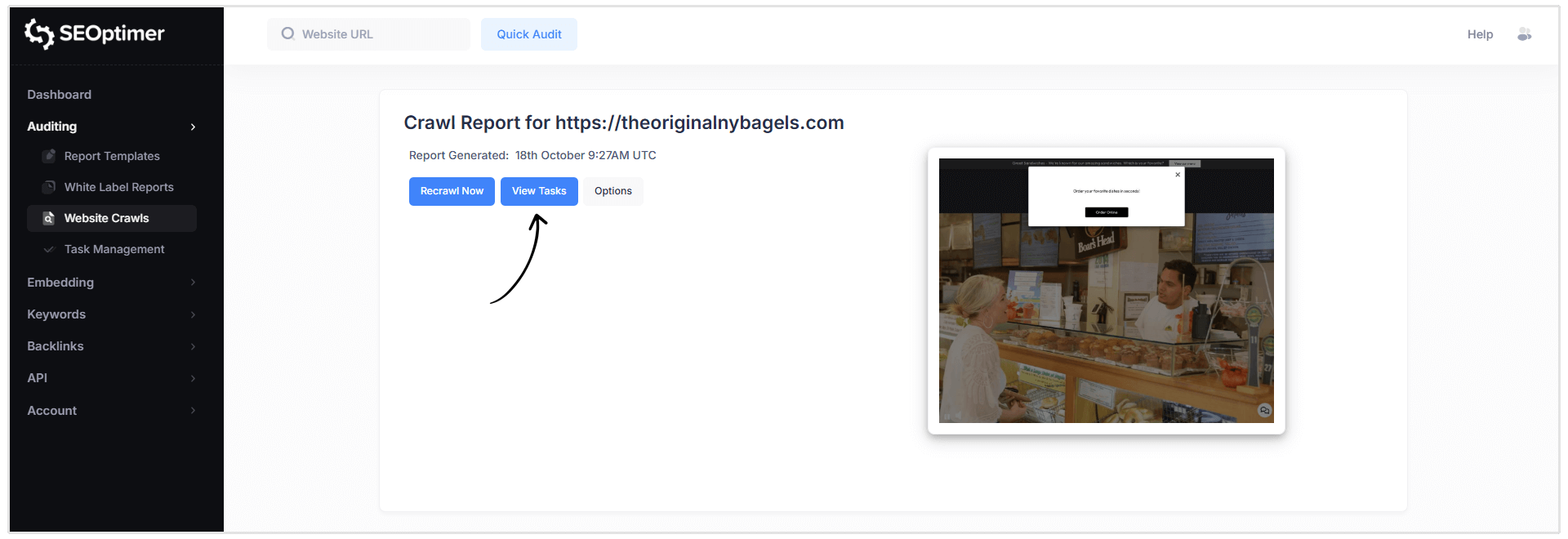
タスクリストを開く方法は2通りあります:
- Crawl Reportヘッダーの青い“タスクを表示”ボタンをクリックします。
- または、ダッシュボードの左側のナビゲーションメニューからTask Managementを選択します。
注: 複数のウェブサイトをクロールした場合、タスク管理ページの上部にあるドロップダウンメニューを使用してタスクリストを切り替えることができます。
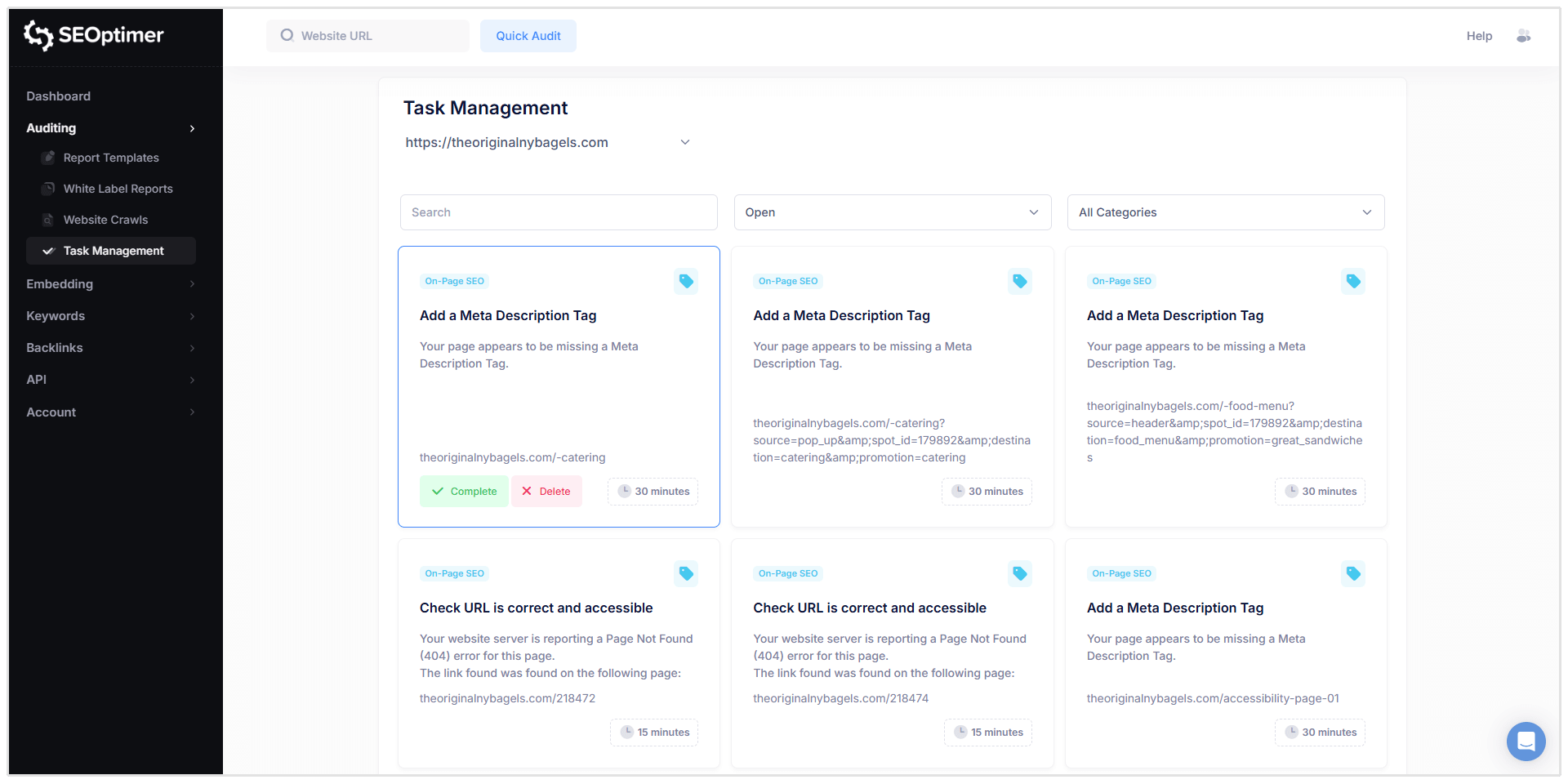
タスクの「フィルタリング」と「管理」
タスクは以下でフィルタリングできます:
- ステータス([Open]、[Completed]、[Deleted])
- カテゴリー(例:[On-Page SEO]、[Links]、など)
タスクをクリックすると、クロールレポートに類似した詳細情報が表示されます。含まれる情報は次のとおりです:
- 影響を受けるURL
- [Issue description]
- [What the issue means]
- [How to fix it]
- [Options to complete the task or delete it from the task list]
クロールをスケジュールする方法
クロールを毎週または毎月実行するようにスケジュールするオプションもあります。この機能は、複数のクライアントのウェブサイトを管理している代理店にとって特に便利です。
