Il SEO Crawler di SEOptimer ti aiuta a eseguire la scansione e l'audit delle pagine del tuo sito web per identificare problemi tecnici di SEO su larga scala.
Invece di controllare le pagine una per una, il crawler esamina la struttura del tuo sito, analizza gli elementi SEO su più URL e evidenzia i problemi che potrebbero influire sull'indicizzazione, sull'usabilità o sulla visibilità nei motori di ricerca.
In questa guida, tu:
- Esegui la tua prima scansione
- Rivedi il rapporto di scansione
- Scopri come impostare regole di scansione personalizzate
- Pianifica ed esporta le scansioni del sito web
Cos'è il SEO Crawler di SEOptimer?
Il SEO Crawler di SEOptimer è uno strumento di scansione del sito web che analizza le pagine del tuo sito e identifica i problemi relativi alla SEO su più URL.
Funziona visitando le pagine del tuo sito web e raccogliendo dati tecnici e SEO on-page come titoli delle pagine, meta descrizioni, intestazioni, codici di stato, indicizzabilità, reindirizzamenti e collegamenti interrotti.
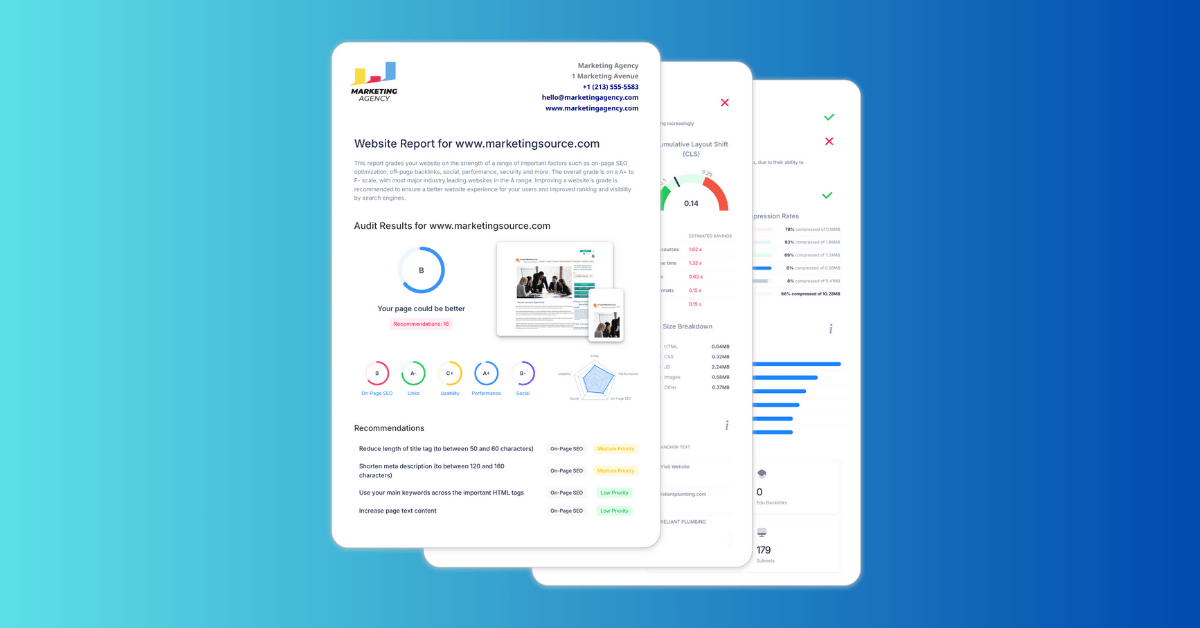
Dopo il completamento della scansione, lo strumento genera un rapporto di scansione che riassume i problemi trovati nel tuo sito e li raggruppa per tipo e gravità.
Questo rende più facile individuare i problemi ricorrenti e dare priorità alle correzioni, specialmente su siti web più grandi dove i controlli manuali delle pagine non sono pratici.
Il "SEO Crawler" è utile per eseguire audit tecnici SEO, monitorare la salute del sito nel tempo e verificare se le pagine chiave seguono le migliori pratiche SEO.
Come eseguire la tua prima "Crawl"
Per eseguire la tua prima scansione, fai clic sull'opzione “Scansioni del sito web” sotto “Auditing” nel tuo dashboard di SEOptimer.
Quindi, aggiungi l'URL del tuo sito web nel campo aperto e fai clic su “Aggiungi scansione.”
Ecco fatto, hai avviato la tua prima scansione del sito SEOptimer!
Il nostro SEO Crawler ora esaminerà tutte le pagine del tuo sito per individuare eventuali problemi che potrebbero avere.
I "crawl" vengono eseguiti in tempo reale, ma il tempo totale di scansione varierà a seconda delle dimensioni del tuo sito web e del numero di pagine che devono essere scansionate.
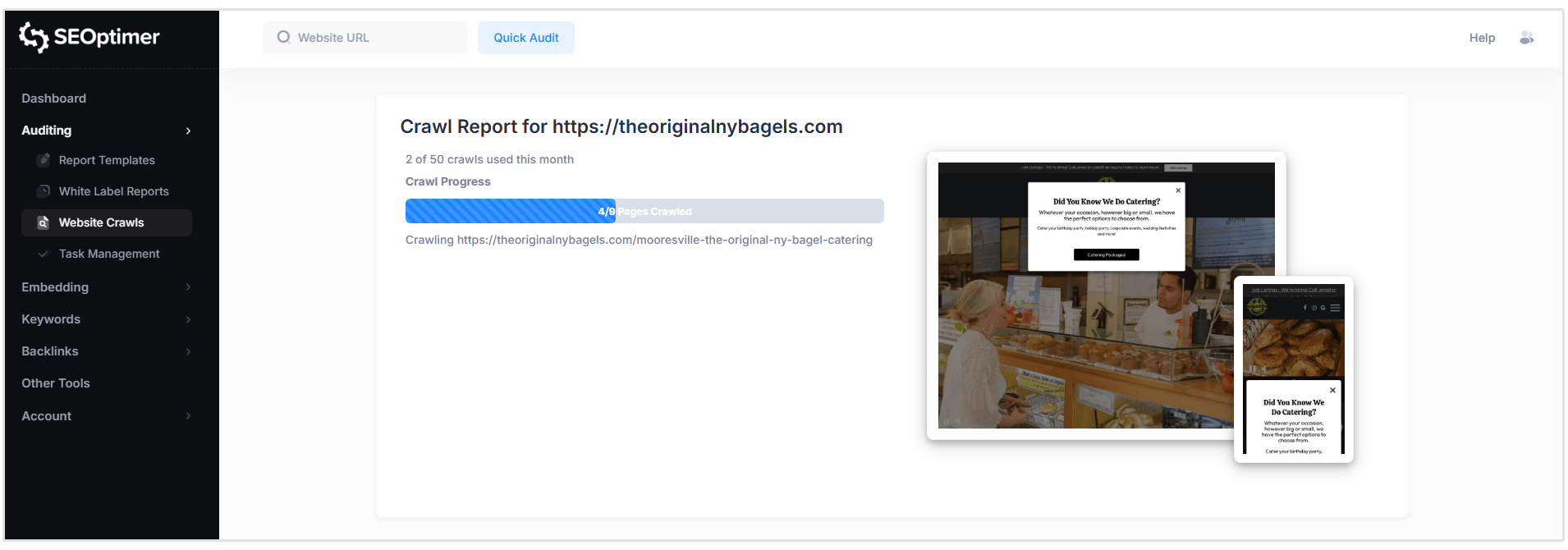
Durante l'esecuzione della scansione, puoi iniziare a esaminare i "problemi" man mano che vengono rilevati aprendo il rapporto di scansione.
