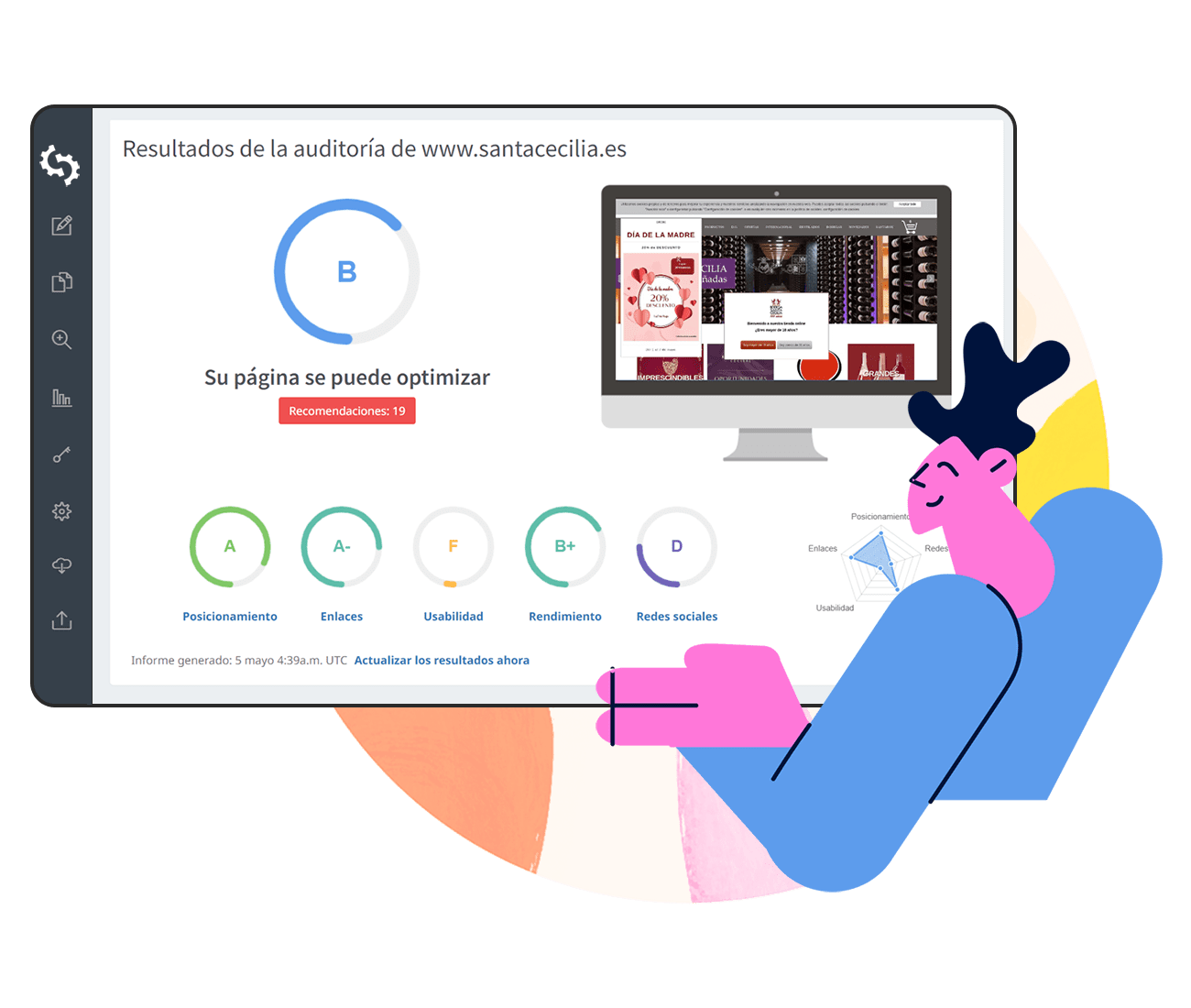
¿Sabes cuando usas Google para buscar un servicio, o encontrar información? Y una vez que la página se carga, siempre hay un sitio web en la parte superior.
