Lo sai quando usi Google per cercare un servizio o trovare informazioni? E una volta che la pagina si carica c'è sempre un sito web in cima.
I siti in posizione 1 nella pagina dei risultati del motore di ricerca di Google (SERP) ricevono la maggior parte di tutti i clic. Quindi, inutile dire che è importante seguire le migliori pratiche SEO per cercare di massimizzare la posizione del tuo sito nella SERP.
Ma sai come Google trova il tuo sito in primo luogo?
La risposta è i crawler di Google. I crawler di Google sono come piccoli robot digitali che visitano i siti web e raccolgono informazioni su quei siti.
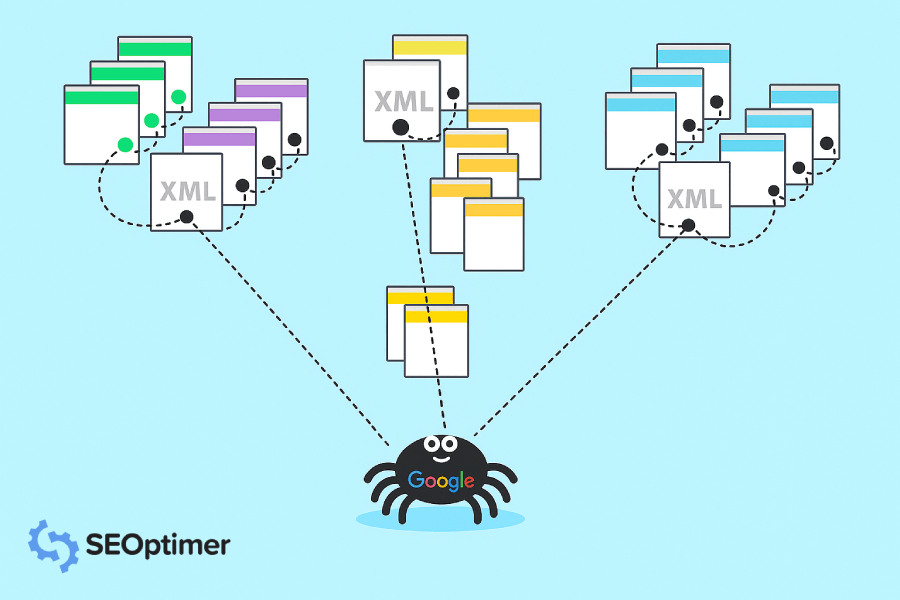
Quindi, Google indicizza tutte quelle informazioni e le utilizza per migliorare il suo algoritmo di ricerca. Quando qualcuno digita una "query" su Google, l'algoritmo di ricerca esamina tutte le informazioni indicizzate per trovare i migliori risultati per la [richiesta] della persona.
Ecco come Google riesce a offrirti i migliori risultati quando cerchi qualcosa su internet!
Che cos'è un Google Crawler?
Un Google Crawler è anche conosciuto come “robot” o “ragnatela,” (capito, perché strisciano) e vanno da sito web a sito web alla ricerca di nuove informazioni da memorizzare nei loro database. Ci sono 15 tipi di crawler utilizzati da Google, ma il più importante è Googlebot.

Per quanto Google sia potente, non può fare tutto; ogni volta che viene creata una nuova pagina web, Google non ne è a conoscenza finché quella pagina non è stata "crawled".
Google utilizza il Googlebot per ottenere costantemente le ultime informazioni da memorizzare nel suo database.
Indicizzazione di Google vs Scansione di Google
L'indicizzazione avviene solo dopo che il sito web è stato scansionato da GoogleBot. Quando viene scansionato, viene analizzato e le informazioni scansionate da quel sito o pagina vengono memorizzate nell'indice di Google.
L'indice "categorizerà" e "classificherà" le pagine di conseguenza nei risultati di ricerca.
Perché sono importanti i crawler di Google?
Quindi perché tutto questo è importante?
Bene, supponiamo che tu gestisca un'attività e abbia un sito web. Vuoi che il tuo sito web sia il più vicino possibile alla cima. Se il tuo sito web non viene "crawled" e [scanned] non verrà caricato nella pagina dei risultati di ricerca.
Senza alcuna presenza su internet, non sarai in grado di raggiungere il tuo pubblico o i consumatori. Il "crawling" e l'indicizzazione rendono leggermente più facile per i siti web ottenere un po' di attenzione.
Come funziona un crawler di Google
Quindi, sai cos'è ma come funziona? Anche se Google è potente, non può fare tutto, ogni volta che viene creata una nuova pagina web Google non ne è a conoscenza finché quella pagina non è stata "scansionata". Google utilizza il Googlebot per ottenere costantemente ulteriori informazioni da memorizzare nel suo database.