Cosa puoi "vedere" in [ogni] "rapporto di scansione"?
Una volta che il nostro strumento ha terminato la scansione del tuo sito, vedrai tre sezioni principali:
- Intestazione del [Report]
- Pagine [identificate]
- Sommario del [problema]
Camminiamo attraverso ciascuna di queste sezioni.
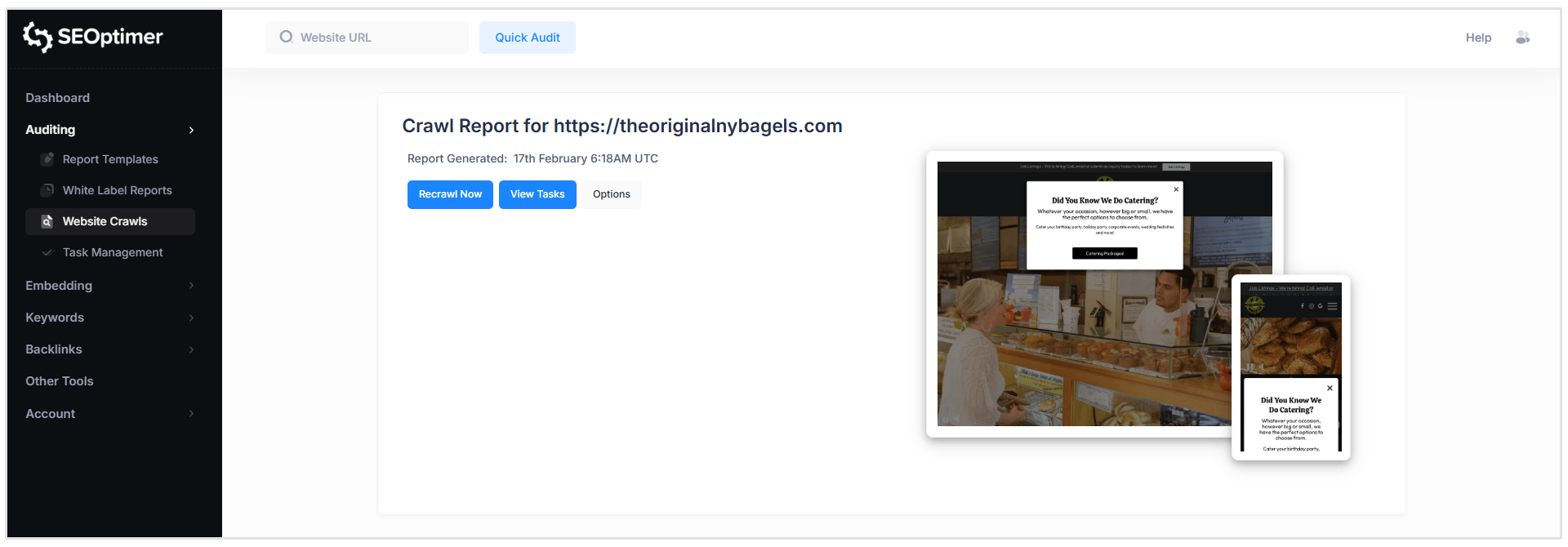
Intestazione del "Report"
Qui puoi vedere quando è stato generato il rapporto, chiedere una nuova scansione, visualizzare i compiti e personalizzare le regole di scansione. (maggiori informazioni su queste funzionalità più avanti)
Pagine Identificate
Questa sezione mostra una tabella di tutte le pagine scoperte durante la scansione, insieme ai problemi SEO rilevati per ciascuna pagina.
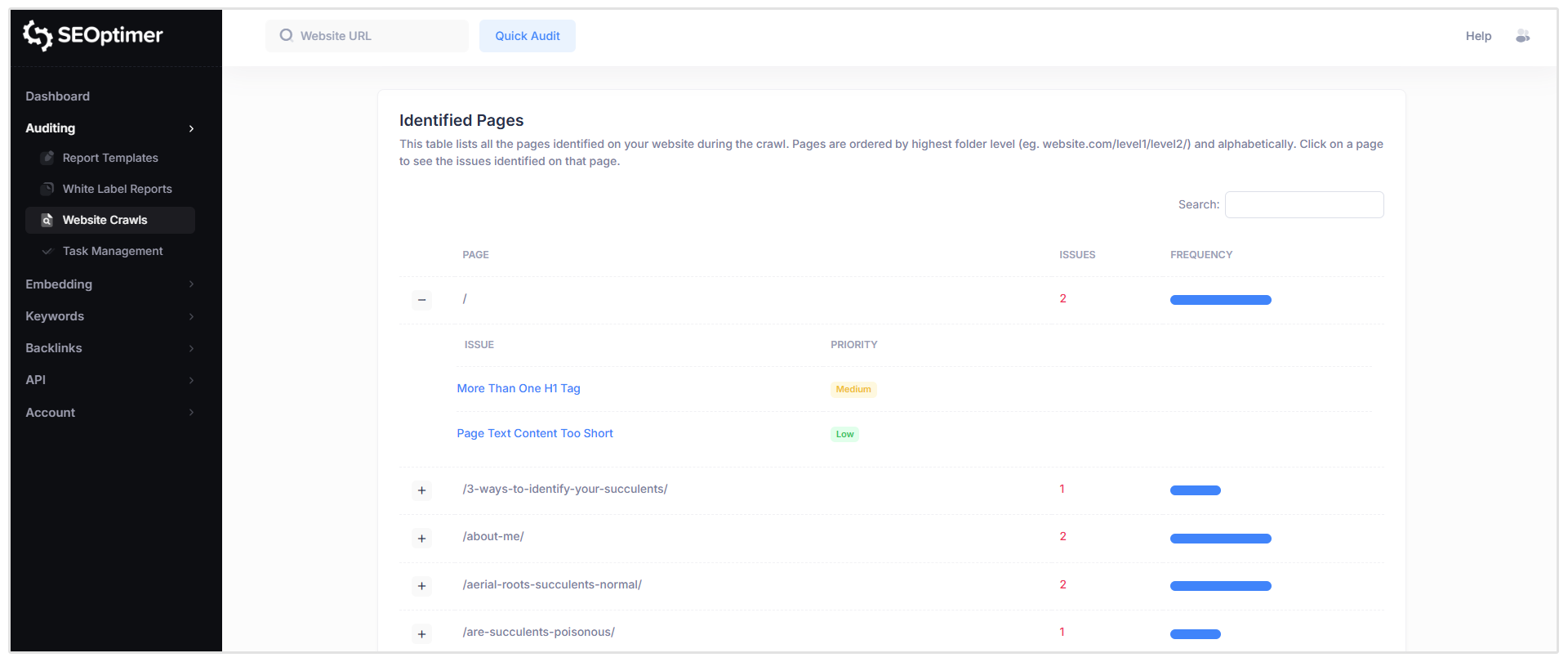