Los sitios en la posición 1 en la página de resultados del motor de búsqueda de Google (SERP) obtienen la mayor parte de todos los clics. Así que, como se suele decir, es importante seguir las mejores prácticas de SEO para intentar maximizar la posición de tu sitio en el SERP.
Pero, ¿sabes cómo Google [even] encuentra tu sitio en primer lugar?
La respuesta son los rastreadores de Google. Los rastreadores de Google son como pequeños robots digitales que visitan sitios web y recopilan información sobre esos sitios.
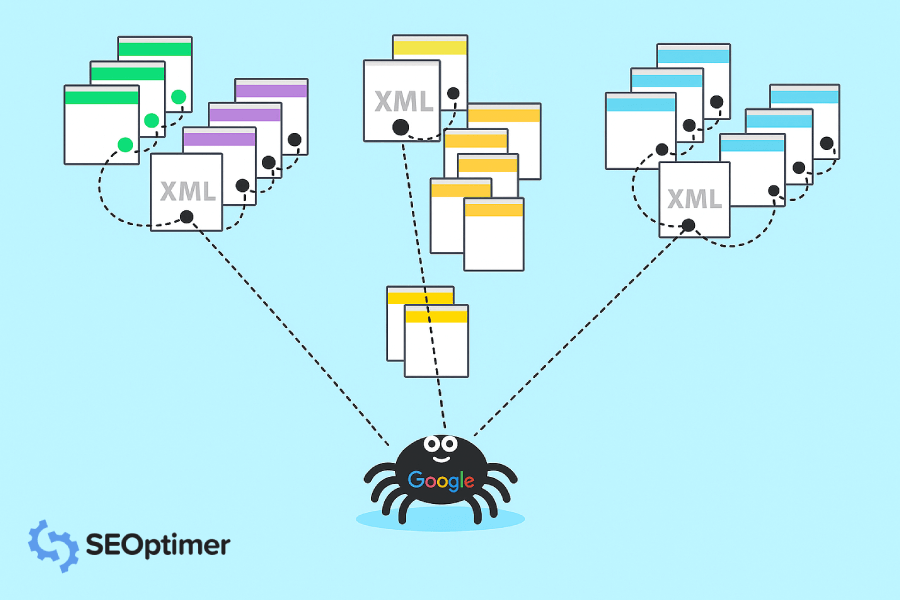
Luego, Google indexa toda esa información y la utiliza para mejorar su algoritmo de búsqueda. Cuando alguien escribe una consulta en Google, el algoritmo de búsqueda revisa toda la información indexada para encontrar los mejores resultados para la consulta de la persona.
¡Y así es como Google puede ofrecerte los mejores resultados cuando buscas algo en internet!
¿Qué es un Google Crawler?
Un Google Crawler también se conoce como “robot” o “araña,” (¿lo entiendes?, porque rastrean) y van de sitio web en sitio web en busca de nueva [información] para almacenar en sus bases de datos. Hay 15 tipos de crawlers que son utilizados por Google, pero el más importante es Googlebot.

Si bien Google es poderoso, no puede hacer todo, cada vez que se crea una nueva página web, Google no lo sabe hasta que esa página ha sido rastreada.
Google utiliza el Googlebot para obtener constantemente la "última información" para almacenar en su base de datos.
Indexación de Google vs Rastreo de Google
La "indexación" solo ocurre después de que el sitio web ha sido rastreado por GoogleBot. Cuando es rastreado, es escaneado, y la información escaneada de ese sitio o página se almacena en el índice de Google.
El índice "categorizará" y "clasificará" las páginas "correspondientemente" en los resultados de búsqueda.
¿Por qué son importantes los rastreadores de Google?
Entonces, ¿por qué es todo esto [importante]?
Bueno, digamos que diriges un negocio y tienes un sitio web. Quieres que tu sitio web esté lo más cerca posible de la parte superior. Si tu sitio web no es "rastreado" y escaneado, no se cargará en la página de búsqueda.
Sin ninguna presencia en internet, no podrás llegar a tu audiencia o consumidores. "Crawling" e "indexing" hacen que sea un poco más fácil para los sitios web obtener algo de atención.