Una volta che quella pagina web è [crawled] o scansionata. La pagina viene resa e fornita di HTML, CSS, JavaScript e codice di terze parti, tutti necessari affinché il Googlebot possa indicizzare e classificare i siti web. Googlebot, il più grande [crawler], è in grado di vedere e rendere tutte le pagine web e i siti web con Chromium.
Il Chromium è sempre in aggiornamento affinché possa rimanere stabile e svolgere il suo lavoro con precisione. Questo è disponibile per tutti e può anche essere utilizzato per testare nuove funzionalità e creare nuovi browser.
Come Rendere il Tuo Sito Più Facile da Scansionare
Ora che sappiamo con cosa stiamo lavorando, lavoriamo per rendere il tuo sito web facile da scansionare.
Ecco alcuni suggerimenti e trucchi per rendere il tuo sito web un magnete per i crawler e salire in cima alla pagina dei risultati di ricerca.
Link Interni
I link interni possono essere il tuo migliore amico per il crawling. Il tuo sito potrebbe essere già stato scansionato da Google in passato, ma di recente potresti aver aggiunto più pagine. Se il crawler conosce già il tuo sito web, si concentrerà solo sulle pagine principali.
Ricorda, Google non viene avvisato ogni volta che viene creata una nuova pagina, la "esplora" per trovare quelle pagine.
L'utilizzo dei link interni sulle pagine principali guida il crawler dove deve andare. Il posto migliore per questi link interni è la tua homepage, è la pagina che riceve più traffico e dove il crawler effettuerà la scansione per primo.
Backlink
Backlink sono un altro ottimo modo per far scansionare il tuo sito. Questo metodo può essere utilizzato per “promuovere” il tuo sito web al crawler.
Collegarsi a un sito web più popolare aumenterà le tue possibilità di essere scoperto dal crawler.
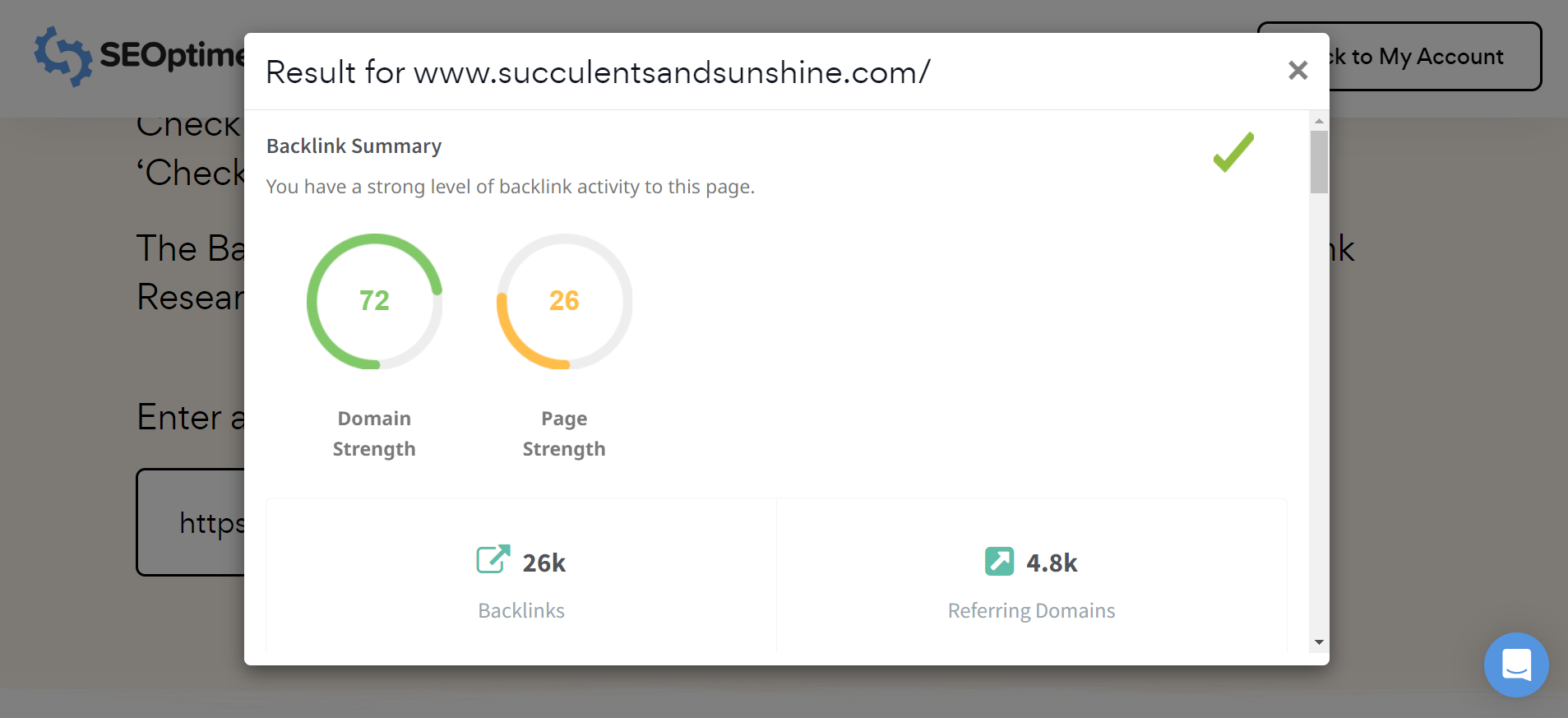
Nota: Puoi facilmente controllare il profilo dei [backlink] per qualsiasi sito, inclusi i tuoi concorrenti, utilizzando lo strumento gratuito di ricerca dei backlink di SEOptimer.