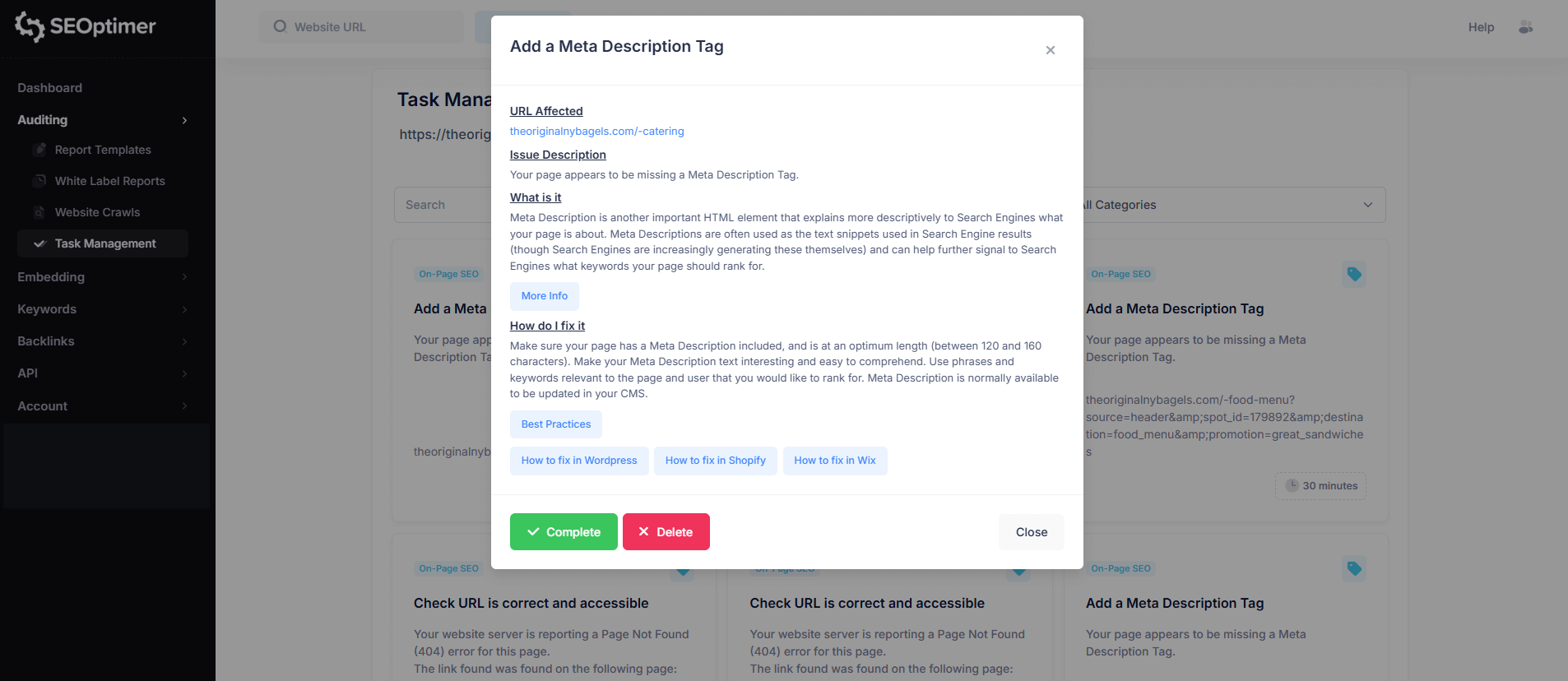
Quando fai clic su una pagina specifica (ad esempio, il percorso della homepage principale mostrato come “/”), vedrai un elenco di tutti i problemi segnalati per quell'URL, incluso il livello di gravità di ciascun problema.
Per visualizzare maggiori dettagli, fai clic su qualsiasi problema nell'elenco.
Ad esempio, selezionare “Più di un tag H1” aprirà un'analisi dettagliata di quel problema per la pagina selezionata.
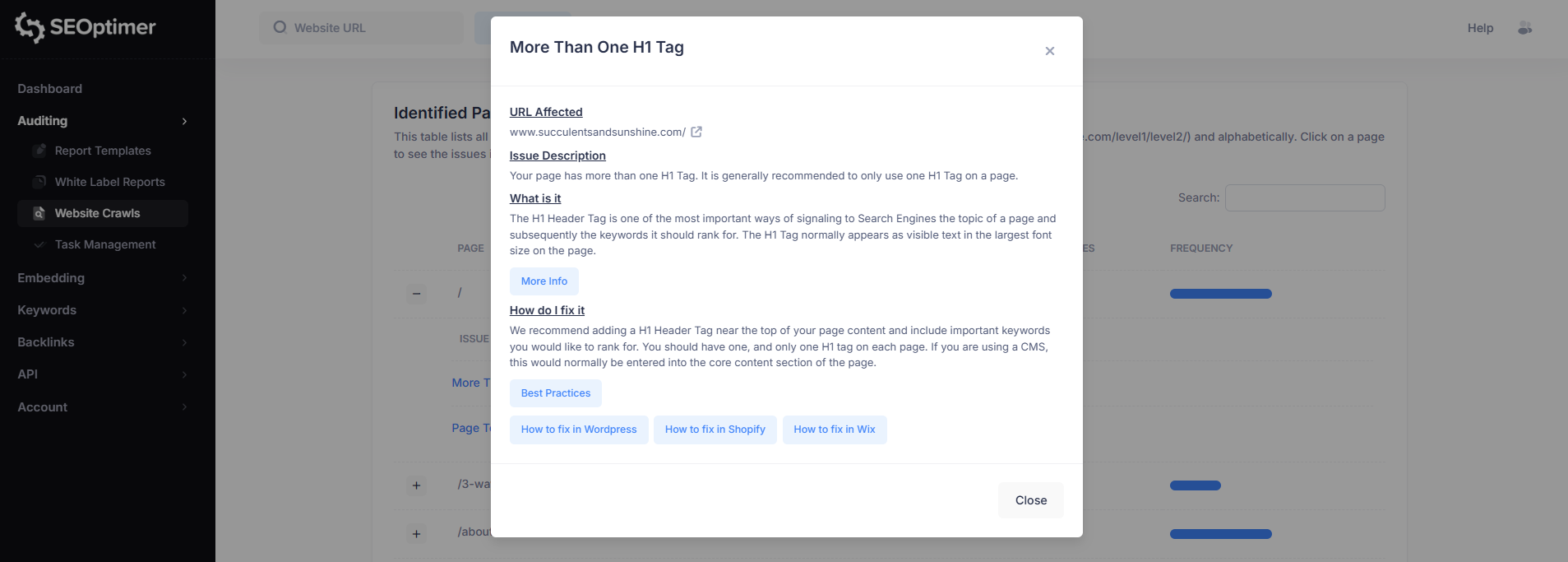
Questa vista del problema include:
- URL interessato
- Descrizione del problema
- Cosa significa il problema
- Come risolverlo
Ogni pop-up del problema includerà anche link a guide di supporto per aiutarti a risolvere il "problema" sul tuo sito web.