クロールスケジュールを設定するには、クロールをスケジュールしたいウェブサイトの右側にある“オプション”ボタンをクリックしてください。
その後、“[Schedule](スケジュール)”オプションをクリックし、自分の好みに合わせてクロールスケジュールをカスタマイズします。
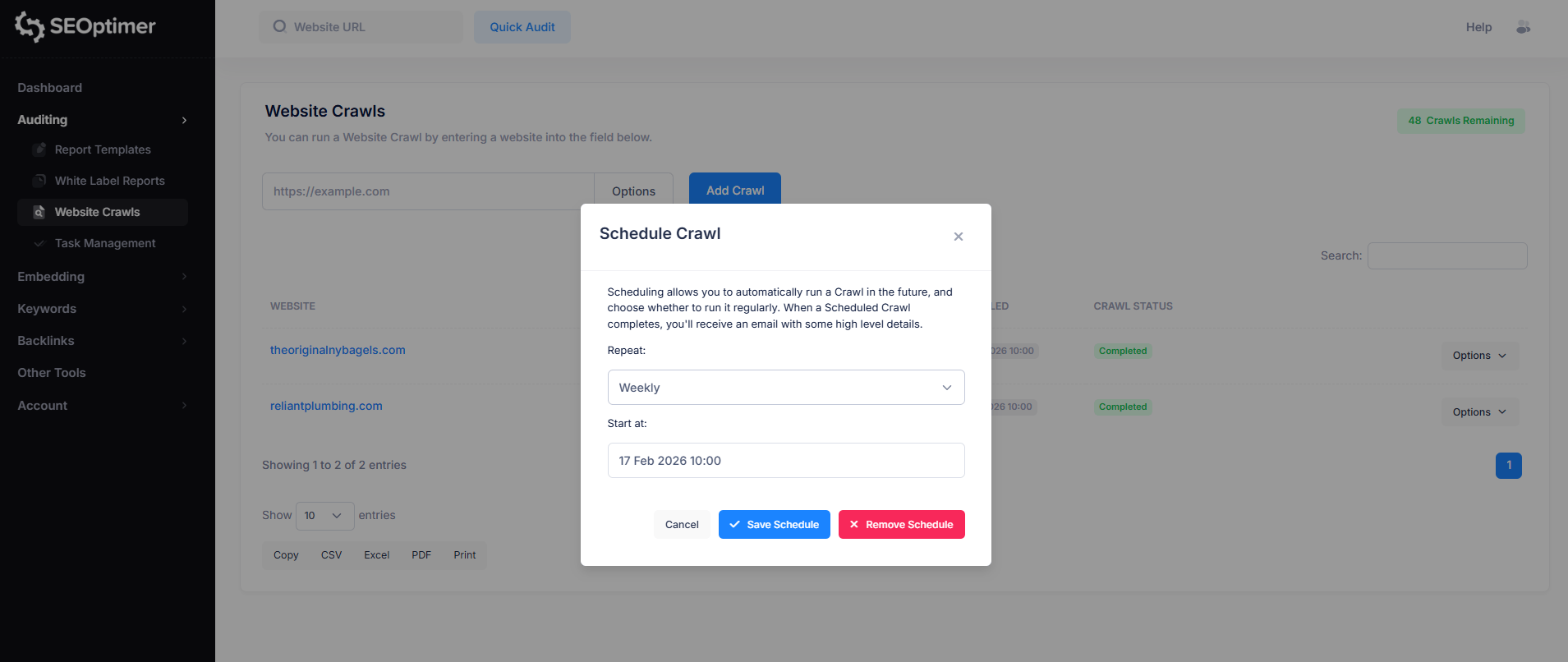
スケジュールされたクロールが完了すると、いくつかの「高レベルな詳細」と共にメールを受け取ります。
独自のクローリングルールを設定する
SEOクローラーには、クロールに含まれるページを制御するためのクロール設定オプションが含まれています。
これらの設定は、結果を制限したい場合、重複するURLを避けたい場合、またはクローラーがサイトのインデックスルールに従って動作することを保証したい場合に役立ちます。
Robots.txtの除外を"遵守する"
デフォルトでは、クローラーはサイトのrobots.txtファイルで定義されたルールに従うことができます。これにより、クローラーが[許可されていない]としてマークされたページのスキャンを避けるべきかどうかが決まります。
- 有効(推奨): クローラーはrobots.txtの除外を尊重し、ブロックされたページをスキップします。
- 無効: クローラーはrobots.txtのルールを無視し、アクセス可能なすべてのページをクロールしようとします。
ほとんどの場合、特にライブの本番サイトでクロールを実行する際には、robots.txtに従うことが推奨されます。
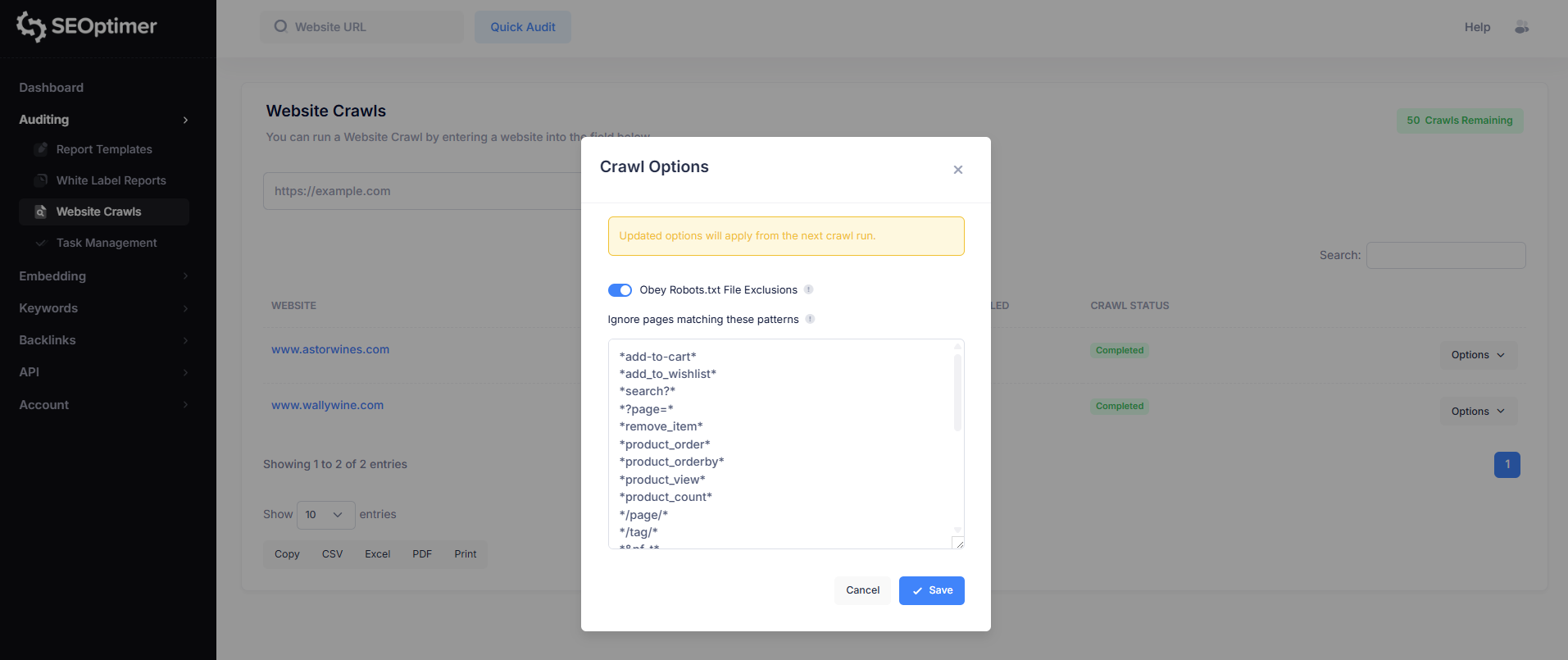