Cómo funciona un rastreador de Google
Entonces, sabes lo que es pero ¿cómo funciona? Aunque Google es poderoso, no puede hacer todo, cada vez que se crea una nueva página web Google no lo sabe hasta que esa página ha sido rastreada. Google utiliza el Googlebot para obtener constantemente información adicional para almacenar en su base de datos.
Una vez que esa página web es rastreada o escaneada. La página se renderiza y se le asigna un HTML, CSS, JavaScript y código de terceros, todos los cuales son necesarios para que Googlebot indexe y clasifique sitios web. Googlebot, el rastreador más grande, es capaz de ver y renderizar todas las páginas web y sitios web con Chromium.
El Chromium siempre se está actualizando para que pueda [permanecer] estable y [realizar] su trabajo con precisión. Esto está disponible para todos y también puede ser utilizado para probar [nuevas] "funciones" y hacer [nuevos] navegadores.
Cómo Hacer que tu Sitio sea Más Fácil de Rastrear
Ahora que sabemos con qué estamos trabajando, trabajemos en hacer que tu sitio web sea fácil de rastrear.
Aquí hay algunos consejos y trucos para hacer que tu sitio web sea un imán para los rastreadores y subir a la cima en la página de resultados de búsqueda.
Enlaces Internos
Los enlaces internos pueden ser tu mejor amigo para el rastreo. Es posible que tu sitio ya haya sido rastreado por Google en el pasado, pero recientemente es posible que hayas agregado más páginas. Si el rastreador ya conoce tu sitio web, solo se centrará en las páginas principales.
Recuerda, Google no es alertado cada vez que se crea una nueva página, rastrea para encontrar esas páginas.
Usar "enlaces internos" en las páginas principales guía al rastreador a donde necesita ir. El mejor lugar para estos enlaces internos es tu [página] de inicio, es la [página] que recibe más tráfico y donde el rastreador escaneará primero.
Enlaces de retroceso
Backlinks son otra gran manera de conseguir que tu sitio sea rastreado. Este método puede ser utilizado para “promocionar” tu sitio web al rastreador.
Vincular a un sitio web más popular aumentará tus posibilidades de ser descubierto por el rastreador.
Nota: Puedes comprobar fácilmente el perfil de backlinks de cualquier sitio, incluidos tus competidores, utilizando la herramienta gratuita de investigación de backlinks de SEOptimer.
![Herramienta gratuita de verificación de [backlinks]](/storage/images/2025/06/7014-free backlink checker.png)
Imágenes
Las "imágenes" pueden ser rastreadas, de hecho, hay un rastreador específico solo para imágenes. Este rastreador es conocido como Googlebot Image, y recopila imágenes para la base de datos.
Sitemaps
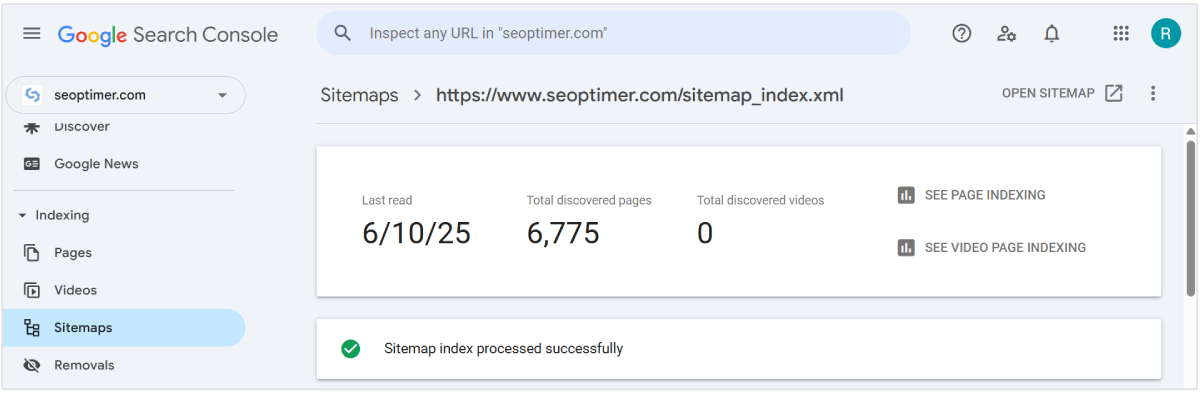
Hay una forma de decirle a Google qué páginas quieres que rastreen más directamente. Puedes enviar un mapa del sitio con una lista detallada de las páginas que deseas que sean rastreadas por Google.