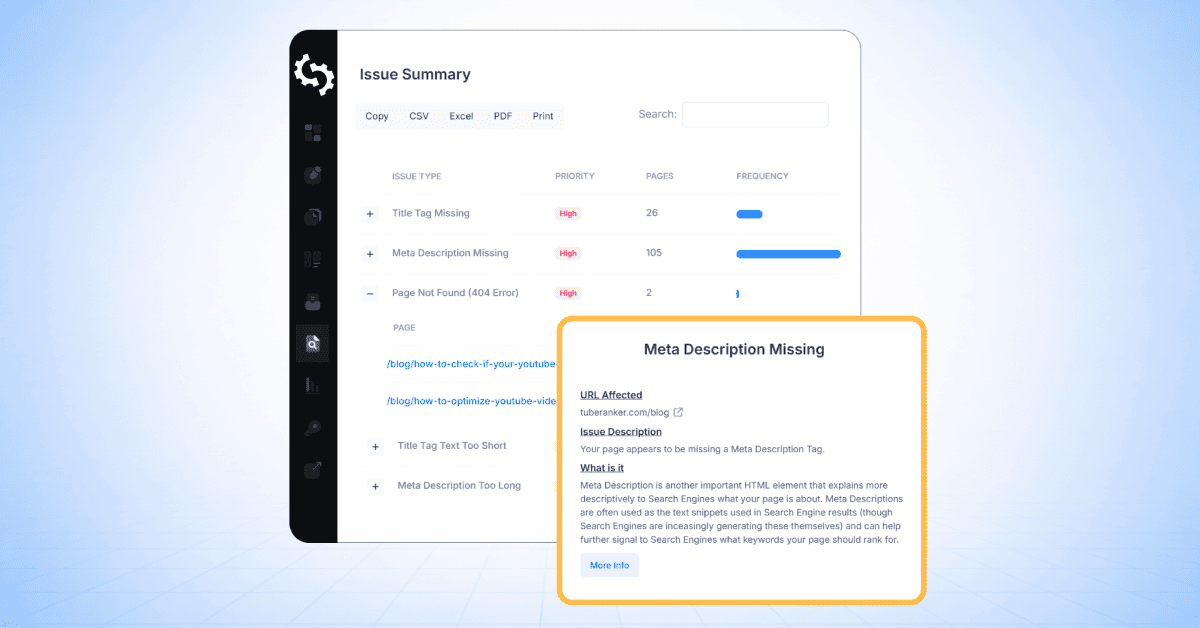
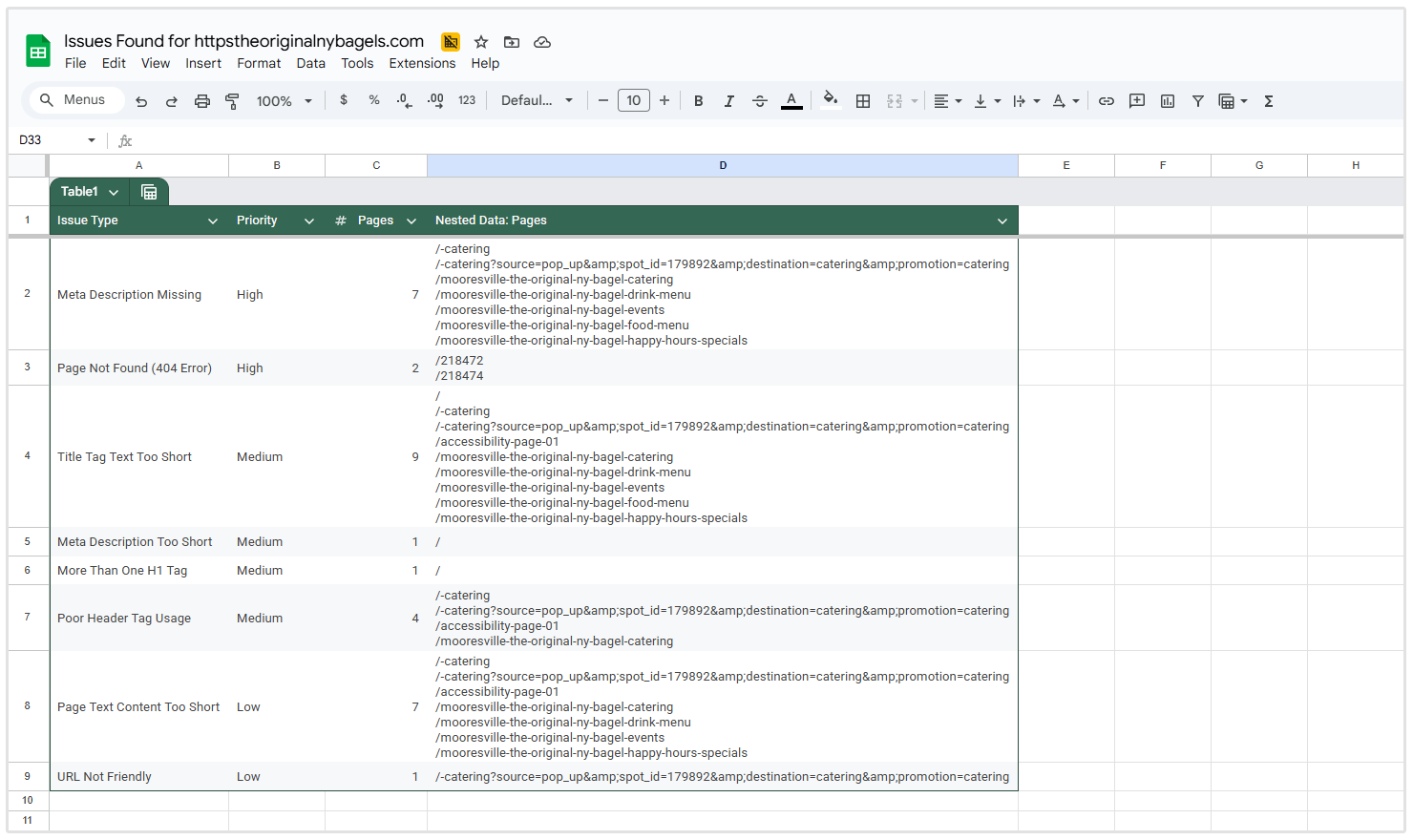
Riepilogo del problema
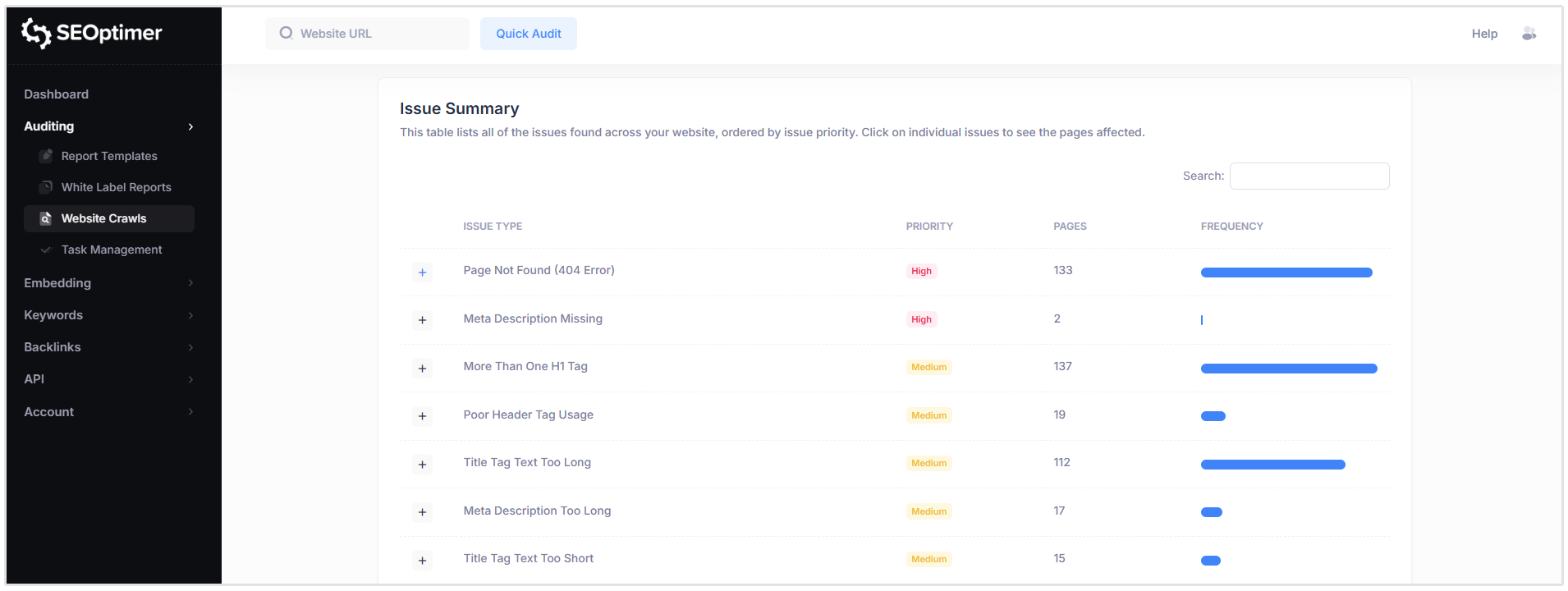
La sezione "Riepilogo delle problematiche" fornisce una panoramica di tutte le problematiche SEO rilevate nel tuo sito web, raggruppate per tipo di problema e ordinate per priorità.
Per ciascun problema, la tabella mostra:
- Tipo di problema
- Livello di priorità
- Numero di pagine interessate
Quindi nello screenshot qui sotto di un sito che ho scansionato, puoi vedere che ci sono 137 pagine che hanno più di un tag H1, 133 pagine che hanno errori 404 e 2 pagine che non hanno una meta descrizione.
Una volta che hai esaminato il riepilogo del problema, puoi procedere con la configurazione delle impostazioni di scansione ed esplorare opzioni aggiuntive di SEO Crawler.