これらのパターンに一致するページを無視
一部のウェブサイトでは、URLパラメータ(たとえば、「並べ替え」、[フィルタリング]、ページネーション、またはトラッキングコード)を使用して同じページの複数のバージョンを生成します。
これは特に[ecommerce]ウェブサイトで一般的です。
“これらのパターンに一致するページを無視” オプションを使用すると、これらの重複または価値の低いURLがクロールされないようにすることができます。これにより、クロール結果をよりクリーンに保ち、問題報告の確認が容易になります。
これはより高度な機能であり、主にパラメータベースのURLが多数あるウェブサイトにとって有用です。
SEOptimerには、一般的なパラメータベースの重複をフィルタリングするためのデフォルトの除外パターンセットが含まれていますが、必要に応じて独自のルールを追加することもできます。
これらのパターンは、標準的なrobots.txtのマッチング構文に従います。
ロボット.txtのルールやURLパターンマッチングに「慣れていない」場合は、カスタムクロール除外を追加する前に基本を確認することを「お勧めします」。不正確なパターンは重要なページがクロールされるのを防ぐ可能性があります。
こちらはいくつかの便利な参考文献です:
- Robots.txt - [究極]の[ガイド]
- Robots.txtの[紹介]と[ガイド] | Google 検索セントラル
- Google が robots.txt の仕様をどのように解釈するか
- Robots.txtの「構文」