Utilice nuestro Generador de Sitemaps XML para construir un "sitemap" de todo su sitio web. Hágalo, nómbrelo. Y descárguelo a su ordenador para cargarlo en [Google Search Console].
Profundidad de Clic
La "profundidad de clic" (también conocida como "profundidad de rastreo") te muestra cuánto trabajo tendría que hacer un rastreador para llegar y escanear tu página. Nunca quieres que el rastreador tenga que hacer demasiado trabajo, deseas que tu página o sitio web sea lo más amigable posible para el rastreador.
Debería tomar alrededor de "tres" clics o menos, cuanto más tome, más [ralentiza] el rastreador.
Una buena estructura debería permitirte agregar nuevas páginas sin influir en tu "profundidad de clics". El rastreador también debería poder llegar a estas páginas fácilmente.
FYI: Una buena regla general es asegurarse de que se pueda navegar desde una página de su sitio a cualquier otra página de su sitio con no más de 3 clics. Esto garantiza que Google pueda encontrar e indexar todas sus páginas de manera eficiente. Además, es excelente para la experiencia del usuario.
Instrucciones de indexación
Hay instrucciones que Google sigue al rastrear e idear páginas. Robots.txt, etiqueta noindex, metaetiqueta robots y X-Robots-Tag. No te preocupes, lo desglosaremos para ti.
Robots.txt. es un archivo del directorio raíz que [retiene] ciertas páginas y contenido de Google. Cuando el rastreador está escaneando una página, estará buscando esto para información. Si el rastreador no puede encontrar esta información, cesará su rastreo y la página no será parte de los resultados de búsqueda.
La etiqueta noindex evita que todo tipo de rastreadores puedan escanear e indexar una página.
La etiqueta meta de robots puede ayudar a controlar la forma en que se supone que una página debe ser indexada y cargada para los navegantes web en los resultados de búsqueda.
X-Robots-Tag, es una parte del encabezado HTTP y ayudará a controlar el comportamiento del rastreador. Supervisa cómo se indexa toda la página. Puedes bloquear imágenes y videos en una página usando este método. También puedes dirigir tipos de rastreadores individualmente, pero solo si está especificado.
Si no se especifica el tipo de rastreador, entonces las instrucciones serán para todos los rastreadores de Google.
Estructura de URL
Es posible que hayas oído esto antes, pero asegúrate de tener una URL fácil de usar.

Un URL que sea fácil, uno que tanto tus consumidores como los algoritmos amarán. Intenta mantener tu URL lo más "corta" y "dulce" posible.
Si tienes una URL larga, puede ser confuso no solo para el ojo humano sino también para el bot de Google.
Cuanto más confundido esté el Googlebot, más agotará sus recursos de rastreo y eso definitivamente no es lo que deseas.
Problemas Comunes (y Soluciones) con el Rastreo de Google
Entonces, tienes una página pero no está funcionando como deseas. Esto podría ser porque el rastreador está teniendo dificultades para escanear e indexar tu sitio.
Aquí hay algunos problemas comunes que las personas han encontrado con el rastreo de Google.
1. Google no está rastreando tu sitio web
Asegúrate de comprobar si tu página o sitio es compatible con rastreo. Eso significa tener un buen URL, incorporar los enlaces internos y backlinks si es necesario, o tomarse el tiempo para crear un mapa del sitio para mostrar a Googlebot dónde rastrear.
Además, ten en cuenta que Google puede tardar un tiempo en rastrear e indexar tu sitio web porque tiene que venir a encontrarte.