Visualizza Compiti
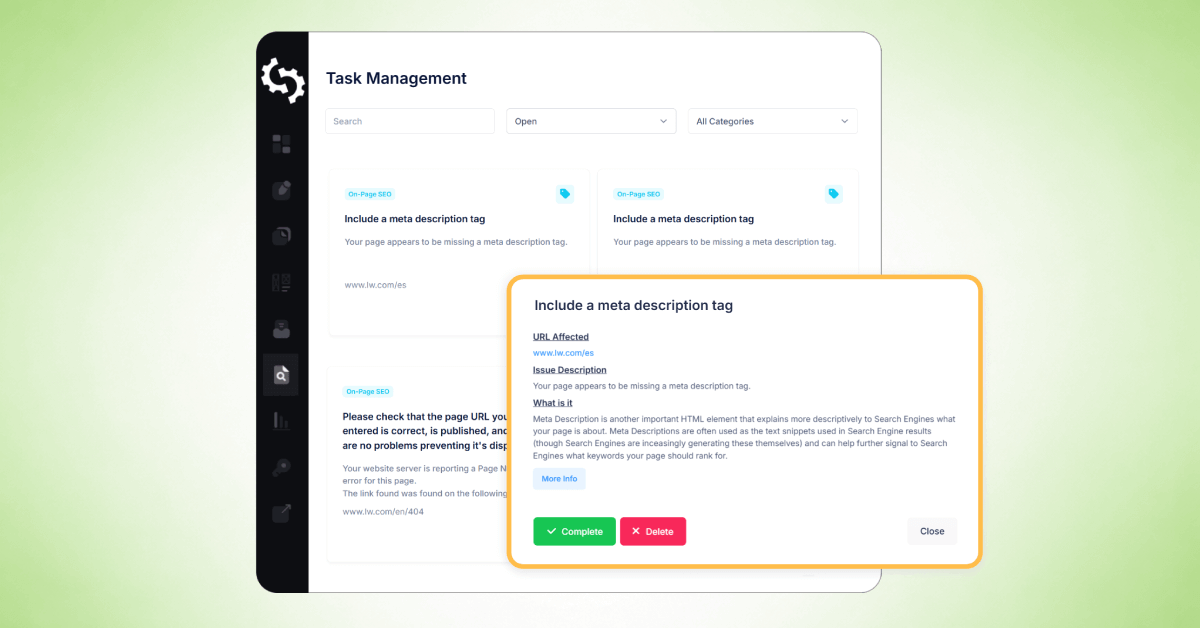
Dopo aver completato una scansione del sito web, puoi utilizzare la funzione di "Task Management" di SEOptimer per organizzare e tenere traccia dei problemi identificati nel tuo rapporto di scansione.
Lo strumento di "Task Management" converte i problemi di scansione in un elenco di attività che puoi gestire in un unico spazio di lavoro, rendendo più facile dare priorità alle correzioni e monitorare i progressi nel tempo.
Come Accedere alla "Task List"
Puoi aprire la tua lista delle attività in due modi:
- Fare clic sul pulsante blu “Visualizza attività” nell'intestazione del Rapporto di scansione.
- Oppure selezionare Gestione attività dal menu di navigazione a sinistra nel tuo pannello di controllo.