クロールデータをエクスポートする方法
SEO Crawler レポート内の各テーブルには組み込みのエクスポートオプションが含まれており、プラットフォーム外でクロール結果をダウンロードまたは共有することができます。

各テーブルの下部には、データを異なる形式で出力できるエクスポートボタンがあります:
- CSV: テーブルを.csvファイルとしてダウンロードします(スプレッドシートやデータ処理に便利です)。
- Excel: レポート作成やさらなる分析のためにテーブルをExcelファイルとしてエクスポートします。
- PDF: 共有や文書化のためにテーブルのPDFバージョンを生成します。
- Print: 印刷に適したバージョンのテーブルを開きます。
エクスポートは、表示している特定のテーブルに適用されるため、必要に応じて課題リスト、ページレポート、またはフィルタリングされた結果を簡単にダウンロードできます。
まとめ
SEOptimerのSEOクローラーは、単一のクロールでウェブサイト全体の技術的およびページ内SEOの問題を特定することを簡単にします。
クロールレポートをレビューし、組み込みのタスクリストを使用することで、クロール結果をすぐに実行可能な改善に変えることができます。
最良の結果を得るために、定期的なクロールをスケジュールして、時間の経過による変化を監視し、ウェブサイトの成長に伴う新しい問題をキャッチすることを検討してください。
助けが必要ですか?
ライブチャット: ライブチャットをクリック (右下)
メール: [email protected]
応答時間: 24時間以内