2. Has sido eliminado del índice de Google
Google eliminará un sitio web si siente la necesidad de hacerlo, ya sea por ley, relevancia o por no seguir las "directrices" establecidas. Usa nuestro SEO Crawler para comprobar si hay algo que podría estar bloqueando el crawler de tu página.
Una vez que hayas hecho eso, puedes enviar tu sitio web a Google para su reconsideración.
3. Tienes "contenido duplicado"
El "contenido duplicado" es una página que tiene contenido similar a otra página o múltiples URLS que enlazan a una página.

En el caso de tener páginas con contenido similar, lo que también podría significar que tienes una versión de escritorio y una versión móvil de una página. Sin embargo, el ejemplo más común de "contenido duplicado" en varias páginas.
Estos pueden ser tanto evitados como corregidos con un URL canónico, o URL que sirve como representante para estas páginas duplicadas.
Google solo mostrará la página que creen que tiene el contenido más útil y la etiquetarán como canónica. Esta es la página que se rastreará en lugar de los duplicados.
Para evitar esto, considere reescribir el texto en estas páginas para que no se confundan como duplicados.
4. Hay "problemas" de [renderizado]
Si tienes problemas de "renderizado", asegúrate de que tu codificación no sea demasiado grande. Tu codificación necesita ser lo más limpia posible para que el "crawler" pueda "renderizar" todo correctamente.
Si el "crawler" no puede renderizar la página, se considerará vacía.
Preguntas Frecuentes del Rastreador de Google
¿Cuánto tiempo tarda Google en rastrear un sitio web?
Normalmente, Google tarda desde días hasta semanas en rastrear. Puedes monitorear el rastreo utilizando el "Informe de estado de indexación" o la herramienta de inspección de URL. Recuerda, Google no es notificado cada vez que se crea un nuevo sitio web o página, tiene que rastrearlo y encontrarlo.
FYI: Los sitios más populares se rastrean más rápido. Los sitios nuevos generalmente requerirán semanas para ser rastreados, mientras que los sitios de [reputación] como NY Times, Wall Street Journal y Wikipedia son rastreados varias veces al día.
¿Qué es el algoritmo del "Google Crawler"?
El algoritmo de Google Crawler se basa en cuán amigable para los "crawlers" es tu sitio. Esto incluye [palabras clave], URLs, [contenido] e información, codificación y mucho más. Depende de ti proporcionar a Google el mejor [contenido] y orientación para que pueda encontrar tu página y comenzar a rastrear.
¿Están todas las páginas disponibles para el rastreo?
Esta es una "buena" pregunta. La [respuesta] corta es no. Algunas páginas no pueden ser rastreadas e indexadas porque están protegidas con contraseña, fueron específicamente excluidas de las instrucciones de índice, o no tienen ningún enlace en sus páginas.
¿Cuándo aparecerá mi sitio web en la búsqueda de Google?
Esto siempre variará dependiendo de cuánto tiempo [tome] que su sitio web sea rastreado e indexado. Esto podría [tomar] solo un par de días o hasta unas pocas semanas.
¿Qué otros rastreadores web existen?
¡Sí! Hay montones de rastreadores web fuera de los quince de Google. Aquí hay algunos como referencia:
- Existe BingBot utilizado por el motor de búsqueda Bing.
- SlurpBot, utilizado por Yahoo! Este rastreador web es una mezcla entre Yahoo! y Bing, porque Bing [primarily] impulsa Yahoo!.
- ExaBot es el motor de búsqueda y rastreador más popular en Francia.
- AppleBot es utilizado por la gran empresa tecnológica Apple para la búsqueda "spotlight" y sugerencias de Siri.
- Facebook, aunque no lo creas, utiliza enlaces para enviar contenido a otros perfiles y solo puede rastrear si se proporciona un enlace.
Optimiza Tu Sitio para el Rastreo de Google
Ahora que entiendes los conceptos básicos de Google Crawling y cómo funciona, ¡úsalo a tu favor! Haz que tu sitio web se indexe correctamente y ascienda a la parte superior de la página principal de resultados de búsqueda. Es gratis y está completamente a tu disposición.