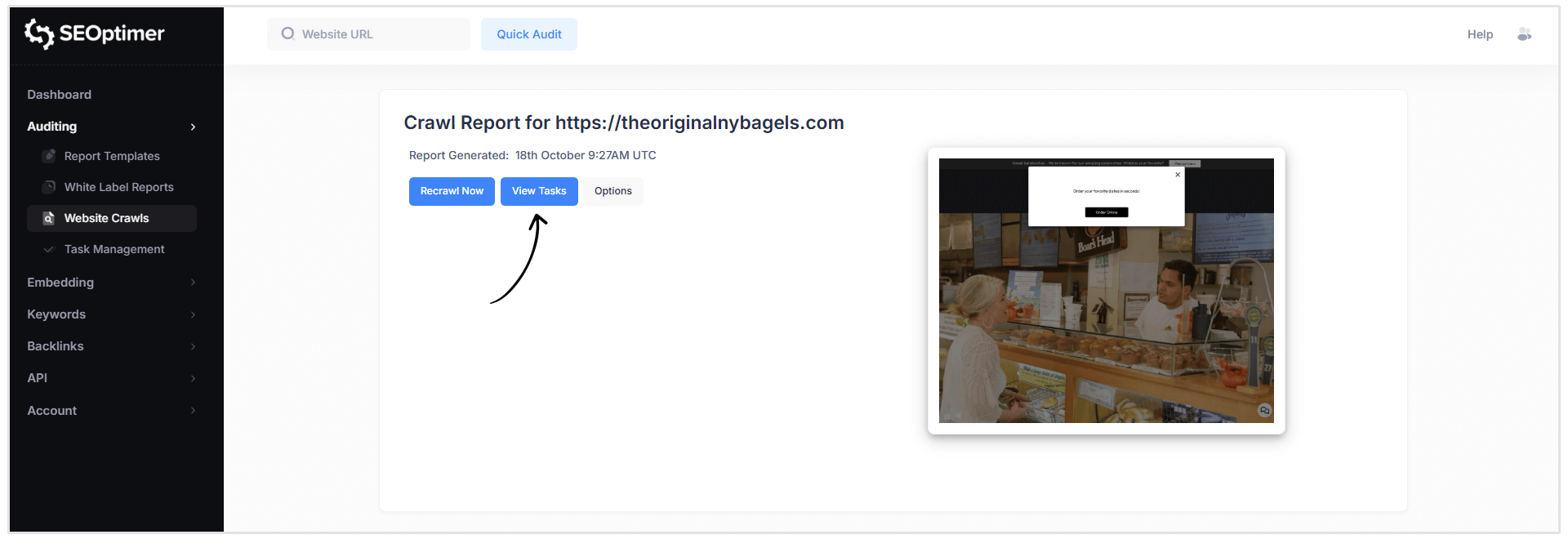
Nota: Se hai eseguito la scansione di più siti web, puoi passare da un elenco di attività all'altro utilizzando il menu a discesa nella parte superiore della pagina di Gestione attività.
Filtraggio e Gestione delle Attività
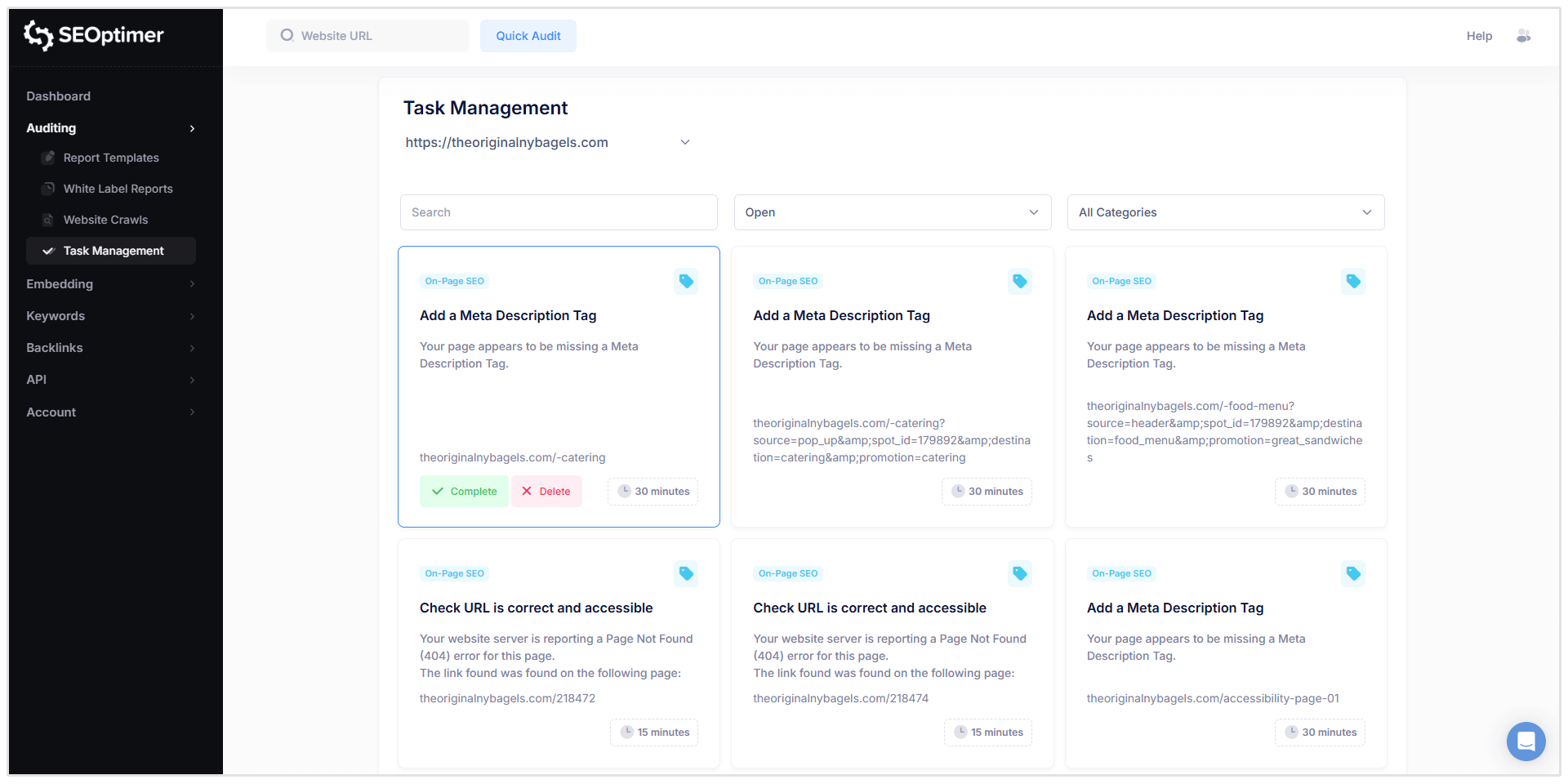
Le "attività" possono essere filtrate per:
- Stato (Aperto, Completato, Eliminato)
- Categoria (ad es. SEO On-Page, Link, ecc.)
Quando fai clic su un'attività, vedrai informazioni dettagliate simili al rapporto di scansione, inclusi:
- URL interessato
- Descrizione del problema
- Cosa significa il problema
- Come risolverlo
- Opzioni per completare l'attività o eliminarla dall'elenco delle attività
Come "schedulare" le scansioni
Hai anche l'opzione di programmare le scansioni per eseguirle su base settimanale o mensile. Questa funzione è particolarmente utile per le agenzie che gestiscono più siti web di clienti.