Immagini
Le immagini possono essere sottoposte a crawling, infatti esiste un crawler specifico solo per le immagini. Questo crawler è noto come Googlebot Image e raccoglie immagini per il database.
Sitemap
C'è un modo per dire a Google quali pagine vuoi che vengano scansionate in modo più diretto. Puoi inviare una sitemap con un elenco dettagliato delle pagine che vuoi che siano scansionate da Google.
Usa il nostro Generatore di Sitemap XML per creare una sitemap dell'intero tuo sito web. Creala, [dalle] un nome. E scaricala sul tuo computer per caricarla su Google Search Console.
Profondità di Clic
La profondità di clic (nota anche come profondità di scansione) ti mostra quanto lavoro dovrebbe fare un crawler per raggiungere e scansionare la tua pagina. Non vuoi mai che il crawler debba fare troppo lavoro, vuoi che la tua pagina o sito web sia il più possibile amichevole per i crawler.
Dovrebbe richiedere circa tre clic o meno, più ci vuole più rallenta il crawler.
Una buona struttura dovrebbe permetterti di aggiungere nuove pagine senza influenzare la profondità di clic. Il crawler dovrebbe comunque essere in grado di raggiungere facilmente queste pagine.
FYI: Una buona regola pratica è assicurarsi di poter navigare da una pagina del tuo sito a qualsiasi altra pagina del tuo sito con non più di 3 clic. Questo garantisce che Google possa trovare e indicizzare tutte le tue pagine in modo efficiente. Inoltre, è ottimo per l'esperienza utente.
Istruzioni per l'indicizzazione
Ci sono istruzioni che Google segue quando esegue la scansione e l'ideazione delle pagine. Robots.txt, tag noindex, meta tag robots e X-Robots-Tag. Non preoccuparti, te lo spiegheremo nel dettaglio.
Robots.txt è un file della directory principale che [trattiene] certe pagine e contenuti da Google. Quando il crawler sta scansionando una pagina, cercherà queste informazioni. Se il crawler non riesce a trovare queste informazioni, interromperà la scansione e la pagina non sarà parte dei risultati di ricerca.
Il tag noindex impedisce a tutti i tipi di crawler di eseguire la scansione e indicizzare una pagina.
Il tag meta dei robot può aiutare a controllare il modo in cui una pagina dovrebbe essere indicizzata e caricata per i navigatori web nei risultati di ricerca.
X-Robots-Tag, fa parte dell'intestazione HTTP e aiuterà a controllare il comportamento del crawler. Supervisiona come l'intera pagina viene indicizzata. Puoi bloccare immagini e video su una pagina utilizzando questo metodo. Puoi anche indirizzare tipi di crawler individualmente, ma solo se è specificato.
Se il tipo di crawler non è specificato, le "istruzioni" saranno per tutti i crawler di Google.
Struttura URL
Potresti averlo già sentito prima, ma assicurati di avere un URL facile da usare.

Un URL che è facile, uno che sia apprezzato sia dai tuoi consumatori che dagli algoritmi. Cerca di mantenere il tuo URL il più "corto" e "semplice" possibile.
Se hai un URL lungo, può risultare confuso non solo per l'occhio umano ma anche per il bot di Google.
Più il Googlebot è confuso, più esaurirà le sue risorse di scansione e questo è sicuramente [not] ciò che vuoi.
Problemi Comuni (e Soluzioni) con la Scansione di Google
Quindi, hai una pagina ma non sta performando nel modo in cui desideri. Questo potrebbe essere dovuto al fatto che il crawler sta avendo difficoltà a cercare di scansionare e indicizzare il tuo sito.
Qui ci sono alcuni problemi comuni che le persone hanno incontrato con la "Crawling di Google".