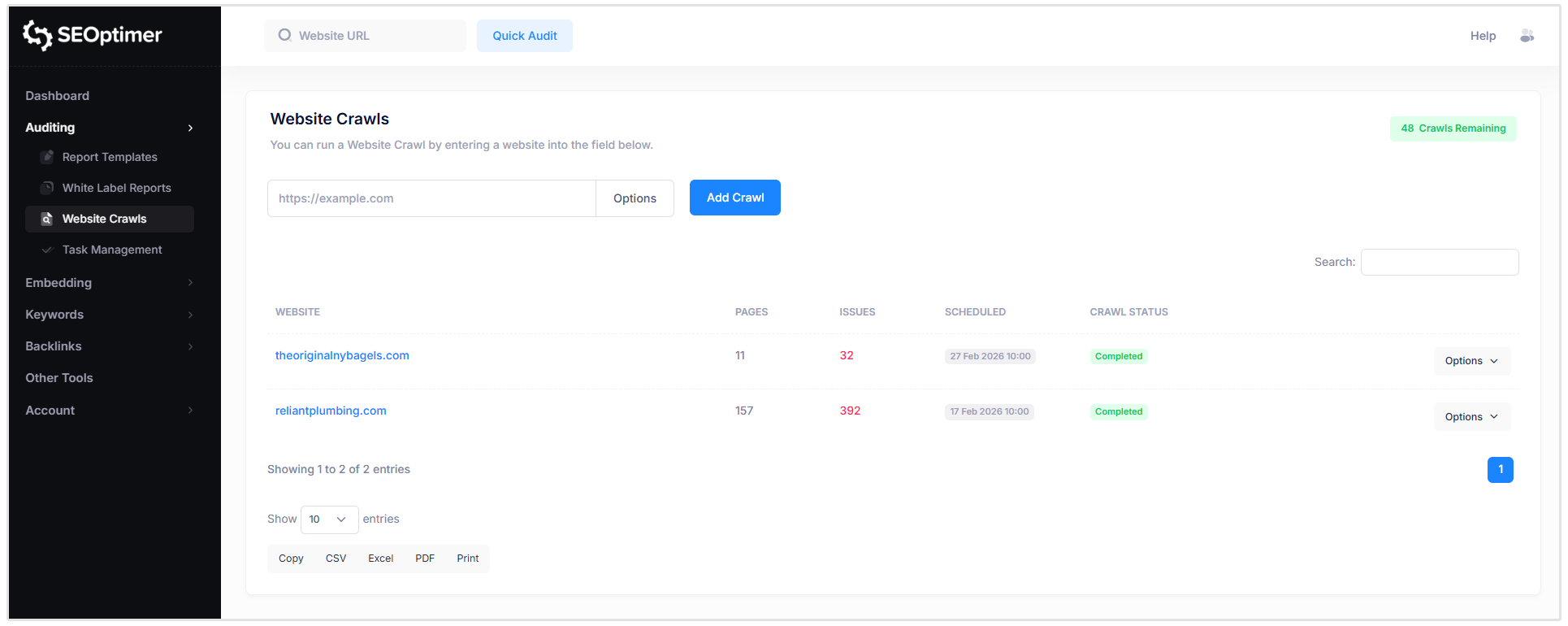
Per impostare un programma di scansione, fai semplicemente clic sul pulsante “Opzioni” a destra del sito web per il quale desideri pianificare una scansione.
Quindi, fai clic sull'opzione “Schedule” e personalizza il programma di scansione secondo le tue preferenze.
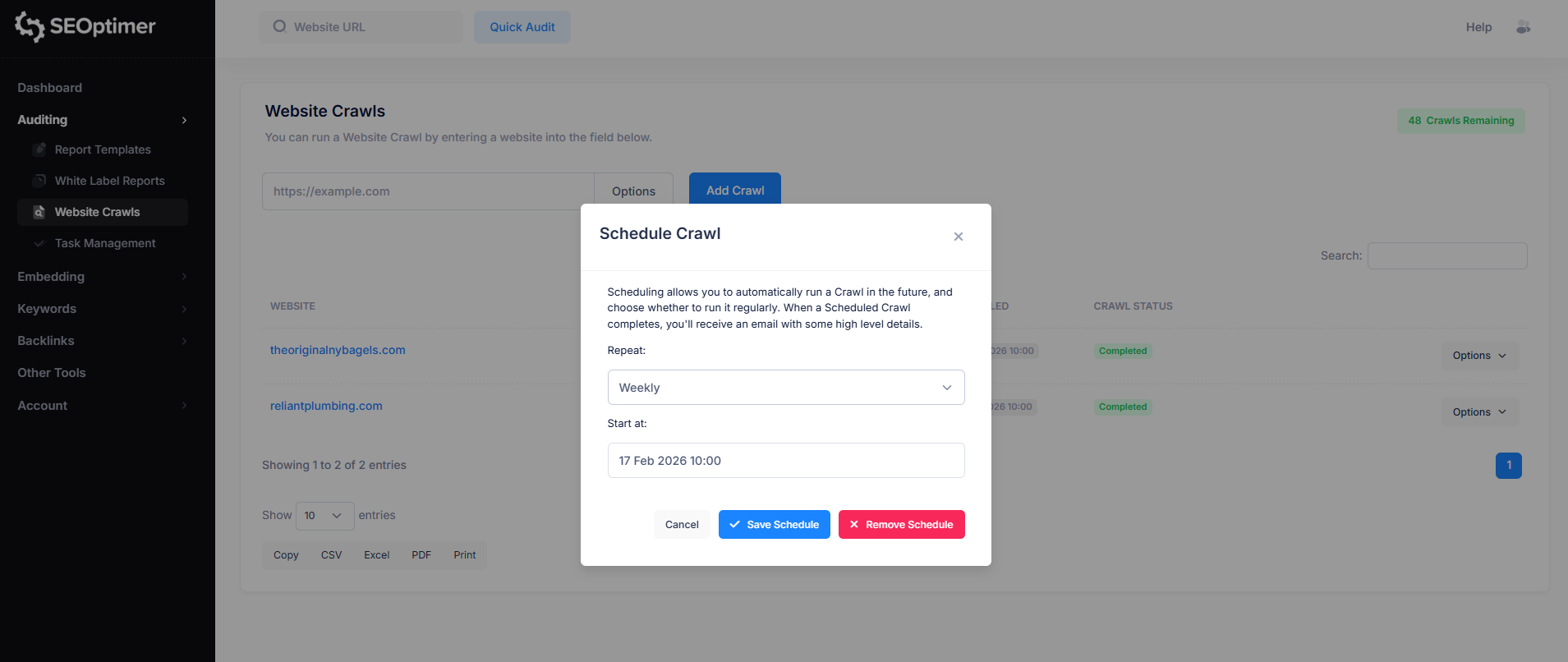
Quando una scansione programmata è completata, riceverai un'email con alcuni dettagli di alto livello.
Impostare le proprie "Regole di scansione"
Il SEO Crawler include opzioni di configurazione del crawl che ti permettono di controllare quali pagine sono incluse in un crawl.
Queste impostazioni sono utili se vuoi limitare i risultati, evitare URL duplicati o assicurarti che il crawler si comporti in linea con le regole di indicizzazione del tuo sito.
Obbedire alle esclusioni di Robots.txt
Per impostazione predefinita, il crawler può seguire le regole definite nel file robots.txt del tuo sito. Questo determina se il crawler deve evitare di scansionare le pagine che sono contrassegnate come non consentite.
- Abilitato (consigliato): Il crawler rispetterà le esclusioni di robots.txt e salterà le pagine bloccate.
- Disabilitato: Il crawler ignorerà le regole di robots.txt e tenterà di eseguire la scansione di tutte le pagine a cui può accedere.
Nella maggior parte dei casi, è consigliato rispettare robots.txt, soprattutto quando si eseguono "crawl" su siti di produzione dal vivo.
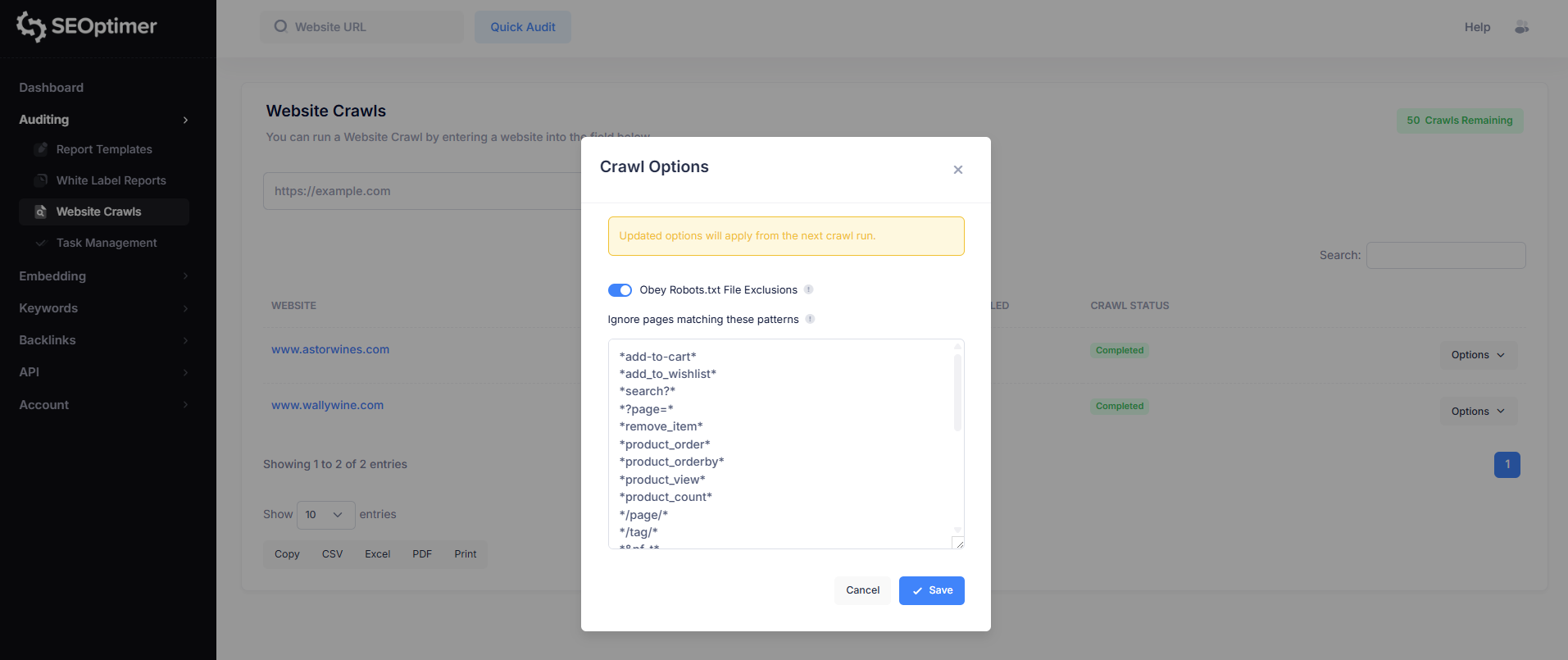
Ignora le pagine che corrispondono a questi modelli
Alcuni siti web generano più versioni della stessa pagina utilizzando parametri URL (ad esempio, "ordinamento", "filtraggio", "paginazione" o codici di tracciamento).
Questo è particolarmente comune sui siti web di ecommerce.
L'opzione “Ignora pagine che corrispondono a questi modelli” ti consente di escludere questi URL duplicati o di scarso valore dall'essere sottoposti a scansione. Questo aiuta a mantenere i risultati della scansione più puliti e rende più facile la revisione della segnalazione dei problemi.
Questa è una funzionalità più avanzata ed è principalmente utile per siti web con un gran numero di URL basati su parametri.
SEOptimer include un set predefinito di modelli di esclusione per filtrare i duplicati comuni basati su parametri, ma puoi aggiungere le tue regole se necessario.
Questi schemi seguono la sintassi standard di corrispondenza dei robots.txt.
Se non hai familiarità con le regole di robots.txt o la corrispondenza dei modelli URL, è consigliato rivedere le basi prima di aggiungere esclusioni di scansione personalizzate. Modelli errati potrebbero impedire la scansione di pagine importanti.
Ecco alcuni riferimenti utili:
- Robots.txt - La Guida Definitiva
- Introduzione e Guida a Robots.txt | Google Search Central
- Come Google interpreta la specifica robots.txt
- Sintassi di Robots.txt
Come [esportare] i dati di scansione
Ogni tabella nel rapporto SEO Crawler include opzioni di esportazione integrate, che ti permettono di scaricare o condividere i risultati del crawl al di fuori della piattaforma.

In fondo a ciascuna tabella, vedrai i pulsanti di esportazione che ti permettono di esportare i dati in diversi formati:
- CSV: Scarica la tabella come file .csv (utile per fogli di calcolo e elaborazione dati).
- Excel: Esporta la tabella come file Excel per reportistica o ulteriori analisi.
- PDF: Genera una versione PDF della tabella per condivisione o documentazione.
- Print: Apri una versione della tabella adatta alla stampa.
Le "esportazioni" si applicano alla tabella specifica che stai visualizzando, rendendo facile scaricare "elenchi di problemi", "rapporti sulle pagine" o "risultati filtrati" secondo necessità.
Conclusione
Il SEO Crawler di SEOptimer rende facile identificare i problemi tecnici e di SEO on-page su tutto il tuo sito web in una singola scansione.
Esaminando il rapporto di scansione e utilizzando l'elenco delle attività integrato, puoi rapidamente trasformare i risultati della scansione in miglioramenti concreti.
Per ottenere i migliori risultati, prendi in considerazione la possibilità di programmare scansioni regolari per monitorare i cambiamenti nel tempo e individuare nuovi problemi man mano che il tuo sito web cresce.
Hai bisogno di aiuto?
"Chat" [dal vivo]: Clicca "Chat" [dal vivo] (in basso a destra)
Email: [email protected]
Tempo di risposta: Entro 24 ore