1. Google non sta eseguendo la scansione del tuo sito web
Assicurati di controllare se la tua pagina o il tuo sito è facilmente indicizzabile. Ciò significa avere un buon URL, incorporare i collegamenti interni ed esterni se necessario, o prendersi il tempo per creare una mappa del sito per mostrare a Googlebot dove effettuare la scansione.
Inoltre, tieni presente che potrebbe volerci del tempo prima che Google esegua la scansione e l'indicizzazione del tuo sito web perché deve venire a trovarti!
2. Sei stato rimosso dall'indice di Google
Google rimuoverà un sito web se lo ritiene necessario, sia per legge, rilevanza o per non aver seguito le linee guida in vigore. Usa il nostro "SEO Crawler" per controllare se c'è qualcosa che potrebbe bloccare il crawler dalla tua pagina.
Una volta fatto ciò, puoi inviare il tuo sito web a Google per una rivalutazione.
3. Hai Contenuti Duplicati
Il "contenuto duplicato" è una pagina che ha un contenuto simile a un'altra pagina o più URL che collegano a una pagina.

Nel caso di avere pagine con contenuti simili, il che potrebbe anche significare che hai una versione desktop e una versione mobile di una pagina. Tuttavia, l'esempio più comune di "contenuto duplicato" su un numero di pagine.
Questi possono essere entrambi evitati e risolti con un URL canonico, o URL che funge da rappresentante per queste pagine duplicate.
Google mostrerà solo la pagina che ritiene abbia il contenuto più utile e la etichetterà come canonica. Questa è la pagina che verrà sottoposta a scansione invece dei duplicati.
Per evitare questo, considera di riscrivere il testo su queste pagine in modo che non vengano confusi come duplicati.
4. Ci sono [problemi] di [rendering]
Se stai riscontrando problemi di "rendering" assicurati che il tuo codice non sia troppo grande. Il tuo codice deve essere il più pulito possibile affinché il crawler possa "renderizzare" tutto correttamente.
Se il crawler non è in grado di eseguire il rendering della pagina, verrà considerata vuota.
Domande frequenti sui crawler di Google
Quanto tempo impiega Google a eseguire la scansione di un sito web?
Normalmente Google impiega da giorni a settimane per eseguire la scansione. Puoi monitorare la scansione utilizzando il "Rapporto sullo stato dell'indice" o lo "strumento di ispezione URL". Ricorda, Google non viene notificato ogni volta che viene creato un nuovo sito web o una nuova pagina, deve eseguire la scansione e trovarlo.
FYI: I siti più popolari vengono scansionati più velocemente. I siti nuovi di zecca richiederanno solitamente settimane per essere scansionati, mentre i siti rispettabili come NY Times, Wall Street Journal e Wikipedia vengono scansionati più volte al giorno.
Cos'è l'algoritmo del Google Crawler?
L'algoritmo di Google Crawler si basa su quanto il tuo sito sia "amichevole" per i crawler. Questo include "parole chiave", URL, contenuto e informazioni, codifica e molto altro. Sta a te fornire a Google il miglior contenuto e guida in modo che possa trovare la tua pagina e iniziare a eseguire la scansione.
Le pagine sono tutte disponibili per la scansione?
Questa è una buona domanda. La risposta breve è no. Alcune pagine non possono essere scansionate e indicizzate perché sono protette da password, sono state specificamente escluse dalle istruzioni dell'indice o non hanno alcun link sulle loro pagine.
Quando apparirà il mio sito web nella ricerca Google?
Questo varierà sempre a seconda di quanto tempo ci vorrà perché il tuo sito web venga scansionato e indicizzato. Questo potrebbe richiedere solo un paio di giorni o fino a qualche settimana.
Quali altri "web crawler" ci sono?
Sì! Ci sono tonnellate di crawler web oltre ai quindici di Google. Eccone alcuni per riferimento:
- C'è BingBot usato dal motore di ricerca Bing.
- SlurpBot, usato da Yahoo! Questo crawler web è un mix tra Yahoo! e Bing, perché Bing alimenta principalmente Yahoo!.
- ExaBot è il motore di ricerca e crawler più popolare in Francia.
- AppleBot è utilizzato dalla grande azienda tecnologica Apple per la ricerca spotlight e i suggerimenti Siri.
- Facebook, che ci crediate o no, utilizza link per inviare contenuti ad altri profili e può eseguire il crawling solo se viene fornito un link.
Ottimizza il Tuo Sito per la Scansione di Google
Ora che comprendi le basi di Google Crawling e come funziona, usalo a tuo vantaggio! Fai indicizzare correttamente il tuo sito web e scala la vetta della homepage dei risultati di ricerca. È gratuito e completamente a tua disposizione.